そう言えば3年前にこんなまとめ的エントリを書いたのでした。この内容はそのままかなりの部分が2年前に刊行した拙著の原案にもなったということで、色々思い出深いエントリです。
なのですが。・・・この3年の間に統計学・機械学習・データマイニングの諸手法及びそれを取り巻くビジネスニーズには様々な進歩があり、そろそろこの内容にも陳腐化が目立つようになってきました。ということで、3年間の進歩を反映してアップデートした記事を書いてみようと思います。前回は「10選」でしたが、今回は「10+2選」に改めました。そのラインナップは以下の通り。
- 統計学的検定(t検定・カイ二乗検定・ANOVAなど)
- 重回帰分析(線形回帰モデル)
- 一般化線形モデル(GLM:ロジスティック回帰・ポアソン回帰など)
- ランダムフォレスト
- Xgboost(勾配ブースティング木)
- Deep Learning
- MCMCによるベイジアンモデリング
- word2vec
- K-meansクラスタリング
- グラフ理論・ネットワーク分析
- その他の有用な手法たち
- 統計学・機械学習の諸手法について学ぶ上で確認しておきたいポイント
- 最後に
- 追記
前回よりだいぶ組み替わりましたが、それだけ実務の現場で用いられるデータ分析手法の領域が広がったということかなと勝手に考えております(笑)。また、利用するパッケージ・ライブラリの都合上今回はRだけではなくPythonのものも含めています*1。ただし基本的にはR上での実行例を紹介していく感じです。
一方、「補」をつけた2手法についてはデータ分析業界では広く使われているものの僕が普段実践していない手法であるため、そこだけは基本的には他の資料を参照しながらの紹介に留めています。ということで、以下ざっくり見ていきましょう。
Disclaimer
- 今回も基本的には「ひとつの記事で大雑把に眺めたい」人向けの記事なので、ちょこちょこ細かいところで厳密性を欠いていたり、説明不足だったり、はたまた他に必要な資料の提示が欠けているところもあるかと思いますので、その辺は何卒ご容赦を。またスクラッチからの実装に必要な知識を提供するものでもありませんので、どうか悪しからず
- 今回の記事ではそれぞれのデータ分析手法を紹介することに主眼を置いているので、個々のパッケージ・ライブラリ類及びそれらのビルドに必要なコンパイラ環境などのインストール方法などの詳細はほぼ割愛しております。インストールに際しては適宜リンク先の記事を参照するなり、ググるなりしてください
- ただし、明らかに理論的に誤っている説明などがある場合は直ちに修正いたしますので、コメント欄なりSNS上でのコメントなりでTJOまで是非お知らせください
統計学的検定(t検定・カイ二乗検定・ANOVAなど)
意外と多くの現場で根強い人気を誇るのが、極めて古典的で頻度主義的な「統計学的検定」。要するに「A/Bテスト」を初めとして「何かと何かを比較したい場合」にその比較結果を統計学的にはっきりさせたい時に使う方法論です。[twitter:@KuboBook]先生も仰るように実際には検定一辺倒で行くよりは統計モデリングとかにシフトする方がより表現力が高くて良いのですが、今でもビジネスの現場では様々な意思決定のサポートを目的として多用されているようです。ここでは3つの例を挙げます。
t検定
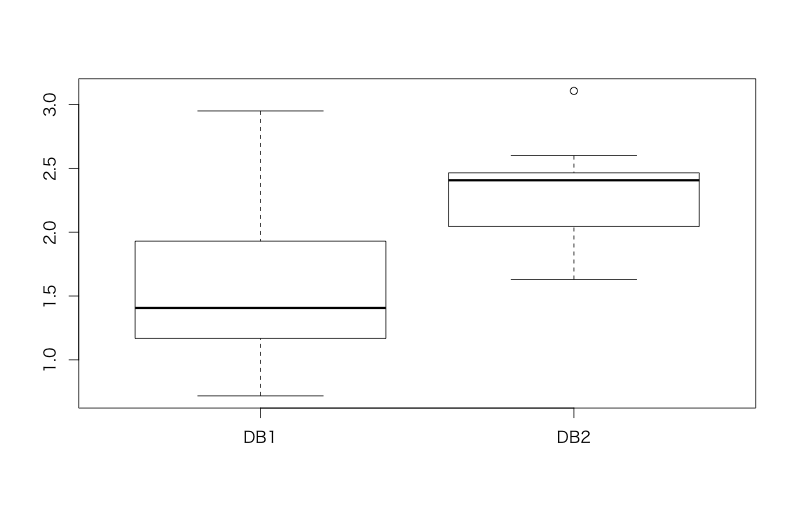
基本的には「平均値同士で差があるかどうかを比較したい場合」に使います。以前拙著で用いたサンプルデータセットで試してみましょう。想定としては「あるデータベース基盤2種類の間で特定のクエリのレイテンシ同士を比較して、どちらがより高速かを明らかにしたい」というケースです。
> d<-read.csv('https://raw.githubusercontent.com/ozt-ca/tjo.hatenablog.samples/master/r_samples/public_lib/DM_sampledata/ch3_2_2.txt',header=T,sep=' ') > head(d) DB1 DB2 1 0.9477293 2.465692 2 1.4046824 2.132022 3 1.4064391 2.599804 4 1.8396669 2.366184 5 1.3265343 1.804903 6 2.3114898 2.449027 > boxplot(d) # 箱ひげ図(下を参照)をプロットする > t.test(d$DB1,d$DB2) # t検定はt.test関数で Welch Two Sample t-test data: d$DB1 and d$DB2 t = -3.9165, df = 22.914, p-value = 0.0006957 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -1.0998402 -0.3394647 sample estimates: mean of x mean of y 1.575080 2.294733 # 等分散性を仮定しないWelchの検定が自動的に適用される
カイ二乗検定
ビジネスシーンにありがちなパターンとしては、「施策の有無で「○○率」に差があるかどうか比較したい場合」に使える統計学的検定です。例えばあるスマホアプリの動線改善を行う前と行った後とで、CV数が以下のように変わったと想定しましょう。
| CVした | CVしなかった | |
|---|---|---|
| 改善前 | 25 | 117 |
| 改善後 | 16 | 32 |
このように「既に集計された(tabulated)データ同士でその『率』を比較したい場合」は、t検定のように生データもしくは平均と標準偏差からデータ同士のばらつきを踏まえて比較する方法は使えず、代わりに元のデータ同士が同じ分布に基づくかどうかを比べるカイ二乗検定(独立性の検定)が定番です。Rでは以下のように実行できます。
> d<-matrix(c(25,117,16,32),ncol=2,byrow=T) > chisq.test(d) # chisq.test関数でカイ二乗検定 Pearson's Chi-squared test with Yates' continuity correction data: d X-squared = 4.3556, df = 1, p-value = 0.03689
こちらもp < 0.05ということで、動線改善によるCV増加の効果があったとみなして良さそうです。なお「同じ施策を行ったと仮定できる」複数のデータセットごとにカイ二乗検定を行った結果を統合するには、以下の記事で紹介したメタアナリシスの手法が使えます。
これに限らず、統計学的検定の多くの手法が同様にメタアナリシスの方法論に基づいて「複数の結果を統合する」ことが可能なので、知っておいて損はないです。
ANOVA(分散分析)
色々なパターンがあり得ますが、基本的には「3つ以上のデータ同士で2つ以上の施策を打ち分けた時に差があるかどうか比較したい場合」に用いる手法です。厳密にはやや異なりますが、アイデアとしてはt検定を3つ以上のデータ同士に拡張したのとほぼ同じ考え方です。ただし取り組み方としてはこの後に出てくる重回帰分析(正規線形モデル)とほぼ同じなので、特に施策の効果が「正か負か」を知りたいケースではむしろ重回帰分析に替えた方が良いことが多いかなと。
例えば、「ある2つのカテゴリの商品を取り扱う対面販売コーナーで2通りのプロモーションを打ち分けて4日間に渡って販売した時に、プロモーションのやり方によって売上個数が変わるかどうか」*3を知りたいとしましょう。この場合、変数prにプロモーションの有無を、変数categoryに商品カテゴリを表すカテゴリ変数を入れて、売上個数を変数cntとした時、以下のような感じでANOVAで計算できます。
> d<-data.frame(cnt=c(210,435,130,720,320,470,250,380,290,505,180,320,310,390,410,510),pr=c(rep(c('F','Y'),8)),category=rep(c('a','a','b','b'),4)) > d.aov<-aov(cnt~.^2,d) # ANOVAはaov関数で計算する > summary(d.aov) Df Sum Sq Mean Sq F value Pr(>F) pr 1 166056 166056 12.984 0.00362 ** category 1 56 56 0.004 0.94822 pr:category 1 5256 5256 0.411 0.53353 Residuals 12 153475 12790 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
プロモーションが異なれば売上個数も変わるとみなして良さそうです。一方で商品カテゴリ間での差はなく、なおかつ商品カテゴリが変わった場合にプロモーションの効果に違いが出ることもなさそうです(交互作用が有意でないため)。
重回帰分析(線形回帰モデル)
これまた基本の「き」みたいな手法であるにもかかわらず、特にビジネスサイドの実務の現場では意外とまだ今でも広まっていない手法の代表格ですね*4。その実践例として、拙著でも用いた「ある地域でのビールの売上高をモデリングする」例題をやってみましょう。
ここでは目的変数Revenue(その地域でのビールの売上高)を、説明変数であるCM(TVCMが放映されたボリューム)、Temp(気温)、Firework(その地域での花火大会の有無)で重回帰分析でモデリングすることを考えます。
> d<-read.csv('https://raw.githubusercontent.com/ozt-ca/tjo.hatenablog.samples/master/r_samples/public_lib/DM_sampledata/ch4_3_2.txt',header=T,sep=' ') > head(d) Revenue CM Temp Firework 1 47.14347 141 31 2 2 36.92363 144 23 1 3 38.92102 155 32 0 4 40.46434 130 28 0 5 51.60783 161 37 0 6 32.87875 154 27 0 > d.lm<-lm(Revenue~.,d) # 線形回帰モデルはlm関数 > summary(d.lm) Call: lm(formula = Revenue ~ ., data = d) Residuals: Min 1Q Median 3Q Max -6.028 -3.038 -0.009 2.097 8.141 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 17.23377 12.40527 1.389 0.17655 CM -0.04284 0.07768 -0.551 0.58602 Temp 0.98716 0.17945 5.501 9e-06 *** Firework 3.18159 0.95993 3.314 0.00271 ** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 3.981 on 26 degrees of freedom Multiple R-squared: 0.6264, Adjusted R-squared: 0.5833 F-statistic: 14.53 on 3 and 26 DF, p-value: 9.342e-06 # 以下プロット > matplot(cbind(d$Revenue,predict(d.lm,newdata=d[,-1])),type='l',lwd=c(2,3),lty=1,col=c(1,2)) > legend('topleft',legend=c('Data','Predicted'),lwd=c(2,3),lty=1,col=c(1,2),ncol=1)
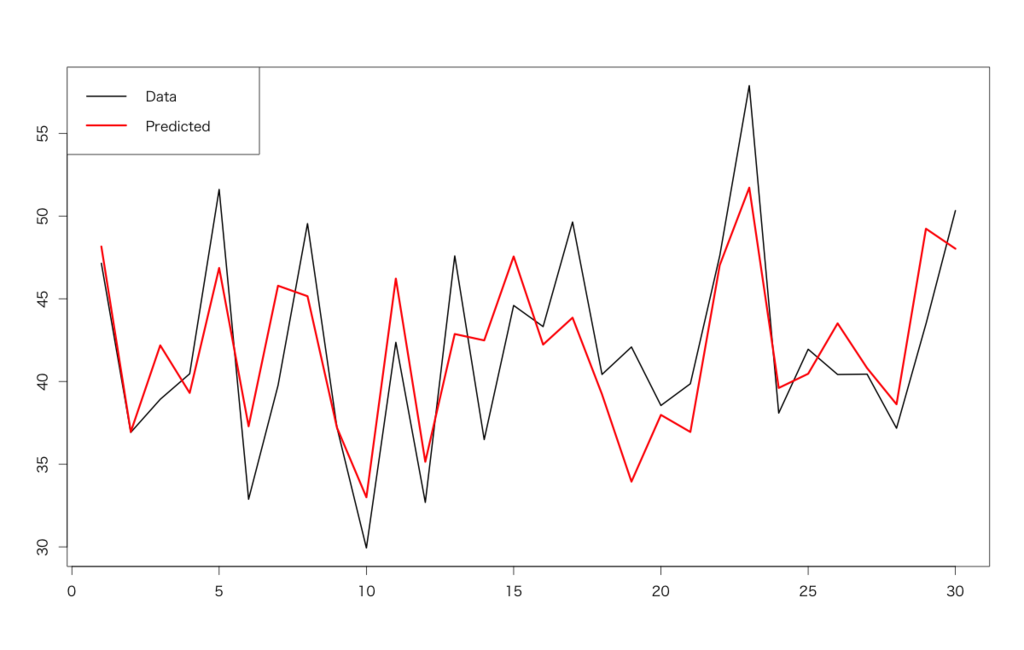
気温と花火大会の開催の有無が重要らしい(そしてTVCMはあまり関係ない)ことが分かりました。仮に未来の説明変数の値が分かる場合(TVCMは計画値があるし気温も天気予報などの形で入手可能)、predictメソッドで未来の売上高を予測することも可能です。なお、以前slideshareで公開したスライドでも書きましたが、重回帰分析も含めた線形モデルファミリー全般の考え方を図示したものがこちら。
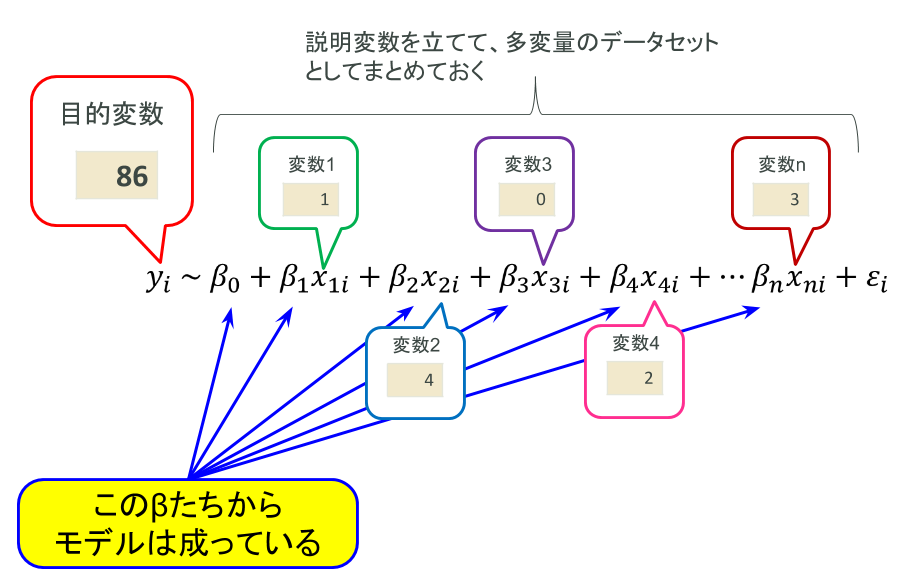
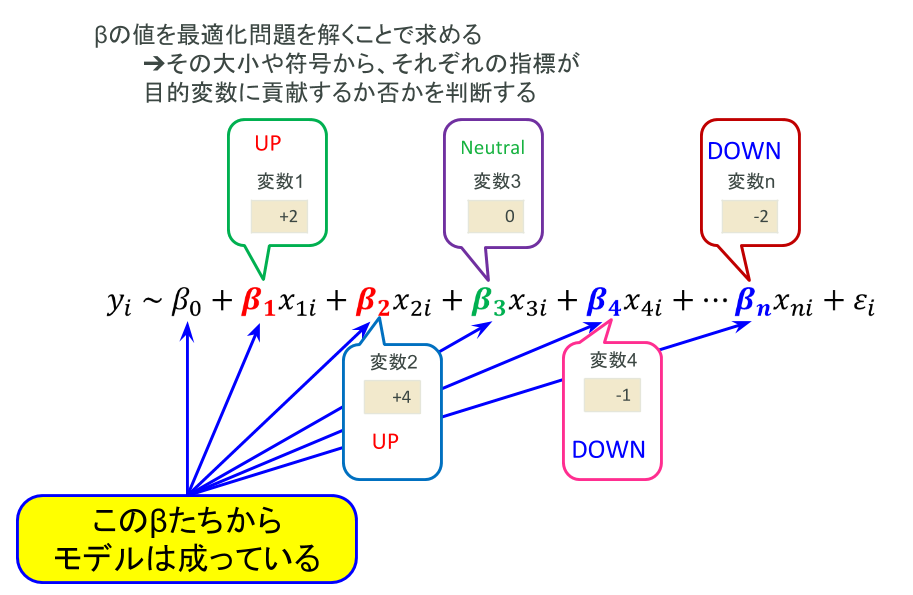
要は、ある目的変数を説明変数の線形和で表現するようなモデルを最適化計画によって求める、というのが根本的な発想です。これはその他の多くの統計モデリングおよび機械学習においても共通している概念ですので、覚えておくと良いでしょう。
(※ちなみに、線形回帰モデルは機械学習の分野においても基本の「き」として取り上げられることが多く、かの「黄色い本」ことPRMLはじめ多くのテキストでアルゴリズムをスクラッチから実装する際の題材としても紹介されています。一般には行列式をサクサク解けばそれでおしまいという代物ですが、あえて最急降下法でパラメータ推定するコードをPythonあたりで書いて挙動を知るというのも良い勉強になるかと思います)
一般化線形モデル(GLM:ロジスティック回帰・ポアソン回帰など)
ここから統計学と機械学習の境界ゾーンにして、同時に統計モデリングの醍醐味みたいなゾーンに入っていきます。基本的な発想は重回帰分析(線形モデル)と同じですが、一つ違うのは線形モデルは目的変数が「正規分布に従う」と仮定しているのに対し、一般化線形モデルでは目的変数がどのような分布に従うかによってモデルの立て方を変える必要がある点です。それゆえ、目的変数が従う分布の名前を冠して例えば「ポアソン回帰」「負の二項分布回帰」といった呼び方をすることがあります。
ロジスティック回帰
これは二値分類であることから機械学習分野においても重要な初歩として扱われる手法です。分布という点では二項分布に従う一般化線形モデルです。以前の記事でも簡単に取り上げたことがあります。
ここでは拙著6章のデータを使います。d21-d26までの6つのプロモーションページを用意したECサイトにおいて、どのページを訪問したorしないかがCVにより寄与するかを調べたい、というシナリオです。
> d<-read.csv('https://raw.githubusercontent.com/ozt-ca/tjo.hatenablog.samples/master/r_samples/public_lib/DM_sampledata/ch6_4_2.txt',header=T,sep=' ') > d$cv<-as.factor(d$cv) # 目的変数をカテゴリ型に直す > d.glm<-glm(cv~.,d,family=binomial) # GLMはglm関数にfamily引数で分布を指定 > summary(d.glm) Call: glm(formula = cv ~ ., family = binomial, data = d) Deviance Residuals: Min 1Q Median 3Q Max -2.3793 -0.3138 -0.2614 0.4173 2.4641 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) -1.0120 0.9950 -1.017 0.3091 d21 2.0566 0.8678 2.370 0.0178 * d22 -1.7610 0.7464 -2.359 0.0183 * d23 -0.2136 0.6131 -0.348 0.7276 d24 0.2994 0.8368 0.358 0.7205 d25 -0.3726 0.6064 -0.614 0.5390 d26 1.4258 0.6408 2.225 0.0261 * --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 (Dispersion parameter for binomial family taken to be 1) Null deviance: 173.279 on 124 degrees of freedom Residual deviance: 77.167 on 118 degrees of freedom AIC: 91.167 Number of Fisher Scoring iterations: 5
d21ページが最も良さそうで、逆にd22は避けた方が良さそうだということが見て取れます。こちらのモデルも線形回帰モデル同様にpredictメソッドで未知データの説明変数が与えられさえすれば目的変数を予測することも可能です。
ポアソン回帰
一方、こちらはどちらかというと純然たる統計学の領域の話で、目的変数がポアソン分布に従う場合に用いられる一般化線形モデルです。ポアソン分布でググると色々な説明が出てきますが、基本的には「何かの母集団があってその中から稀に発生する現象の『回数』が従う確率分布」*5と思えば大丈夫です。例えばこんな感じの分布形状であればポアソン分布の可能性が高いです。
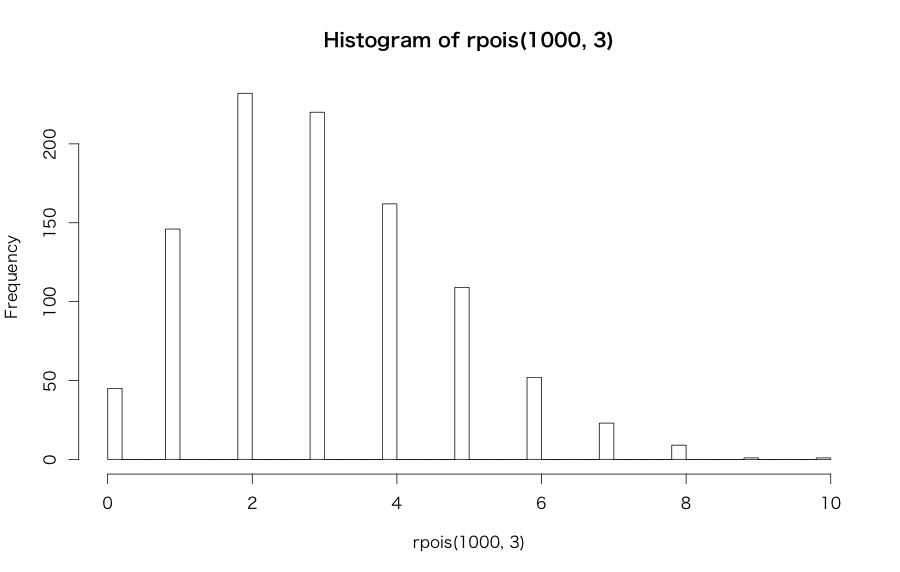
ビジネス実務だと「1日当たりの総サイト訪問者数に占めるCVユーザー数」などは(分母を勘案するという条件下で)ポアソン分布に従うデータの代表例ですね*6。ちなみに以前の記事でポアソン回帰を含めた一般化線形モデル全般について色々考察したことがあるので、よろしければこちらもどうぞ。
ところで例題ですが、こちらは手頃なデータがないのでRのhelpに載っている例をそのまま使うことにします。Dobsonの1990年の著書"An Introduction to Generalized Linear Models"に掲載されている何かの疫学調査に関するデータのようですが、本書未読につき詳細は分かりませんごめんなさい。。。
> ## Dobson (1990) Page 93: Randomized Controlled Trial : > counts <- c(18,17,15,20,10,20,25,13,12) > outcome <- gl(3,1,9) > treatment <- gl(3,3) > print(d.AD <- data.frame(treatment, outcome, counts)) treatment outcome counts 1 1 1 18 2 1 2 17 3 1 3 15 4 2 1 20 5 2 2 10 6 2 3 20 7 3 1 25 8 3 2 13 9 3 3 12 > glm.D93 <- glm(counts ~ outcome + treatment, family = poisson) # family引数にpoissonを指定することでポアソン回帰 > summary(glm.D93) Call: glm(formula = counts ~ outcome + treatment, family = poisson) Deviance Residuals: 1 2 3 4 5 6 7 8 9 -0.67125 0.96272 -0.16965 -0.21999 -0.95552 1.04939 0.84715 -0.09167 -0.96656 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) 3.045e+00 1.709e-01 17.815 <2e-16 *** outcome2 -4.543e-01 2.022e-01 -2.247 0.0246 * outcome3 -2.930e-01 1.927e-01 -1.520 0.1285 treatment2 1.338e-15 2.000e-01 0.000 1.0000 treatment3 1.421e-15 2.000e-01 0.000 1.0000 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 (Dispersion parameter for poisson family taken to be 1) Null deviance: 10.5814 on 8 degrees of freedom Residual deviance: 5.1291 on 4 degrees of freedom AIC: 56.761 Number of Fisher Scoring iterations: 4 # AICでモデルの汎化性能を、Residual devianceとdegrees of freedomとの比率からoverdispersionかどうかをチェックする > hist(counts,breaks=50) # ヒストグラムをプロット
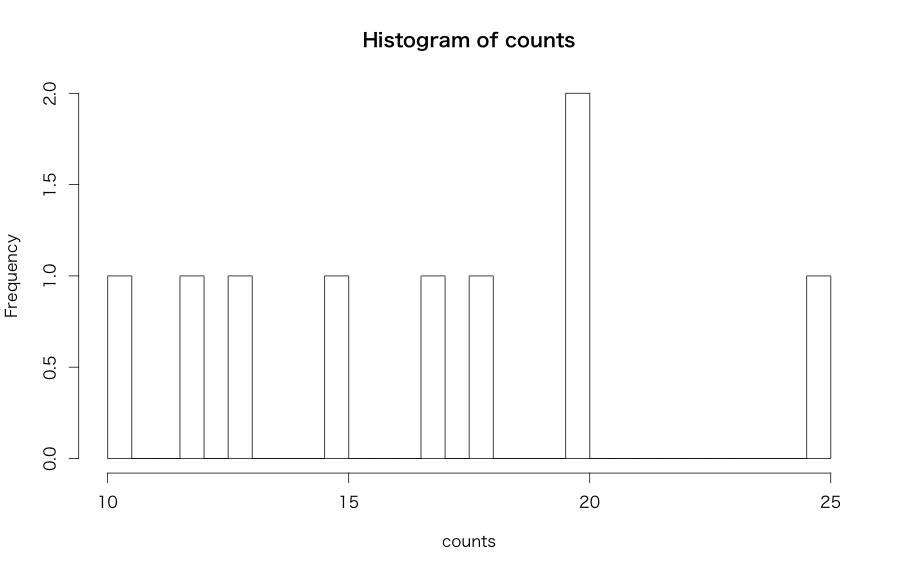
outcome2が重要だということになりました。なお、上記過去記事にもあるようにポアソン回帰は目的変数に0がやたら多い場合はうまくフィッティングしないので、その時は負の二項分布に基づくGLMを用いる必要があります。Rだと{VGAM}パッケージのglm.nb関数で計算できます。
正則化(L1 / L2ノルム)
この辺から機械学習の要素が段々増えてきます。その第一歩として取り上げるのが、この「正則化」。
あるモデルが過去のデータにばかり当てはまりが良いだけでなく未知のデータに対してもある程度きちんと当てはまる度合いのことを「汎化性能(能力)」と呼びますが、この汎化性能を向上させるという点で重要なのが「正則化」という手法です。詳細はこちらの過去記事をお読み下さい。平たく言えば「パラメータを推定する際に制約条件を嵌めることで、必要以上に過去データのノイズにフィットしないようにする」工夫かな、と。
特に機械学習において大事なのは「学習データと(モデルの性能評価のための)テストデータは必ず別に分ける」(交差検証:cross validation)ということ。これをやらないと、学習データのノイズにもフィットしてしまうようなモデルばかりが見かけ上の性能が良く見えてしまうということになりかねないので、徹底しましょう*7。
ということで、このブログで何度か例題として挙げている男女テニス四大大会のデータセットを使ってみようと思います。男子のデータを学習データとし、女子のデータの勝敗を予測するという交差検証の建て付けでやってみましょう。ここでは例として「不要な説明変数を削る」タイプのL1正則化(Lasso回帰)を実践してみます。「全体を調整する」タイプのL2正則化(Ridge回帰)はスペースの都合もあるのでここでは割愛ということで。
> dm<-read.csv('https://github.com/ozt-ca/tjo.hatenablog.samples/raw/master/r_samples/public_lib/jp/exp_uci_datasets/tennis/men.txt',header=T,sep='\t') > dw<-read.csv('https://github.com/ozt-ca/tjo.hatenablog.samples/raw/master/r_samples/public_lib/jp/exp_uci_datasets/tennis/women.txt',header=T,sep='\t') > dm<-dm[,-c(1,2,16,17,18,19,20,21,34,35,36,37,38,39)] > dw<-dw[,-c(1,2,16,17,18,19,20,21,34,35,36,37,38,39)] # L1正則化 > library(glmnet) > dm.cv.glmnet<-cv.glmnet(as.matrix(dm[,-1]),as.matrix(dm[,1]),family="binomial",alpha=1) # alpha=1でL1正則化、alpha=0でL2正則化、その間ならelastic net # cv.glmnet関数は交差検証によってパラメータの最適値の探索も同時にやってくれる > plot(dm.cv.glmnet) > coef(dm.cv.glmnet,s=dm.cv.glmnet$lambda.min) # s引数に探索したパラメータの最適値を入れる 25 x 1 sparse Matrix of class "dgCMatrix" 1 (Intercept) 3.533402e-01 FSP.1 3.805604e-02 FSW.1 1.179697e-01 SSP.1 -3.275595e-05 SSW.1 1.475791e-01 ACE.1 . DBF.1 -8.934231e-02 WNR.1 3.628403e-02 UFE.1 -7.839983e-03 BPC.1 3.758665e-01 BPW.1 2.064167e-01 NPA.1 . NPW.1 . FSP.2 -2.924528e-02 FSW.2 -1.568441e-01 SSP.2 . SSW.2 -1.324209e-01 ACE.2 1.233763e-02 DBF.2 4.032510e-02 WNR.2 -2.071361e-02 UFE.2 -6.114823e-06 BPC.2 -3.648171e-01 BPW.2 -1.985184e-01 NPA.2 . NPW.2 1.340329e-02 > table(dw$Result,round(predict(dm.cv.glmnet,as.matrix(dw[,-1]),s=dm.cv.glmnet$lambda.min,type='response'),0)) 0 1 0 215 12 1 18 207 > sum(diag(table(dw$Result,round(predict(dm.cv.glmnet,as.matrix(dw[,-1]),s=dm.cv.glmnet$lambda.min,type='response'),0))))/nrow(dw) [1] 0.9336283 # 正答率93.4% # 比較:普通のロジスティック回帰の場合 > dm.glm<-glm(Result~.,dm,family=binomial) > table(dw$Result,round(predict(dm.glm,newdata=dw[,-1],type='response'))) 0 1 0 211 16 1 17 208 > sum(diag(table(dw$Result,round(predict(dm.glm,newdata=dw[,-1],type='response')))))/nrow(dw) [1] 0.9269912 # 正答率92.7%
確かに、L1正則化で不要なパラメータを削った時の方が、普通のロジスティック回帰の時よりも、テストデータの予測正答率で上回っています。それだけ「汎化性能」が改善したということが言えるわけです。
その他のGLM
基本的にはRのglm関数のfamily引数に出てくるものを覚えておけば、実用上は問題はないかと思います。あえて言えば例えばquasi-poissonを使うべきか、glm.nbを使うべきかみたいに微妙なところで迷うケースはあるかもしれませんが、そういう時は個々のケースごとにまた改めて勉強すれば事足りるかと。
ランダムフォレスト
さぁ、ここからはガッチガチの機械学習の出番。トップバッターは、割と色々な機械学習ベースの本番環境でも多用されているランダムフォレスト。今やbagging型のアンサンブル学習の代表格ということで、あまりにも多くの言語によってライブラリ実装が作られ、世界中で使われています。その中身についてですが、過去に記事を書いたことがありますのでよろしければそちらをお読みください。
ということで、これまた機械学習の例題ではド定番のMNIST手書き文字認識データセットを使ってランダムフォレストの性能を見てみましょう。オリジナルデータは非常に重いため、代わりに学習データ5000行、テストデータ1000行にダウンサンプリングしたショートバージョンを僕のGitHubリポジトリに置いておきましたので、そちらを使います。
> train<-read.csv('https://github.com/ozt-ca/tjo.hatenablog.samples/raw/master/r_samples/public_lib/jp/mnist_reproduced/short_prac_train.csv') > test<-read.csv('https://github.com/ozt-ca/tjo.hatenablog.samples/raw/master/r_samples/public_lib/jp/mnist_reproduced/short_prac_test.csv') > train$label<-as.factor(train$label) > test$label<-as.factor(test$label) > library(randomForest) > train.rf<-randomForest(label~.,train) > table(test$label,predict(train.rf,newdata=test[,-1])) 0 1 2 3 4 5 6 7 8 9 0 96 0 0 0 0 0 3 0 1 0 1 0 99 0 0 0 0 0 0 1 0 2 0 0 96 1 1 0 1 1 0 0 3 0 0 2 87 0 4 1 1 3 2 4 0 0 0 0 96 0 1 0 0 3 5 1 2 0 1 0 94 2 0 0 0 6 0 0 1 0 1 2 95 0 1 0 7 0 2 0 0 1 0 0 93 0 4 8 0 0 1 0 0 0 0 0 99 0 9 0 0 0 0 2 1 0 1 0 96 > sum(diag(table(test$label,predict(train.rf,newdata=test[,-1]))))/nrow(test) [1] 0.951 # 95.1%の正答率
ランダムフォレストでは95.1%の正答率を達成することができました。ちなみにKaggleのMNISTコンペでもベンチマークとして全く同じRの{randomForest}パッケージを用いたコード例が与えられています。
そうそう、興味のある方はMNIST手書き文字を描画するのも良いかもしれません。Rでは面倒ですがこんな感じでプロットできます。
> par(mfrow=c(3,4)) > for(i in 1:10){ + image(t(apply(matrix(as.vector(as.matrix(train[(i-1)*500+50,-1])),ncol=28,nrow=28,byrow=T),2,rev)),col=grey(seq(0,1,length.out=256))) + }
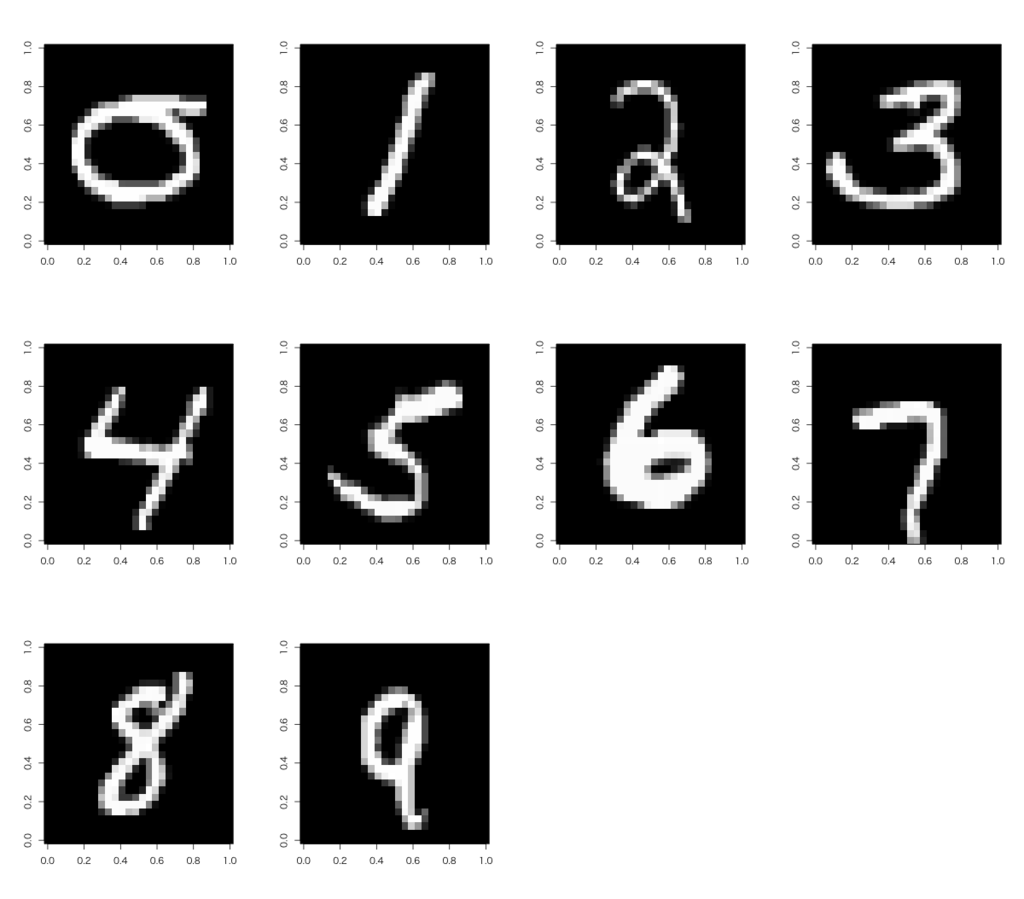
結構皆さん字が汚いようで(笑)、中にはヒトの目で見ても判別がつかない(振られている正解ラベルを見て初めて分かる)というレベルの汚い字もあったりします。それでも機械学習で分類してみせる!というのがこのMNISTコンペの醍醐味なのだとか。
Xgboost(勾配ブースティング木)
一方で、近年KaggleやKDD Cupなどのコンペでにわかに注目を集めているのがxgboost。これは従来から知られていた勾配ブースティング木(gradient boodted trees)をより高速な実装にしたライブラリですが、あまりにも各種コンペで圧倒的なパフォーマンスを叩き出すため猛烈な勢いで世界中に広まりつつあります。余談ですが、おかげさまで英語版ブログのxgboostの記事は英語限定で'xgboost'でググった時に上から2〜3番目に出てきます(笑)。なお、その中身については過去記事で一度解説したことがありますので、よろしければそちらをどうぞ。
ということで、ランダムフォレストの時と同様にMNISTのショートバージョンで試してみます。ちなみに下記の結果はそれ相応にチューニングした後の帰結である旨悪しからずご了承ください(笑)。
> train<-read.csv('https://github.com/ozt-ca/tjo.hatenablog.samples/raw/master/r_samples/public_lib/jp/mnist_reproduced/short_prac_train.csv') > test<-read.csv('https://github.com/ozt-ca/tjo.hatenablog.samples/raw/master/r_samples/public_lib/jp/mnist_reproduced/short_prac_test.csv') > library(xgboost) > library(Matrix) # データの前処理に必要 > train.mx<-sparse.model.matrix(label~., train) > test.mx<-sparse.model.matrix(label~., test) # データセットをxgboostで扱える形式に直す > dtrain<-xgb.DMatrix(train.mx, label=train$label) > dtest<-xgb.DMatrix(test.mx, label=test$label) # 色々パラメータがあるがxgboostのGitHubなどを参照のこと > train.gbdt<-xgb.train(params=list(objective="multi:softmax", num_class=10, eval_metric="mlogloss", eta=0.3, max_depth=5, subsample=1, colsample_bytree=0.5), data=dtrain, nrounds=70, watchlist=list(train=dtrain,test=dtest)) [0] train-mlogloss:1.439942 test-mlogloss:1.488160 [1] train-mlogloss:1.083675 test-mlogloss:1.177975 [2] train-mlogloss:0.854107 test-mlogloss:0.977648 # ... omitted ... [67] train-mlogloss:0.004172 test-mlogloss:0.176068 [68] train-mlogloss:0.004088 test-mlogloss:0.176044 [69] train-mlogloss:0.004010 test-mlogloss:0.176004 > table(test$label,predict(train.gbdt,newdata=dtest)) 0 1 2 3 4 5 6 7 8 9 0 95 0 0 1 0 0 3 0 1 0 1 0 99 0 0 0 0 0 1 0 0 2 0 0 96 2 0 0 1 1 0 0 3 0 0 1 93 0 0 0 1 2 3 4 0 0 1 1 95 0 1 0 0 2 5 0 1 0 1 0 98 0 0 0 0 6 0 0 1 0 1 2 95 0 1 0 7 0 0 0 0 1 0 0 96 0 3 8 0 4 1 0 1 0 0 0 93 1 9 0 0 0 0 4 1 0 2 0 93 > sum(diag(table(test$label,predict(train.gbdt,newdata=dtest))))/nrow(test) [1] 0.953 # 正答率95.3%
95.3%ということで、xgboostでランダムフォレストを上回ることが出来ました。ただしランダムフォレストよりもパラメータチューニングに依存する部分が結構大きいので、思ったほど精度が出ないケースもままある点には注意が必要です。ランダムシードに依存する部分もあります*8。
Deep Learning
今や「人工知能」の代名詞にもなりつつあるDeep Learning。当初Deep Neural Network (DNN)だけだったものが、画像認識に重宝されるConvolutional Neural Network (CNN)、文章や音声など系列データに強いRecurrent Neural Network (RNN)などどんどんその派生形が広まりつつあります。
ということで現在のところ初期の実装ライブラリだったTheano, PyLearn2に比べてTorch, Caffe, ChainerそしてTensorFlow, CNTKと非常に多彩な実装が各所から提供されているおかげで(特に)C++, Python環境でかつGPU環境が用意できればかなりお手軽にDeep Learningを導入・実践することができます。それらの実装に関する解説、さらには理論に関する解説もググれば山ほど出てきますので、この記事では割愛します。2014年のJapan.Rで僕が話したDeep Learningに関する簡単なトークもあると言えばありますが、既に現在のトレンドからだいぶ置き去りにされているのであくまでも参考程度に。。。
そして今回はプロ並みの実装を試すという趣旨でもないので、現状最もRからの実行が簡単なH2OのRパッケージ{h2o}を用いた簡便なDNNの実践例のみ紹介します。こちらもMNISTのショートバージョンでやってみましょう。
(※どうやらH2Oの実装全体が最近のアップデートでかなりの改変があったようで、以前の記事のコードでは動かないようになっています。こちらが2016年3月現在動くコードですので、まずはこちらをお試しください)
> train<-read.csv('https://github.com/ozt-ca/tjo.hatenablog.samples/raw/master/r_samples/public_lib/jp/mnist_reproduced/short_prac_train.csv') > test<-read.csv('https://github.com/ozt-ca/tjo.hatenablog.samples/raw/master/r_samples/public_lib/jp/mnist_reproduced/short_prac_test.csv') > train$label<-as.factor(train$label) > test$label<-as.factor(test$label) > library(h2o) # Java VMのインスタンスを立てる > localH2O <- h2o.init(ip = "localhost", port = 54321, startH2O = TRUE, nthreads=3) # 現行バージョンではas.h2o関数でRオブジェクトを直接読み込める > trData<-as.h2o(train) > tsData<-as.h2o(test) # 以下最適化周りのパラメータ指定が山ほど並んでいるので、Deep Learningの専門書などを参照のこと > res.dl <- h2o.deeplearning(x = 2:785, y = 1, training_frame = trData, activation = "RectifierWithDropout",hidden=c(1024,1024,2048),epochs = 300, adaptive_rate = FALSE, rate=0.01, rate_annealing = 1.0e-6,rate_decay = 1.0, momentum_start = 0.5,momentum_ramp = 5000*18, momentum_stable = 0.99, input_dropout_ratio = 0.2,l1 = 1.0e-5,l2 = 0.0,max_w2 = 15.0, initial_weight_distribution = "Normal",initial_weight_scale = 0.01,nesterov_accelerated_gradient = T, loss = "CrossEntropy", fast_mode = T, diagnostics = T, ignore_const_cols = T,force_load_balance = T) > pred<-h2o.predict(res.dl,tsData[,-1]) > pred.df<-as.data.frame(pred) > table(test$label,pred.df[,1]) 0 1 2 3 4 5 6 7 8 9 0 96 0 1 0 0 0 2 1 0 0 1 0 100 0 0 0 0 0 0 0 0 2 0 0 97 0 2 0 0 1 0 0 3 0 0 1 93 0 4 0 1 0 1 4 0 2 1 0 93 0 0 1 1 2 5 0 0 0 1 0 99 0 0 0 0 6 1 0 0 0 0 2 97 0 0 0 7 0 0 0 0 1 0 0 96 0 3 8 0 0 1 1 1 2 0 0 95 0 9 0 0 0 0 2 0 0 2 0 96 > sum(diag(table(test$label,pred.df[,1])))/nrow(test) [1] 0.962 # 正答率96.2%
流石にDeep LearningというかDNNの面目を保って、96.2%とハイスコアを叩き出しました*9。ちなみにこのDNNは中間層が1024, 1024, 2048ユニットから成り、活性化関数は'Rectifier'*10、そしてdropout ratioを正則化効果最大の0.5に固定した5層ネットワークです。
追記:MXnetのRパッケージ{mxnet}を用いたConvolutional Neural Networkによる例
後の記事で取り上げた方法によるものです。詳細はそちらをご参照ください。
# Installation > install.packages("drat", repos="https://cran.rstudio.com") > drat:::addRepo("dmlc") > install.packages("mxnet") > library(mxnet) # Data preparation > train<-read.csv('https://github.com/ozt-ca/tjo.hatenablog.samples/raw/master/r_samples/public_lib/jp/mnist_reproduced/short_prac_train.csv') > test<-read.csv('https://github.com/ozt-ca/tjo.hatenablog.samples/raw/master/r_samples/public_lib/jp/mnist_reproduced/short_prac_test.csv') > train<-data.matrix(train) > test<-data.matrix(test) > train.x<-train[,-1] > train.y<-train[,1] > train.x<-t(train.x/255) > test_org<-test > test<-test[,-1] > test<-t(test/255) > devices <- mx.cpu() > mx.set.seed(0) > data <- mx.symbol.Variable("data") > # first conv > conv1 <- mx.symbol.Convolution(data=data, kernel=c(5,5), num_filter=20) > tanh1 <- mx.symbol.Activation(data=conv1, act_type="relu") > pool1 <- mx.symbol.Pooling(data=tanh1, pool_type="max", + kernel=c(2,2), stride=c(2,2)) > drop1 <- mx.symbol.Dropout(data=pool1,p=0.5) > # second conv > conv2 <- mx.symbol.Convolution(data=drop1, kernel=c(5,5), num_filter=50) > tanh2 <- mx.symbol.Activation(data=conv2, act_type="relu") > pool2 <- mx.symbol.Pooling(data=tanh2, pool_type="max", + kernel=c(2,2), stride=c(2,2)) > drop2 <- mx.symbol.Dropout(data=pool2,p=0.5) > # first fullc > flatten <- mx.symbol.Flatten(data=drop2) > fc1 <- mx.symbol.FullyConnected(data=flatten, num_hidden=500) > tanh4 <- mx.symbol.Activation(data=fc1, act_type="relu") > drop4 <- mx.symbol.Dropout(data=tanh4,p=0.5) > # second fullc > fc2 <- mx.symbol.FullyConnected(data=drop4, num_hidden=10) > # loss > lenet <- mx.symbol.SoftmaxOutput(data=fc2) > train.array <- train.x > dim(train.array) <- c(28, 28, 1, ncol(train.x)) > test.array <- test > dim(test.array) <- c(28, 28, 1, ncol(test)) > mx.set.seed(0) > tic <- proc.time() > model <- mx.model.FeedForward.create(lenet, X=train.array, y=train.y, + ctx=devices, num.round=60, array.batch.size=100, + learning.rate=0.05, momentum=0.9, wd=0.00001, + eval.metric=mx.metric.accuracy, + epoch.end.callback=mx.callback.log.train.metric(100)) Start training with 1 devices [1] Train-accuracy=0.0975510204081633 # omitted # [60] Train-accuracy=0.9822 > print(proc.time() - tic) ユーザ システム 経過 784.666 3.767 677.921 > preds <- predict(model, test.array, ctx=devices) > pred.label <- max.col(t(preds)) - 1 > table(test_org[,1],pred.label) pred.label 0 1 2 3 4 5 6 7 8 9 0 99 0 0 0 0 0 1 0 0 0 1 0 99 0 0 1 0 0 0 0 0 2 0 0 98 0 0 0 0 1 1 0 3 0 0 0 98 0 1 0 0 1 0 4 0 2 0 0 97 0 1 0 0 0 5 0 0 0 0 0 99 1 0 0 0 6 0 0 0 0 0 0 100 0 0 0 7 0 0 0 0 0 0 0 99 1 0 8 0 0 0 0 0 0 0 0 100 0 9 0 0 0 0 2 0 0 0 0 98 > sum(diag(table(test_org[,1],pred.label)))/1000 [1] 0.987 # 正答率98.7%
活性化関数にReLUを選択し、畳み込み層を2層、全結合層を2層、出力をsoftmax関数にしたいわゆるLeNetで、98.7%とおそらくこのサンプルサイズではほぼ限界に近い精度が出ています。さすがCNNといったところでしょうか。
MCMCによるベイジアンモデリング
僕も刊行委員として参画している岩波DS第1巻でも特集されていましたが、MCMCを用いたベイジアンモデリングは通常の*11線形回帰モデル、一般化線形モデルでは歯が立たないような複雑なモデルを扱うのに適しています。
ところで、かつてはBUGSでの実践が一般的でしたが、実行速度が比較的遅いこと、そして何よりも現在は開発が止まっているために最先端の理論や実装が反映されないなどの問題がありました。現在はJAGSそしてStanという高速な実装が容易に入手できるため、こちらを薦められることの方が多いようです。このブログの過去の記事でもシリーズとして取り上げています。
ということでここでは簡単なStanの実行例を挙げておきます。以前の記事で用いたサンプルデータセットを少し改変したものに対して、季節調整+二階差分トレンドモデルでパラメータ推定を行った上で、フィッティングした結果を合わせたものです。イメージとしては「広告を3種類毎日投下量を変えながら投下していった場合のCV数をモデリングする」というものです。日次データなので、曜日変動や広告とは無関係な「うねり」のようなものを含むデータで、これをモデリングするという按配です。以下Stanコード、Rコードの順に挙げてあります。
data {
int<lower=0> N;
real<lower=0> x1[N];
real<lower=0> x2[N];
real<lower=0> x3[N];
real<lower=0> y[N];
}
parameters {
real wk[N];
real trend[N];
real s_trend;
real s_q;
real s_wk;
real<lower=0> a;
real<lower=0> b;
real<lower=0> c;
real d;
}
model {
real q[N];
real cum_trend[N];
for (i in 7:N)
wk[i]~normal(-wk[i-1]-wk[i-2]-wk[i-3]-wk[i-4]-wk[i-5]-wk[i-6],s_wk); // 周期7の季節調整(曜日変動)
for (i in 3:N)
trend[i]~normal(2*trend[i-1]-trend[i-2],s_trend); // 二階差分トレンド
cum_trend[1]<-trend[1];
for (i in 2:N)
cum_trend[i]<-cum_trend[i-1]+trend[i];
for (i in 1:N)
q[i]<-y[i]-wk[i]-cum_trend[i]; // 目的変数を回帰部分、季節調整、トレンドに分解する
for (i in 1:N)
q[i]~normal(a*x1[i]+b*x2[i]+c*x3[i]+d,s_q); // 回帰部分のサンプリング
}
> d<-read.csv('https://github.com/ozt-ca/tjo.hatenablog.samples/raw/master/r_samples/public_lib/DM_sampledata/example_bayesian_modeling.csv') > dat<-list(N=nrow(d),y=d$cv,x1=d$ad1,x2=d$ad2,x3=d$ad3) > library(rstan) # 並列化オプションを入れる > rstan_options(auto_write = TRUE) > options(mc.cores = parallel::detectCores()) > fit<-stan(file='https://github.com/ozt-ca/tjo.hatenablog.samples/raw/master/r_samples/public_lib/DM_sampledata/hb_trend_cum_wk.stan',data=dat,iter=1000,chains=4) starting worker pid=4813 on localhost:11406 at 00:03:29.822 starting worker pid=4821 on localhost:11406 at 00:03:30.007 starting worker pid=4829 on localhost:11406 at 00:03:30.188 starting worker pid=4837 on localhost:11406 at 00:03:30.370 SAMPLING FOR MODEL 'hb_trend_cum_wk' NOW (CHAIN 1). Chain 1, Iteration: 1 / 1000 [ 0%] (Warmup) SAMPLING FOR MODEL 'hb_trend_cum_wk' NOW (CHAIN 2). Chain 2, Iteration: 1 / 1000 [ 0%] (Warmup) SAMPLING FOR MODEL 'hb_trend_cum_wk' NOW (CHAIN 3). Chain 3, Iteration: 1 / 1000 [ 0%] (Warmup) SAMPLING FOR MODEL 'hb_trend_cum_wk' NOW (CHAIN 4). Chain 4, Iteration: 1 / 1000 [ 0%] (Warmup) # ... 中略 ... # Chain 3, Iteration: 1000 / 1000 [100%] (Sampling)# # Elapsed Time: 34.838 seconds (Warm-up) # 16.5852 seconds (Sampling) # 51.4232 seconds (Total) # Chain 4, Iteration: 1000 / 1000 [100%] (Sampling)# # Elapsed Time: 42.5642 seconds (Warm-up) # 46.8373 seconds (Sampling) # 89.4015 seconds (Total) # Chain 2, Iteration: 1000 / 1000 [100%] (Sampling)# # Elapsed Time: 47.8614 seconds (Warm-up) # 44.052 seconds (Sampling) # 91.9134 seconds (Total) # Chain 1, Iteration: 1000 / 1000 [100%] (Sampling)# # Elapsed Time: 41.7805 seconds (Warm-up) # 50.8883 seconds (Sampling) # 92.6688 seconds (Total) # # 以下事後分布の最頻値をパラメータ推定結果として取り出すプロセス > fit.smp<-extract(fit) > dens_a<-density(fit.smp$a) > dens_b<-density(fit.smp$b) > dens_c<-density(fit.smp$c) > dens_d<-density(fit.smp$d) > a_est<-dens_a$x[dens_a$y==max(dens_a$y)] > b_est<-dens_b$x[dens_b$y==max(dens_b$y)] > c_est<-dens_c$x[dens_c$y==max(dens_c$y)] > d_est<-dens_d$x[dens_d$y==max(dens_d$y)] > trend_est<-rep(0,100) > for (i in 1:100) { + tmp<-density(fit.smp$trend[,i]) + trend_est[i]<-tmp$x[tmp$y==max(tmp$y)] + } > week_est<-rep(0,100) > for (i in 1:100) { + tmp<-density(fit.smp$wk[,i]) + week_est[i]<-tmp$x[tmp$y==max(tmp$y)] + } > pred<-a_est*d$ad1+b_est*d$ad2+c_est*d$ad3+d_est+cumsum(trend_est)+week_est > matplot(cbind(d$cv,pred,d_est+cumsum(trend_est)),type='l',lty=1,lwd=c(2,3,2),col=c('black','red','#008000'),ylab="CV") > legend("topleft",c("Data","Predicted","Trend"),col=c('black','red','#008000'),lty=c(1,1),lwd=c(2,3,2),cex=1.2)
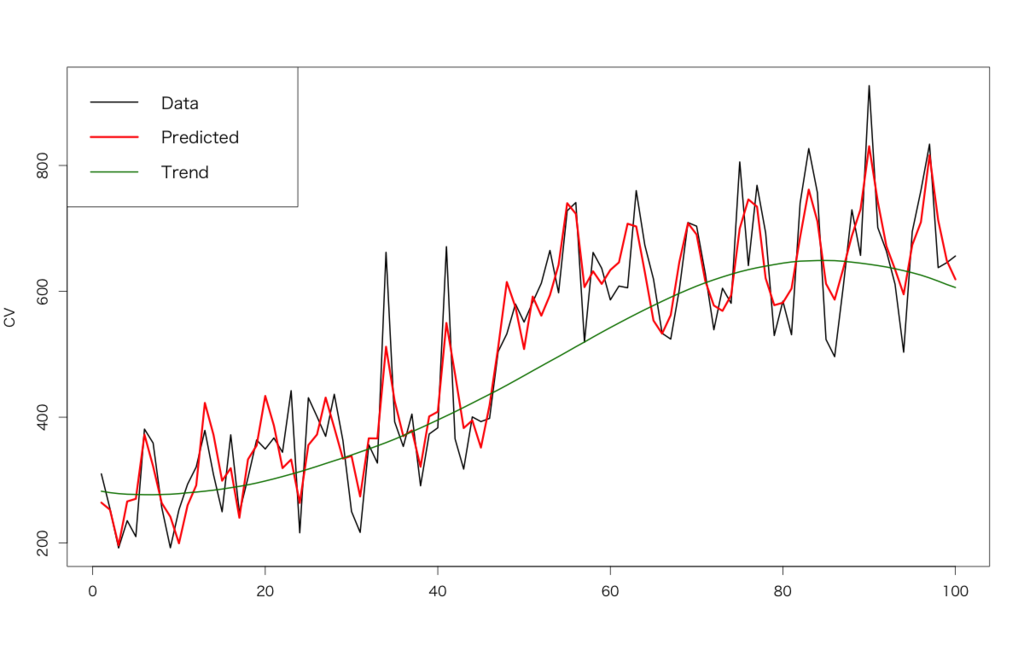
さすがに完璧にはフィッティング出来ていませんが、何の事前知識もなくただ季節調整+二階差分トレンドの項をStanコード上で盛り込んでただサンプリングしてパラメータ推定しただけの結果としては上出来だと思います。
追記:ベクトル化したStanスクリプトの例
上記のやり方だとまだるっこしいので、こんな感じにするともう少しシンプルになる上に列数が変わっても融通が利くようになります。備忘録的に。
data {
int<lower=0> N;
int<lower=0> M;
matrix[N, M] X;
real y[N];
}
parameters {
real trend[N];
real season[N];
real s_trend;
real s_q;
real s_season;
vector<lower=0>[M] beta;
real d;
}
model {
real q[N];
real cum_trend[N];
for (i in 7:N) {
season[i]~normal(-season[i-1]-season[i-2]-season[i-3]-season[i-4]-season[i-5]-season[i-6],s_season);
}
for (i in 3:N)
trend[i]~normal(2*trend[i-1]-trend[i-2],s_trend);
cum_trend[1]<-trend[1];
for (i in 2:N)
cum_trend[i]<-cum_trend[i-1]+trend[i];
for (i in 1:N)
q[i]<-y[i]-cum_trend[i]-season[i];
for (i in 1:N)
q[i]~normal(dot_product(X[i], beta)+d,s_q);
}
このStanスクリプトを'v2.stan'という名前で保存した上で、以下のようにkickします。
> d<-read.csv('https://github.com/ozt-ca/tjo.hatenablog.samples/raw/master/r_samples/public_lib/DM_sampledata/example_bayesian_modeling.csv') > dy<-d$cv > dvar<-d[,-1] > d.dat<-list(N=nrow(dvar), M=ncol(dvar), X=dvar, y=dy) > library(rstan) # 並列化オプションを入れる > rstan_options(auto_write = TRUE) > options(mc.cores = parallel::detectCores()) > fit <- stan(file='v2.stan', data=d.dat, iter=1000, chains=4) > fit.smp<-extract(fit) > t_d<-density(fit.smp$d) > d_est<-t_d$x[t_d$y==max(t_d$y)] > beta<-rep(0,ncol(dvar)) > for (i in 1:ncol(dvar)) { > tmp<-density(fit.smp$beta[(2000*(i-1)+1):(2000*i)]) > beta[i]<-tmp$x[tmp$y==max(tmp$y)] > } > trend<-rep(0,nrow(dvar)) > for (i in 1:nrow(dvar)) { > tmp<-density(fit.smp$trend[,i]) > trend[i]<-tmp$x[tmp$y==max(tmp$y)] > } > season<-rep(0,nrow(dvar)) > for (i in 1:nrow(dvar)) { > tmp<-density(fit.smp$season[,i]) > season[i]<-tmp$x[tmp$y==max(tmp$y)] > } > beta_prod<-rep(0,nrow(dvar)) > for (i in 1:ncol(dvar)){beta_prod<-beta_prod + dvar[,i]*beta[i]} > pred <- d_est + beta_prod + cumsum(trend) + season > matplot(cbind(dy,pred,d_est+cumsum(trend)),type='l',lty=1,lwd=c(2,3,2),col=c('black','red','#008000'),ylab="CV") > legend("topleft",c("Data","Predicted","Trend"),col=c('black','red','#008000'),lty=c(1,1),lwd=c(2,3,2),cex=1.2)
これなら行数・列数が変わってもそのまま回せますし、何よりもStan演算自体が速くなります。
word2vec
2013年以降自然言語処理の分野に広まったのがword2vec。その名の通り「単語を数値で表せるベクトルに表現し直すことで『似ている単語のリストアップ』や『単語の意味の足し引き』を出来るようにする」手法です。それゆえ、様々な自然言語処理データの前処理や特徴量作成に用いられることが多い様です。以前このブログでも簡単に取り上げたことがあります。
ということで、ここでも簡単に試してみましょう。とりあえず物凄く手っ取り早い例として、このブログではてブ500以上を取った記事の中から与太話系のものを集めてきて(笑)、まとめたものをGitHubリポジトリに置いておきましたので、これをローカルにDLしてきてください。その上でMeCabで分かち書きをした上で、word2vecにかけていきます。なおword2vecの実装としては、Python上でeasy_installで簡単にインストールできるgensimから利用するのが今のところ最も簡単なのでこちらを使います。インストール方法などは上記ブログ記事をご参照あれ。
$ mecab -Owakati tjo_stories.txt -o tjo_stories_token.txt
その上でPythonで以下のように実行します。
from gensim.models import word2vec data = word2vec.Text8Corpus('tjo_stories_token.txt') model = word2vec.Word2Vec(data, size = 100) out = model.most_similar(positive=[u'統計', u'学']) for x in out: print x[0], x[1] 基礎 0.987444281578 分析 0.98454105854 人 0.982671976089 思い 0.982490897179 検定 0.982355296612 あっ 0.982218146324 そういう 0.981627583504 言え 0.981441140175 勉強 0.981229901314 一方 0.980490446091 out = model.most_similar(positive=[u'機械',u'学習']) for x in out: print x[0], x[1] と 0.950019478798 か 0.946986079216 ある程度 0.940009057522 場合 0.939836621284 学 0.933527469635 的 0.928611636162 理解 0.925901889801 分析 0.923837661743 せよ 0.922927498817 でも 0.922164022923 out = model.most_similar(positive=[u'統計'], negative = [u'データ']) for x in out: print x[0], x[1] ん 0.924124836922 ね 0.907221496105 特に 0.900418162346 これ 0.896694540977 です 0.89433068037 まで 0.893202722073 ない 0.887368142605 わけ 0.88346517086 ませ 0.877071022987 可能 0.875332713127
「統計-学」は「基礎・分析・検定」との関連が強く、「機械-学習」は「ある程度・理解」との関連が強く、「統計」から「データ」を差し引くと訳が分からない感じです(汗)。やっぱりこの程度だとデータ量が少な過ぎるんですかね。。。以前のブログ記事の青空文庫データの例の方がまだまともかもしれませんね。
K-meansクラスタリング
教師なし学習の代表格とも言えるクラスタリング。手法自体は挙げていくとキリがなく、また様々な言語によるライブラリ実装も多いので何を取り上げても良いのですが、ここでは最も一般的かつ簡便と思われるK-meansクラスタリングを取り上げます*12。これも以前の記事で取り上げたことがあります。
方法論の詳細は割愛しますが、要は「事前に定めたk個のクラスタにデータ自体の性質に基づいて振り分ける」手法です。例えば拙著5章の商品購買シミュレーションデータセットを用いるとこんな感じに実践できます。
> d<-read.csv('https://github.com/ozt-ca/tjo.hatenablog.samples/raw/master/r_samples/public_lib/DM_sampledata/ch5_3.txt',header=T,sep=' ') > d.km<-kmeans(d,centers=3) > d1<-cbind(d,d.km$cluster) > names(d1)[6]<-'cluster' > res<-with(d1,aggregate(d1[,-6],list(cluster=cluster),mean)) # クラスタリング結果をまとめる > res cluster books cloths cosmetics foods liquors 1 1 9.047619 13.57143 5.285714 4.333333 7.571429 2 2 46.060606 11.36364 4.575758 5.090909 5.242424 3 3 28.739130 10.28261 4.478261 5.043478 6.043478 > barplot(as.matrix(res[order(res$books),-6]),col=rainbow(5))
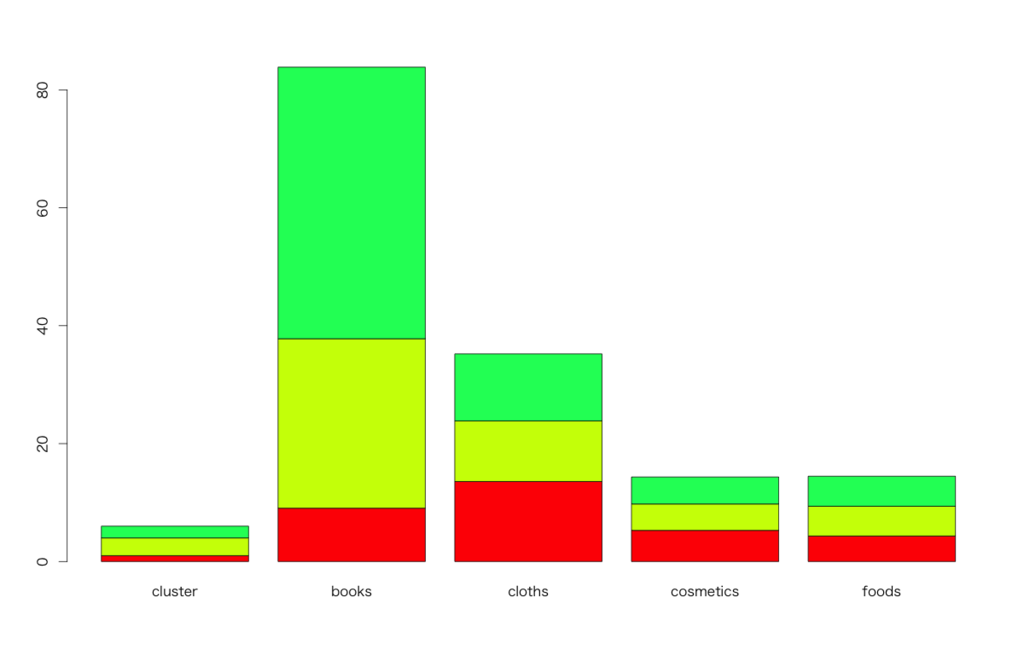
物凄く適当な可視化なんですが、4つの色に分かれた3つのクラスタがそれぞれどれくらい5カテゴリそれぞれの商品を含んでいるかが見て取れるかと思います。もちろん、もっと複雑なデータであればさらに細かい特徴を持つクラスタ同士に分けることも出来ます。
ちなみに、実務で用いる場合のやり方としては、「まずK-meansクラスタリングでユーザーを適当な数のクラスタに振り分け」ておいてから、「そのクラスタを学習ラベルとして機械学習分類器を推定し、その分類器を用いて新規ユーザーを個々のクラスタに分け」ていく、という二段構えの方法論があったりします。ドメイン知識ではユーザーなりドキュメントなりの分類ができないケースでは有用な方法です。
グラフ理論・ネットワーク分析
こちらなんですが、最近になって様々な業界・領域にエッジリスト及びマルコフ連鎖で表現可能なデータが数多くあることが分かってきたため、個人的にも結構習得に力を入れている手法でもあります。昨年末にシリーズ記事を書いたので、手法の詳細は割愛ということで。
ダイジェスト版として、有名な"Karate"データセット*13に対して定番と思われるグラフ理論・ネットワーク分析手法を幾つかに限って適用してみます。やっていることはシンプルで、{igraph}パッケージでは媒介中心性を算出して「どの人物がどれくらいハブ的な役割を果たしているか(人間関係の要衝になっているか)」を定量化した上でFruchterman-Reingoldアルゴリズムで関連の強い人物同士が近くに配置されるように描画し、{linkcomm}パッケージでは1人が複数のコミュニティ(友人グループ)に属すると仮定した場合のコミュニティの割り当てを推定し、同様に描画しています。
> library(igraph) > library(linkcomm) > g<-graph.edgelist(as.matrix(karate),directed=F) > g IGRAPH U--- 34 78 -- + edges: [1] 1-- 2 1-- 3 2-- 3 1-- 4 2-- 4 3-- 4 1-- 5 1-- 6 1-- 7 5-- 7 6-- 7 1-- 8 2-- 8 3-- 8 4-- 8 [16] 1-- 9 3-- 9 3--10 1--11 5--11 6--11 1--12 1--13 4--13 1--14 2--14 3--14 4--14 6--17 7--17 [31] 1--18 2--18 1--20 2--20 1--22 2--22 24--26 25--26 3--28 24--28 25--28 3--29 24--30 27--30 2--31 [46] 9--31 1--32 25--32 26--32 29--32 3--33 9--33 15--33 16--33 19--33 21--33 23--33 24--33 30--33 31--33 [61] 32--33 9--34 10--34 14--34 15--34 16--34 19--34 20--34 21--34 23--34 24--34 27--34 28--34 29--34 30--34 [76] 31--34 32--34 33--34 > g.bw<-betweenness(g) # 媒介中心性を計算する > g.ocg<-getOCG.clusters(karate) # OCGクラスタを推定する > par(mfrow=c(1,2)) > plot(g,vertex.size=g.bw/10,layout=layout.fruchterman.reingold) > plot(g.ocg,type='graph',layout=layout.fruchterman.reingold)
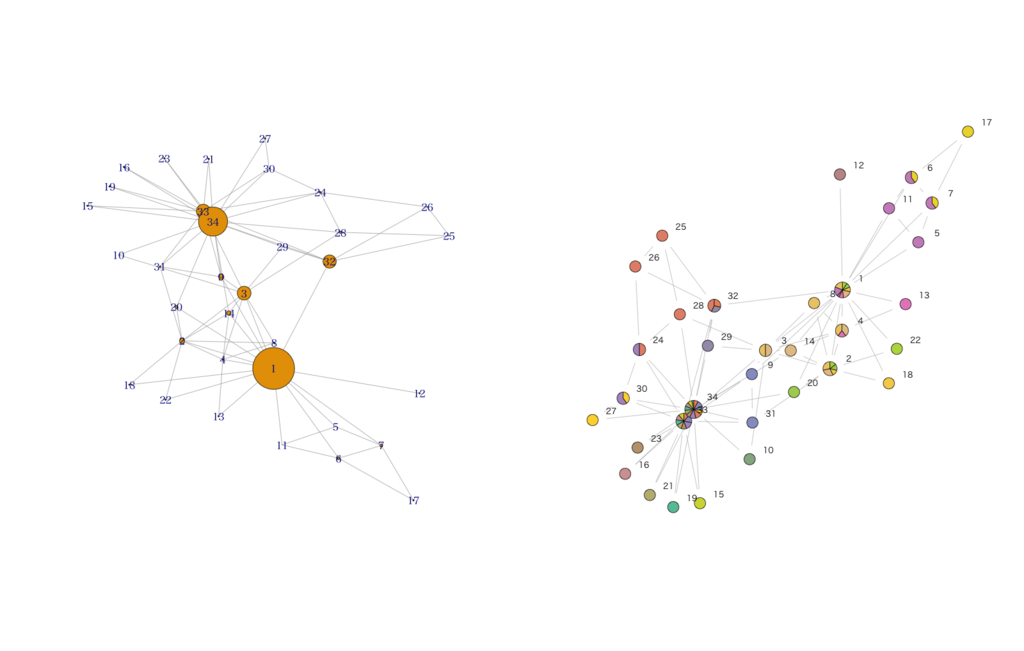
1番と34番がそれぞれ2つの大きなグループの「親分」格であると同時に、33番が34番の忠実な片腕、そして3番と32番が大きなグループ同士を取り持つ「仲介役」の立ち位置にあることが窺えます。
その他の有用な手法たち
ここだけ分けてあるのは、先述の通り業界全体としては広く使われているものの僕自身が自分の手を動かして実践したことがまだない手法2種です。ということで、上の10手法ほど実践的ではない(=チュートリアルをなぞるだけに近い)説明にしかなっていないので、悪しからずご了承あれ。
LDA及びトピックモデル
以前の現場では新卒の子たちにやってもらっていたという事情もあって、個人的には自分では実践していない割にかなり馴染み深い手法の一つがLDA (Latent Dirichlet Allocation)。いわゆるトピックモデルの代表的な手法です。トピックモデルとは大雑把に書くと「それぞれの『トピック』に分けられるような文章にどのような単語がどれくらい出現するかという確率を表すモデル」で、例えば文書の分類に多く用いられます。また単語の代わりに何か別のものをデータとしても良く、業界内では時々「そんなものにトピックモデル使うのかよ!!!」みたいな事例を耳にすることもあります。
で、一般にLDAというとシステム実装を念頭に置くケースが多く、必然的にPythonなどでの実装の方が入手しやすいです。例えばword2vecの時にも出てきたgensimの実装が有名です。ただ、ローカルで試すだけならRにも{lda}パッケージがあり、真似事だけなら簡単にできます。とりあえずid:MikuHatsuneさんの記事からコードを丸々なぞってみましょう(笑)。
ただし使うデータは'newsgroups'に変更しました。上記記事中でも使われている'cora'同様{lda}パッケージに同梱されている、20カテゴリ20,000本のnewsgroup*14の記事を集めたデータセットです。
> library(lda) > data(newsgroup.train.documents) > data(newsgroup.vocab) # 最初の記事のword frequencyを適当にheadしてみる > head(as.data.frame(cbind(newsgroup.vocab[newsgroup.train.documents[[1]][1, ]+1],newsgroup.train.documents[[1]][2, ])),n=10) V1 V2 1 archive 4 2 name 2 3 atheism 10 4 resources 4 5 alt 2 6 last 1 7 modified 1 8 december 1 9 version 3 10 atheist 9 # トピックモデルを推定する > K <- 20 > result <- lda.collapsed.gibbs.sampler(newsgroup.train.documents, K, newsgroup.vocab, 25, 0.1, 0.1, compute.log.likelihood=TRUE) # 個々のトピックを構成する単語を3個ないし20個挙げてみる > top.words3 <- top.topic.words(result$topics, 3, by.score=TRUE) > top.words20 <- top.topic.words(result$topics, 20, by.score=TRUE) > top.words3 [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12] [,13] [1,] "he" "god" "space" "drive" "that" "that" "window" "it" "that" "com" "he" "windows" "the" [2,] "they" "that" "the" "scsi" "it" "was" "file" "car" "israel" "medical" "team" "software" "of" [3,] "was" "jesus" "of" "mb" "mr" "of" "db" "you" "not" "was" "game" "graphics" "and" [,14] [,15] [,16] [,17] [,18] [,19] [,20] [1,] "key" "god" "you" "you" "edu" "space" "that" [2,] "encryption" "that" "that" "it" "com" "nasa" "we" [3,] "chip" "of" "gun" "they" "writes" "for" "you" > top.words20 [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [1,] "he" "god" "space" "drive" "that" "that" "window" "it" [2,] "they" "that" "the" "scsi" "it" "was" "file" "car" [3,] "was" "jesus" "of" "mb" "mr" "of" "db" "you" [4,] "were" "he" "nasa" "card" "stephanopoulos" "not" "server" "my" [5,] "she" "the" "and" "disk" "president" "it" "motif" "that" [6,] "had" "of" "launch" "output" "you" "as" "widget" "use" [7,] "and" "is" "satellite" "file" "we" "you" "mit" "or" [8,] "we" "not" "center" "controller" "he" "writes" "sun" "com" [9,] "that" "we" "orbit" "entry" "government" "drugs" "uk" "driver" [10,] "her" "his" "lunar" "drives" "is" "are" "com" "engine" [11,] "armenians" "you" "in" "ide" "not" "were" "edu" "cars" [12,] "his" "bible" "gov" "mhz" "this" "article" "display" "if" [13,] "turkish" "people" "earth" "bus" "jobs" "who" "set" "wiring" [14,] "the" "christian" "by" "system" "what" "in" "application" "get" [15,] "there" "armenian" "to" "memory" "com" "about" "windows" "but" [16,] "said" "it" "spacecraft" "mac" "clinton" "sex" "code" "oil" [17,] "armenian" "who" "mission" "dos" "if" "greek" "lib" "me" [18,] "him" "christ" "south" "if" "believe" "people" "cs" "can" [19,] "me" "turkish" "on" "windows" "think" "is" "tar" "up" [20,] "went" "are" "mars" "pc" "people" "livesey" "xterm" "speed" [,9] [,10] [,11] [,12] [,13] [,14] [,15] [,16] [1,] "that" "com" "he" "windows" "the" "key" "god" "you" [2,] "israel" "medical" "team" "software" "of" "encryption" "that" "that" [3,] "not" "was" "game" "graphics" "and" "chip" "of" "gun" [4,] "you" "in" "season" "image" "government" "clipper" "is" "the" [5,] "israeli" "disease" "games" "dos" "israel" "keys" "it" "he" [6,] "to" "msg" "hockey" "ftp" "jews" "to" "not" "guns" [7,] "of" "aids" "play" "files" "militia" "government" "we" "we" [8,] "is" "patients" "players" "version" "states" "privacy" "to" "they" [9,] "people" "article" "year" "file" "their" "security" "you" "not" [10,] "jews" "writes" "his" "available" "by" "escrow" "believe" "have" [11,] "who" "use" "league" "pub" "united" "secure" "jesus" "is" [12,] "are" "food" "teams" "mail" "state" "nsa" "evidence" "if" [13,] "their" "it" "baseball" "information" "congress" "des" "he" "your" [14,] "they" "apr" "win" "pc" "turkey" "law" "there" "people" [15,] "war" "hiv" "nhl" "system" "amendment" "the" "christians" "weapons" [16,] "it" "university" "player" "anonymous" "um" "system" "his" "it" [17,] "we" "edu" "was" "for" "law" "will" "christian" "are" [18,] "arab" "had" "vs" "mac" "mr" "public" "they" "of" [19,] "human" "health" "pts" "data" "arms" "of" "do" "was" [20,] "were" "my" "division" "internet" "turks" "pgp" "atheism" "do" [,17] [,18] [,19] [,20] [1,] "you" "edu" "space" "that" [2,] "it" "com" "nasa" "we" [3,] "they" "writes" "for" "you" [4,] "is" "article" "program" "is" [5,] "that" "it" "edu" "to" [6,] "writes" "my" "the" "it" [7,] "edu" "apr" "email" "they" [8,] "don" "you" "flight" "do" [9,] "uiuc" "bike" "system" "not" [10,] "think" "car" "moon" "my" [11,] "your" "cs" "henry" "he" [12,] "article" "dod" "research" "have" [13,] "not" "ca" "engine" "people" [14,] "my" "pitt" "model" "what" [15,] "com" "cars" "sale" "church" [16,] "would" "too" "send" "be" [17,] "me" "like" "shuttle" "think" [18,] "if" "ride" "you" "can" [19,] "do" "ac" "entries" "there" [20,] "cso" "uucp" "looking" "if" # 最初の5つの記事だけチェックしてみる > N <- 5 > topic.proportions <- t(result$document_sums) / colSums(result$document_sums) > topic.proportions <- topic.proportions[1:N, ] > topic.proportions[is.na(topic.proportions)] <- 1 / K > colnames(topic.proportions) <- apply(top.words3, 2, paste, collapse=" ") > > par(mar=c(5, 14, 2, 2)) > barplot(topic.proportions, beside=TRUE, horiz=TRUE, las=1, xlab="proportion")
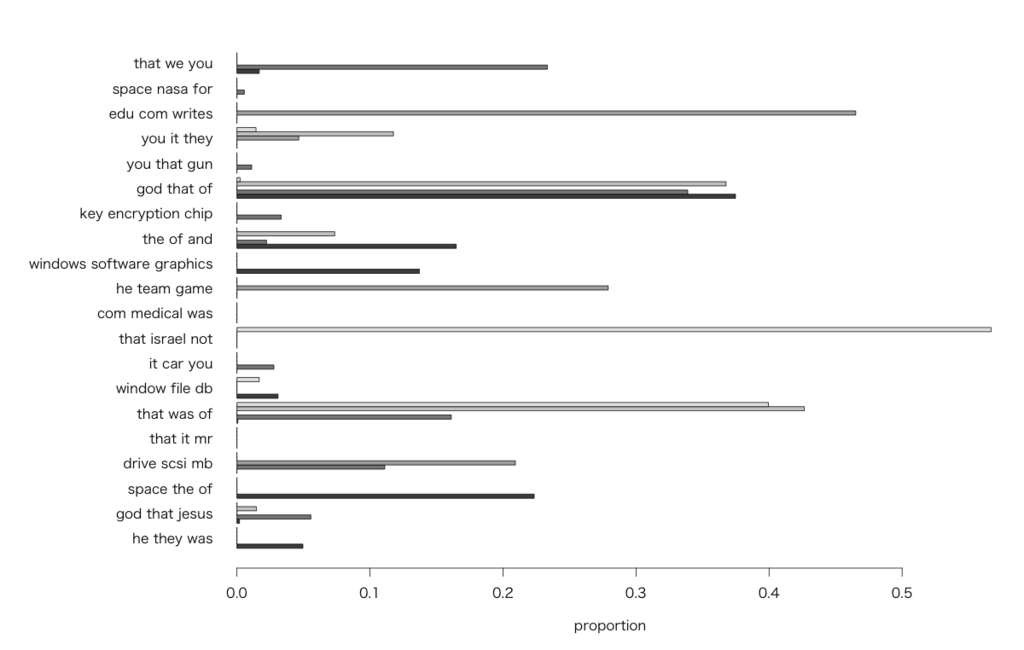
最初の5つのニュース記事のトピック確率をプロットしてみたものですが、幾つかのトピックは特定の記事しか含んでいないとか色々見て取れますね。ちなみに'newsgroups'データセットはtrain / testに分かれているので、trainでモデルを作ってtestで試すこともできます。
因子分解(SVD・NMFなど)
これまた実は僕自身が実務では一度もやっていないものの(滝汗)、以前の現場ではチームメンバーにやってもらっていた&頻繁に論文輪読会でも重要テーマとして取り上げられていたので非常に馴染み深い手法の一つです。現代のレコメンデーション技術の基礎となっているのが因子分解系の諸手法ということもあり、好んで取り上げられていたという側面もあるかと思います。
本質的には「次元削減」即ち元のデータから要らない要素を削ぎ落とすという、ただそれだけです。しかしながら、これによって疎な(sparse)データからでもレコメンデーションの計算がしやすくなるというメリットが得られます。この辺は全部書いているだけで大変&僕の勉強も不足しているので、代わりにいつもお世話になっているお二方、id:SAMさん並びにid:a_bickyさんのブログ記事を引用しておきます。
ということで、GitHubリポジトリに上げてある購買シミュレーションデータに対して同じことをやってみましょう。ぶっちゃけお二方の実践例をただなぞっているだけなので何一つオリジナルではありませんごめんなさい(汗)。
# 拙著9章の購買シミュレーションデータ > M<-read.csv('https://github.com/ozt-ca/tjo.hatenablog.samples/raw/master/r_samples/public_lib/DM_sampledata/ch9_2.txt',header=T,sep=' ') # SVDでrankを4まで削った例 > res.svd <- svd(M) # SVD > u <- res.svd$u > v <- res.svd$v > d <- diag(res.svd$d) > d_r <- d > for (i in 5:11) { + d_r[i, i] <- 0 + } > R_svd <- as.matrix(M) %*% v %*% solve(d) %*% d_r %*% t(v) > colnames(R_svd) <- colnames(M) > head(round(R_svd, 2)) # レコメンデーション算出結果 book cosmetics electronics food imported liquor magazine sake stationery toy travel [1,] 0.74 1.21 0.15 0.36 0.24 1.00 0.82 0.14 0.42 1.07 0.19 [2,] 0.70 0.07 0.27 0.64 0.91 -0.02 -0.06 -0.03 0.63 0.02 0.23 [3,] 1.12 0.71 0.34 0.73 0.14 0.95 0.40 1.04 0.72 1.04 0.38 [4,] 1.40 0.68 0.45 1.01 0.72 0.92 0.33 0.79 1.00 1.02 0.47 [5,] 0.81 0.06 0.27 0.52 -0.03 0.96 -0.05 0.99 0.51 1.02 0.30 [6,] 1.13 1.17 0.35 0.87 0.20 -0.05 0.76 1.12 0.78 0.03 0.40 # NMFでrankを4まで削った例 > library(NMF) > res.nmf <- nmf(M, 4, seed=1234) # NMF > w <- basis(res.nmf) > h <- coef(res.nmf) > h_z <- rbind(h, rep(0, 11)) > R_nmf <- w %*% h > head(round(R_nmf, 2)) # レコメンデーション算出結果 book cosmetics electronics food imported liquor magazine sake stationery toy travel [1,] 0.81 1.36 0.00 0.52 0.00 0.97 0.68 0.00 0.54 1.13 0.00 [2,] 0.64 0.00 0.00 0.48 0.88 0.00 0.00 0.00 0.47 0.00 0.52 [3,] 1.07 0.75 0.47 0.70 0.00 1.00 0.37 0.76 0.71 1.17 0.00 [4,] 1.57 0.61 0.33 1.10 1.02 0.85 0.30 0.53 1.10 0.99 0.61 [5,] 0.78 0.00 0.44 0.50 0.00 0.95 0.00 0.70 0.52 1.11 0.00 [6,] 1.19 1.38 0.81 0.85 0.00 0.00 0.68 1.30 0.79 0.00 0.00
SVDとNMFとで最初の6ユーザーに対するレコメンデーションの結果が微妙に異なる(前者は負の値を含んでいるが後者は非負のみ)ことがお分かりかと思います。もちろん、実務の現場でのレコメンデーションに用いられる手法は実用上のポイントのみならず計算負荷なども考慮しなければいけないため、もっと複雑です。
統計学・機械学習の諸手法について学ぶ上で確認しておきたいポイント
以前の記事でも書きましたが、統計学と機械学習については個人的には以下のように区別できると思っています。
基本的に統計学的な観点から回帰モデルを用いる際は、例えばパラメータの大小といった「説明」的な要素を重視することが多いようです。他方、機械学習的な観点からはモロに未知データ(テストデータ)の「予測」を重視することが多いです。
そう考えた場合、自ずとモデルの性能評価をする指標は変わってきます。統計学的な観点からはAICのような静的な指標でモデルを評価することが多い一方で、機械学習的な観点からはやはり交差検証での性能でモデルを評価することが多く特に「汎化性能が高いかどうか」が求められます。「説明」と「予測」のどちらに重きを置くかが重要だと覚えておきましょう。
また「モデル性能に何が影響するか」も大事なポイントです。一般に、統計学的な側面が強いモデル(線形回帰モデルや一般化線形モデルなど)は説明変数の取捨選択がモデル性能に影響を与える一方、機械学習的な側面が強いモデル(ランダムフォレストやDeep Learningなど)はそれに加えてモデルが構造的に持つパラメータ*15の選び方が大きく影響することもあります。そのため後者はグリッドサーチのようなしらみ潰し的な方法でベストのパラメータチューニングを見つける必要があったりします。
このように、選ぶ手法次第でモデルの性能を向上させるための取り組み方までもが異なるという点に、ビジネス実務の現場で用いる際は注意が必要です。逆に言えばそこさえちゃんと出来ていれば、あまり難しい手法を使わなくても十分に実用に耐える結果を出せるということも言えます(個人的な経験から言えば)。
最後に
いくつか前回の10選から洩れたものがありますが、代表が決定木とSVM。前者は弱学習器としては今でも重宝されますが、単体としてみた場合に「精度は現代の分類器に比べて格段に劣る」一方で「思った以上にアドホック分析用途としても結果の解釈が難しい」こと、そしてRの場合便利だった{mvpart}パッケージがCRANから削除されてしまってインストールが面倒臭くなってしまったので、今回は外しました。
そしてSVMはその他の分類器が勃興する中にあって「汎化性能に優れる」以外のメリットがあまり大きくないのと、どちらかというと内部のアルゴリズムの導出&実装を勉強する方が学びが大きいという代物なので、今回のような「まずは使い方を覚えましょう」的記事にはあまりフィットしないということで外してあります。
後は、アソシエーション分析については現場で使われること自体が減ってきた(レコメンデーションならSVD/NMF系の方が強い)こともあり割愛。計量時系列分析も、ビジネス実務だと内生変数がメインのデータセットを扱うケースが(金融など分野を限れば多用されるとは言えども)割と限られるので、ベイジアンモデリング側で対応してもらうということで今回は外しました。
今回挙げた12個の手法についてより深く学ぶ上でお薦めの書籍は、以下の過去記事にまとめてありますのでよろしければそちらもどうぞ。
もちろんこの5冊+12冊だけでは上記の12手法全てを十二分に理解するには足りないので、適宜もっと体系的にまとまった書籍に皆さんご自身で当たられることをお薦めします。というか、僕自身がこの5冊+12冊を超えて色々別に良いテキスト探し出してきて読んで、もっと勉強せねば。。。
ということで、3年間の分野全体の進歩を踏まえて改めて「10+2選」を取り上げてみました。次に書くのはまた3年後ですかね?(笑)
追記
英語版書きました。
*1:Stanやxgboostのようにgcc / clangコンパイラが間接的に必要なもの、はたまたH2OのようにJavaが間接的に必要なものもあります
*2:仮説検定の枠組みは非常にややこしくて、実はこの場合でもDB1の方がより高速であると「結論付ける」ことが妥当かどうかには複雑な議論があったりします(特に効果量とサンプルサイズはたまたfile drawer problemなどが絡むと)。とは言え、統計学の「ユーザー」の立場としてはひとまず有意差あり=結論が出たとみなしても大抵の場合は問題ないです
*3:ぶっちゃけ例が微妙ですがこれ以上思い浮かばなかったんですごめんなさいごめんなさいごめんなさい
*4:もちろんエンジニアサイドで機械学習システムの実装をする際には、簡単なこともあって思った以上に多用されることの多い手法ですが
*5:つまりカウントデータであって、連続データではない点に注意が必要
*6:具体的には、このようなケースでは総サイト訪問者数を「オフセット項」としてモデルに組み込む必要があります
*7:その方法論はholdout, leave-one-out, k-foldsなど色々あります
*8:set.seed(71)すると良いかも?笑
*9:英語ブログでもH2Oのバージョンが違う以外は全て完全に同じ設定で試したことがあるんですが、これよりも正答率は低く出ています。バージョンアップしたついでに何か内部を変更したんですかね。。。
*10:要はいわゆるReLUですね
*11:RやPythonで簡単に手にはいるパッケージ・ライブラリで扱える範囲という意味で
*12:Ward法以下階層的クラスタリングや、EMアルゴリズム+混合モデルと言ったあたりは割愛します
*13:ある空手クラブにおける人間関係を無向グラフとして記録したもの
*14:これってあのfjとかも含んでる「ニュースグループ」ですよね?
*15:Deep Learningなら中間層の数や個々の層のユニット数など