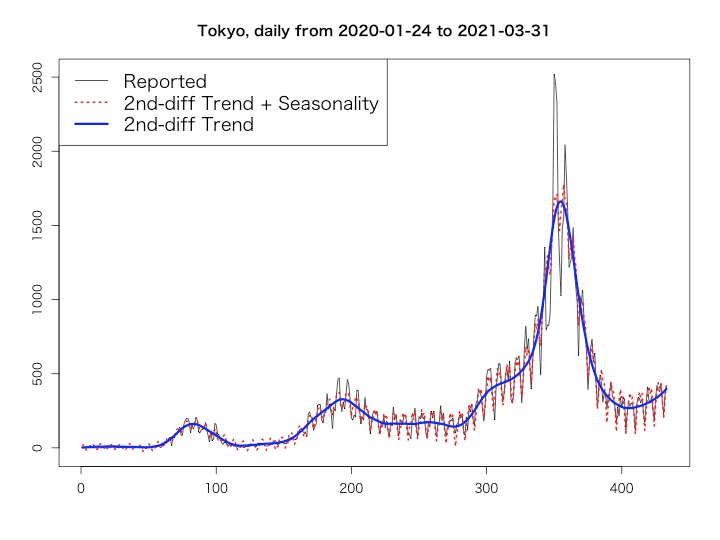
先日、Quora日本語版でこんなやり取りがありました。
基本的にはここで述べた通りの話なのですが、折角なのでブログの方でも記事としてちょっとまとめておこうと思います。題して「何故データサイエンティストになりたかったら、きちんと体系立てて学ばなければならないのか」というお話です。
問題意識としては毎回引き合いに出しているこちらの過去記事で論じられているような「ワナビーデータサイエンティスト」たちをどう導くべきかという議論が以前から各所であり、それらを念頭に置いています。なお毎度のことで恐縮ですが、僕も基本的には独学一本の素人ですので以下の記述に誤りや説明不足の点などあればご指摘くださると幸いです。
続きを読む