CausalImpactについては、過去にこのブログでも何度か話題にしてきたかと思います。端的に言えば、seasonalityによるバイアスを補正するための実験計画であるDID(Difference in Differences:差分の差分法)によって得られたtest/controlグループの時系列データセットに対して、介入後期間において反実仮想(counterfactual)ベースラインを予測値として与えた上で、これと実測値との差を分析することで介入の因果効果を推定するというものです。以前このブログで取り上げた記事と、ill-identifiedさんの詳細な解説記事とを以下に挙げておきます。
実際の使い方については、このブログで取り組んだ事例の記事を以下に挙げておきます。これはコロナ禍における政府の人流抑制策が、現実としてどれくらいの効果があったかを検証しようとしたものです。
業界全体を見渡してみても、CausalImpactはここ数年広告・マーケティング業界で急速に広まりつつあるみたいなんですね。理由は簡単で、マーケティング分野のデータは時系列で尚且つseasonalityが筆頭に上がるバイアスであり、DID & CausalImpactのコンビネーションはそのようなデータにおいて因果推論する上で最適だからです。特に広告やマーケティング施策などで何かしらの刺激を市場に与えた際のKPIへのアップリフトを、seasonalityを排除しつつ推定したいというケースではDID & CausalImpactほど便利なフレームワークはないと言っても過言ではないでしょう。
……ところが、最近になって思わぬ問題を業界内で耳にするようになりました。それは「使うCausalImpactのパッケージ次第で分析結果が変わる」というもので、しかも場合によっては介入効果の正負自体が変わってしまうという極端な差異が生じることもある、というのです。今回の記事は、そのような事態が起きる要因を推定した上で、同様の問題がOSSでは普遍的に起こり得るという点に注意を促すものです。
Disclaimer
このブログ記事の著者は、CausalImpactの元論文の発表元並びにR実装の開発元である企業に所属しています。
主要なCausalImpact実装
僕が把握している範囲では、CausalImpactには以下の3つの実装があるようです。まず、オリジナルのR実装。CRANにもリリース当初から上がっています。
Python実装としては、最初に発表されたのがpycausalimpactです。PyPIにも入っていて、Pythonistaには割と人気のあるパッケージのようです。ただし、現在そのGitHub repoは削除されている模様です。
もう一つ、直近で発表されているPython実装としてtfcausalimpactがあります。こちらはTensorflow Probability (TFP)ベースの実装です。TFPのせいか若干計算が遅いっぽいですが、使い勝手は良いと思います。
論文に記載されている通りの変数選択は行われているか?
上掲の3つのパッケージは、いずれも2015年発表のCausalImpactに関する論文に基づいて実装されているとされます。
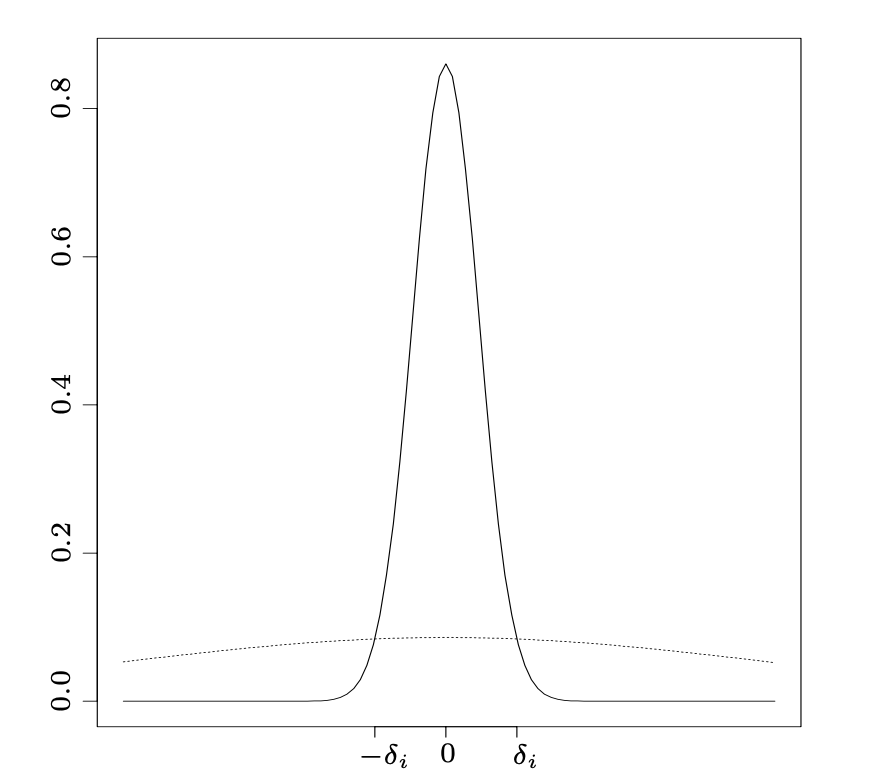
(spike-and-slab事前分布による変数選択を最初に具体的に提唱したとするGeorge & McCullochによる1997年の論文より)
その元論文をよく読むと、spike-and-slab事前分布を使ってcontrol群に対して変数選択を行っていると書かれています。これはCausalImpactがSCM(シンセティック統制法)という「control群のcherry-pickingを避けるために重回帰的に複数のcontrol変数を用いる」仕組みを採用しているためで、そこでいわゆる縮小推定をかけているんですね。これはL1正則化とコンセプトは同じで、ある程度自動的にcontrol変数を選び出す(モデル推定上不要なものは0に落とす)というものです。
そこで各実装を見ていくと、まずオリジナルのR実装はバックエンドとしてベイズ構造時系列モデルの推定エンジンである{bsts}を使っており、実はこれ自体がspike-and-slab事前分布をカバーしています。なのでそもそも元論文通りに変数選択を行っているというわけです。
次に、tfcausalimpactはソースコードを読むとtfp.sts.SparseLinearRegressionというメソッドを使っていることが分かるんですが、これがspike-and-slab事前分布とほぼ同等のHorseshoe事前分布を用いており、やはり変数選択を行っていると言えます。
ところが、pycausalimpactについては残念ながら元repoが削除されてしまっているのでソースコードは分かりませんが、docを見る限りでは「statsmodelsでカルマンフィルタとして最尤推定を行っている」とだけ書かれていて、変数選択が行われているかどうかはっきりしません。よって確言はしづらいのですが、docのどこにも変数選択の話題もspike-and-slab事前分布の話題も出てこないところを見ると、変数選択が行われていない可能性があるようです。実際、業界内で「CausalImpactの結果に差が出る」という話が出る際に使われているのがこのpycausalimpactであることがままあり、その可能性はゼロではなさそうです。仮に変数選択が行われていない場合、pycausalimpactでcontrol変数を複数置いて分析すると元論文とは異なり「変数選択全く無しの結果」が出てしまうわけで、その差は重大なものになりかねません。
念のためstatsmodelsのカルマンフィルタ周りのdocを確認した感じでは、変数選択が行われるようなメソッドは実装されていないように見受けられました。カルマンフィルタなど時系列モデルでなければ当然Lassoとかはあるわけですが、それはまた話が別ですよねということで。
ちなみに、実はGoogleからリリースされているTFP CausalImpactという実装と、5番目のCausalImpact野良実装というのがあります。前者は読んで字の如くTensorFlow Probability (TFP)ベース、後者はPyMCベースで実装されていて、ソースコードを見るとどちらもBayesian Lassoと思しきTFP / PyMCのコードが見えるので、恐らくですが元論文と同様の変数選択は行われているとみなして良いかと思われます。
コメントなど
あくまでも一般論ですが、「論文の手法を実装してみた」パッケージというのはCausalImpactに限らず沢山ある一方で、割と「論文通りに実装されていない」ケースは少なくないと業界内では聞きます。それには様々な理由があり得ますが、少なくともCausalImpactのケースに即して言えば「似たような計算を行うもう少し簡易な実装」を選んだことで、元論文が意図した要素が抜け落ちてしまった……ということのようです。
このご時世では、最新の注目手法の多くが論文が出たそばからどんどん実装されていき、GitHubやCRAN / PyPIのようなrepoに上がって公開されるのがすっかり平常運行になっていますが、なればこそその「実装の中身」がどうなっているかをきちんとソースコードを読んで確認することも時には必要なのかな、と思う次第です。
追記
実際にpycausalimpactでR版CausalImpactの挙動を再現できなかったケースが、こちらのQiita記事に出ていました。ご参考までに。