
著者の金本さんからご指名でご恵贈いただいたのが、こちらの『因果推論 ―基礎から機械学習・時系列解析・因果探索を用いた意思決定のアプローチ―』です。正直に白状しますと、因果推論とタイトルにつく技術書はここ数年でゴマンと出版されており、本書も紙冊子で頂戴したものの僕はあまり期待せずにページをめくり始めたのでした(ごめんなさい)。
ところが、ほんの数ページめくっただけでその内容に僕は仰天しました。グラフィカルで実務家にとっての分かりやすさを重視した因果推論の解説と実践にとどまらず、現代的なマーケティング分析では必須の種々の手法についてまで懇切丁寧に解説とPythonによる実践例が付された本書は、文字通り「マーケティング分析実務家にとってのバイブル」になり得る素晴らしい一冊だと直感したのです。
こんな素晴らしい本が世間に広まらないのはあまりにも勿体無いということで、早速レビューしてみようと思います*1。なお、いつもながらですが記述内容に理解不足や誤解などに基づく不備な点がありましたら、何なりとご指摘下されば幸いです。
本書の概要
いつもながらですが、まずは本書の概要について引用の範疇を超えないレベルで適宜具体的な内容を引用しながら、レビューしてみようと思います。
第1章 因果の探求から社会実装
読んで字の如く本書のイントロダクションに当たるチャプターですが、具体例としてUberにおけるマーケティング施策分析の実態を論文*2から引用しながら明快に解説しており、初学者にも分かりやすいのではないかと思いました。


この他にもNetflixにおけるレコメンデーション施策における因果推論の応用例についても触れており、「因果推論は机上の空論ではなく現代的な各種産業において既に大いに活用されている」という事実が強調されています。この点は過去の因果推論テキストにはあまり見られなかった姿勢だと個人的には感じました。
第2章 因果推論の基礎
ここから因果推論という体系そのものの具体的な内容に入っていきます。このチャプターでは、因果推論全般を通じての各種の共通概念についての解説がなされています。即ちRCTを理想的なベースラインとして、そこに交絡などのバイアスがかかった際に因果推論を行うものと想定した場合に意識されるメトリクスで、例えばATE, ATT, CATE, ITEといった因果効果指標の詳細が説明されています。

ATEとATTについて解説した図がこちらですが、これなら初学者にも理解しやすいのではないでしょうか。また、SUTVAのような「抽象的だが実はかなり重要で必ず知っておかなければならない概念」の解説もグラフィカルで分かりやすいです。
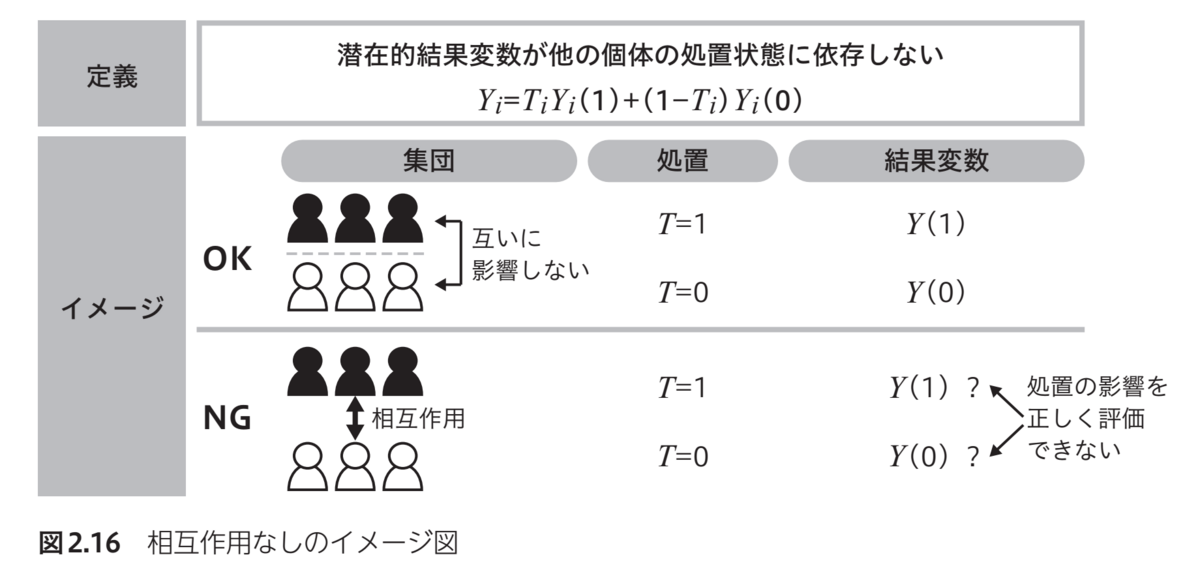
SUTVAの要件の一つであるNo interference(相互作用なし)の解説も、こちらのような図で明快になされています。本章ではこれらに加えてさらにシンプソンのパラドックスを入り口として、Pearl流のDAGの基本的な考え方とその読み解き方(バックドア基準など)の話題も展開されており、Rubin流と併せて因果推論という体系全体のまとめとしても分かりやすく書かれていると思います。
第3章 基本的な因果推論手法
このチャプターでは具体的な因果推論手法の実行・実装の方法が解説されています。まず初めに分析の全体像とそのアプローチ選択のためのフローチャートが提示された上で、回帰分析によるアプローチと、共変量調整によるアプローチ、そしてパラメータ推定の方法というように説明が進んでいきます。
ここでは構造方程式モデリング、傾向スコア、層別解析、IPW、DR(二重にロバストな推定法)、そして自然実験と回帰不連続デザイン、さらには操作変数法、DID(差分の差分法)、SCM(合成コントロール法)というように、計量経済学=統計学サイドの因果推論手法が一通り説明されていくのですが、個人的に良いと思ったのが「DRでやることのイメージ」の図です。

DRというと、漫然とRやPythonでやると「〇〇を××なる式に入れて返ってきた△△を……」というようにベタっと説明しているテキストが多いんですが*3、この模式図を見れば一目瞭然です。他書もこんな感じに説明してくれたら分かりやすかったのに、と思う次第です(笑)。
第4章 因果推論高度化のための機械学習
ここまでは因果推論の母体である統計学(計量経済学)サイドの話題がメインでしたが、ここからは打って変わって機械学習サイドの話題に入っていきます。この章ではまず機械学習という体系そのもののおさらいをするということで、PyCaretベースで各種の機械学習モデルを構築する流れを確認しながら、回帰・分類・アンサンブル学習・精度検証指標・説明可能性(解釈性)、そしてダッシュボード化といった話題についての説明がなされていきます。ただし、あくまでも「CATE / ITE(第2章を参照)を考慮した因果効果の推定」「非線形データに対応した推定」が機械学習を用いる利点であり目的である、という点が強調されています。
第5章 因果推論と機械学習の融合
この章では実際に機械学習を用いてCATEを推定する流れが解説されていきます。その代表例としてメタラーナーの考え方が提示された上で、その手法であるS-learner, T-learner, X-learner, DR-learnerそれぞれについての解説とその実装・実践例が分かりやすく説明されています。

また機械学習に必ずつきまとう過学習(過適合)と正則化の問題への対策としてのアプローチであるDouble / Debiased machine learning (DML)の解説や、その他の機械学習因果推論の手法として著名なCausal ForestやCausal BARTの紹介もあり、盛り沢山な内容です。これらの話題は実は僕にとっては目新しいものが多く、大いに勉強になりました。
第6章 感度分析
ここでは一つの章を割いて、未観測の交絡因子の因果効果の推定値への影響を評価するための感度分析の話題が展開されます。そのアプローチとして部分決定係数並びにE-value、さらに機械学習ベースのAusten Plotという3つの枠組みが示されており、それぞれのコンセプトと注意点が解説されています。個人的にはこの章の内容も僕には目新しく、印象的だと感じた次第です。
第7章 因果推論のための時系列解析
これまでの章ではストレートに因果推論そのものの体系の解説がなされてきましたが、この章では打って変わって「世の中で取得・測定されるデータ型の代表例」とも言える時系列データに対する因果推論的アプローチの話題が展開されます。
その入り口としてまずPyCaretによる一般的な時系列解析が提示された後で、このブログでもお馴染みのCausalImpactによる時系列データへの単体施策効果の因果推論、そしてMMMによる複数施策効果の推定についての解説がなされています。


なおCausalImpactについてはtfcausalimpactを、MMMについてはPyMC MarketingのMMMを実装として用いています。
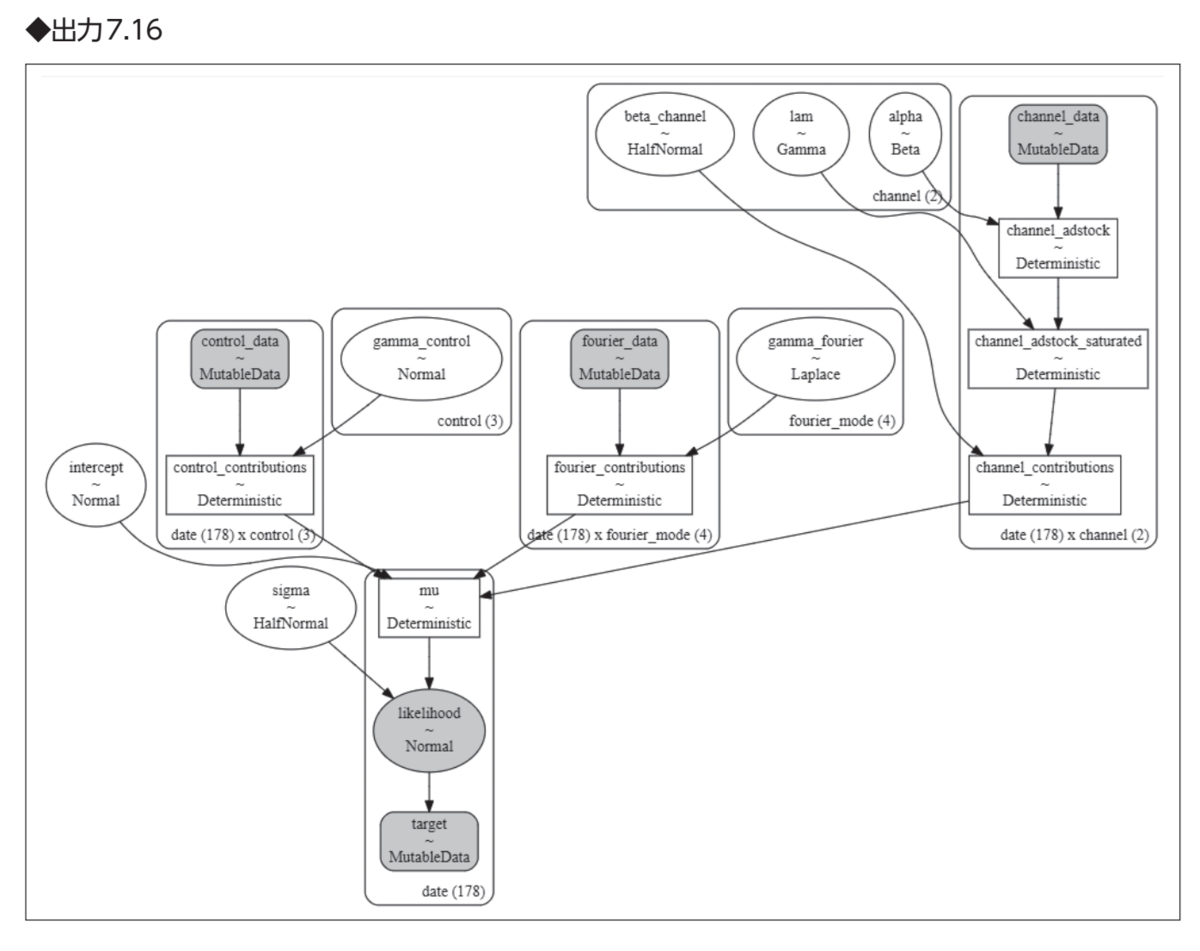
これは僕は初見だったのですが、PyMC MarketingだとMMMのDAGをグラフィカルに表示できるんですね。恥ずかしながら全く知りませんでした。
第8章 因果構造をデータから推定する因果探索
最後に、この章ではそもそもDAGが明確に分からない場合に探索的にその構造を明らかにしようとする、因果探索のアプローチについての解説がされています。この内容も僕は完全にノーマークでLiNGAMぐらいしか知らなかったので、大変に参考になりました。

静的・動的(時系列)それぞれの因果探索手法があり、データの性質によって使い分けるのだということも恥ずかしながら初めて知った次第です。
本書の特筆すべき点と、個人的な感想
これまでの内容レビューの中でも何度も称賛している通りですが、改めて本書の特筆すべき点について僕自身の感想を交えながら簡単にまとめてみようと思います。
現代的な因果推論の全体像を偏りなく余すところなく詳細に解説している
因果推論というテーマはデータサイエンス業界では2019年頃から大きく注目を集めるようになり久しく、冒頭でも述べたように類書が非常に多いのも事実です。ただ、個人的に把握している範囲では割とテーマを絞ったテキストが多い印象があり、例えば因果推論機械学習ならそのための本を、因果探索ならまたそのための本を、それぞれ求める必要があるという認識でした。
ところが、本書はそのほぼ全ての因果推論手法を一冊にまとめて概観し、最低でもその全てに実装例もしくは他の実装例へのポインタ*4を示すことで高い網羅性があり、非常に野心的な構成だと感じています。少なくとも本書さえ手元にあればとにかくPythonでの実装は出来る上に、より詳しい知識が必要になったら何を参照すれば良いかが分かるわけです。この点で本書は文字通り「現代的な因果推論手法の実践におけるバイブル」といっても過言ではないものと思われます。
説明がグラフィカルで分かりやすい
これまた内容レビュー中で何度も称賛していますが、とにかくテキストに頼らず図表を用いて分かりやすく示すという姿勢が本書全体を通じて一貫しており、素晴らしいと感じた次第です。
上掲のDRの模式図などはまさにその好例で、過去に読んだ*5テキストでは地の文で淡々とその手順が書き記されているだけで、実装コードを写経しながら「これでいいんだっけ???」と思ったりしたものなのですが、本書の解説は模式図つきで明快で非常に分かりやすいです。

他にも、初学者向けに傾向スコアの意義を説明するのは毎回まどろっこしいなと思っていたのですが、例えばこちらの図などはおそらく初学者でもかなり直感的に理解できるのではないでしょうか。ともあれ、随所にこのようなグラフィカルで端的にまとめられた説明が配置されており、本書の大きな特徴となっているように感じました。
現代的なマーケティング分析の重要トピックスを網羅している
最後に、個人的な関心に基づく感想で恐縮ではありますが……本章で最も特筆すべきは、CausalImpactとMMMという現代的な広告・マーケティングデータ分析において重きをなす二大手法について多くの紙面が割かれているところだと思います。
特にMMMについては、以前このブログでも概説したように生活者ターゲティングデータが使われなくなったこともあり、近年はその重要性も需要も高まるばかりです。にもかかわらず、意外にも現代的なベイジアン時系列モデリングベースのMMMについて解説した書籍自体が(少なくとも日本国内では)ほぼなく、初学者に紹介できるテキストがないものかなと思案していたのでした*6。
また、CausalImpactとMMMを組み合わせた広告・マーケティング効果検証フレームワークについてはこのブログでも何度か触れたことがありますが、MMMのテキスト自体がほぼないこともあって、他人様*7向けに説明する際に毎回「良い資料がないなぁ」とぼやいていたものです。
そこに現れたのが本書です。勿論因果推論というコンテクストの中に位置付けられてはいますが、CausalImpactもMMMも大幅に紙面を割いて丁寧に解説されている上に、その実装についても触れられています。PyMC Marketingベースということで、立場上全面的にお薦めするのは憚られる面もなくはないのですが*8、とは言えこの2つを同時に網羅的に解説しているテキストはおそらく現段階では本書のみと思われます。この点だけでとっても、現代的なマーケティング分析に携わる人たちにとってのバイブルたり得る一冊と言って良いでしょう。
……というわけで、僕がリードするサブチームでは早速本書を推薦図書としてメンバーに読んでもらっている次第です(笑)。既にKindle版も出ており冊子版が売り切れても入手自体は可能になっていますので、興味のある方々には是非一度お手に取っていただければと思います。
*1:実は以下に揚げる図表をコピペしたいというだけのためにKindle版を別に私費で購入しています
*2:https://www.liebertpub.com/doi/10.1089/big.2017.0104
*3:この辺など→統計的因果推論(2): 傾向スコア(Propensity Score)の初歩をRで実践してみる - 渋谷駅前で働くデータサイエンティストのブログ
*5:もしくは刊行委員として編集した
*6:ならお前が書けよというもっともなツッコミはご遠慮ください
*7:というかお客様
*8:Lightweight MMMもしくは現在early accessのみ提供されているMeridianだと有難いお話