")
みんな大好きHUNTER×HUNTERの36巻発売を記念して、調子に乗って面白いことを考えてみました。。。と言いますか、正確には提案をいただいたのでやってみることにしました。題して「念能力6系統で喩えるデータ分析スキル」です。一見バカバカしい感じもしますが、念能力6系統のように「それぞれに独立した軸として定義可能でしかも互いの親和性も表すことができる」という点で、なおかつHUNTER×HUNTERファンであれば容易にその位置付けが理解できるという点で、データ分析スキル同士の関連性をある程度分かりやすく表せるのではないかなと思ったのでした。
スキルセットの一覧については、以前のスキル要件記事辺りをお読みいただければと思います。データ分析がブームになってからそろそろ10年近くが経ち、時間が経過しても本質的な部分はあまり変わらなくなってきたように思います。その意味で、小分類を付け加えることはあっても大分類(一応6分類するという前提で)の方は今後も普遍的であろうと仮定しています。
ということで以下ざっくりと書いていきますが、当然のようにHUNTER×HUNTERの中身をご存知ない方にはほぼ全く分からないと思われる内容なので、平にご容赦ください。一方で、僕のHUNTER×HUNTERに関する知識はアニメ版第2作(日テレ版)で会長選挙・アルカ編までを通しで見た上でようやく原作に移って暗黒大陸編を読んでいるという、いわば「にわかファン」レベルなので、情報が偏っているか不足しているか、とにかく不勉強な旨予めお断りしておきますm(_ _)m
そもそも念能力の6系統とは
一応復習も兼ねて簡単にまとめておくと、念能力とは以下のような感じに6つの系統に分かれています。出典はWikipedia記事に拠りました。

(Wikipedia記事より)
- 強化系:モノの持つ働きや力を高める能力(ゴンのジャジャン拳やウボォーギンのビッグバンインパクトなど)
- 放出系:通常は自分の体から離れた時点で消えてしまうオーラを、体から離した状態で維持する能力(フランクリンのダブルマシンガンやナックルのハコワレなど)
- 変化系:自分のオーラの性質を変える能力(キルアの一連の電撃やヒソカのバンジーガムなど)
- 操作系:物質や生物を操る能力(イルミの針人間やシャルナークのブラックボイスなど)
- 具現化系:オーラを物質化する能力(クラピカの一連のチェーンやコルトピのギャラリーフェイクなど)
- 特質系:他の5系統に分類できない特殊な能力(クラピカの絶対時間やクロロのスキルハンターなど)
ちなみにこれらを真面目に調べるまで、どのキャラクターのどの念能力がどれに分類されるか知らなかったケースが結構多かったです。ナックルのハコワレって放出系だったんですね。。。他にもパクノダのメモリーボムは特質系だったのかと。
6系統は互いの距離が近ければ近いほど親和性が高く、逆に遠ければ親和性が低いとされ、言い換えると「合わせ技として習得できる念能力の難易度が決まる」「異なる系統同士の念能力を併用した場合の使い勝手の良し悪しが分かれる」ということが言えます。故に、例えば強化系の主人公ゴンが具現化系の技を習得するのは難しく、天空競技場のカストロのように無理やり相性の悪い強化系・変化系・具現化系を組み合わせた虎咬真拳はヒソカから「容量のムダ遣い」と笑われることになります。
もっともゲンスルーのカウントダウンのように「異なる系統の念能力の持ち主同士でチームを組む」ことで、必ずしも相性の良くない系統同士を掛け合わせて高度な能力を作り上げることもできるわけです。これは面白い設定であるなと思うと同時に、後述するように非常に合理的な考え方だなとも個人的には思います。
データ分析スキルの6系統に置き換えてみる

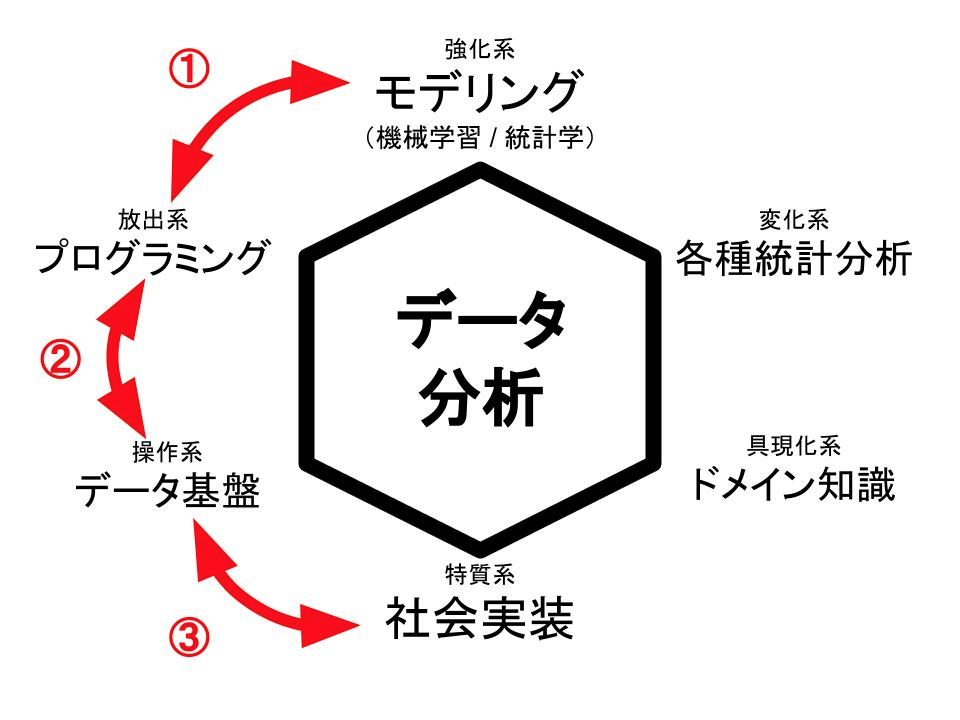
という、オリジナルの「念能力の6系統」を踏まえた上でデータ分析スキルについてもその6系統を書き出してみます。必ずしも「〇〇系」とイメージ面で対応しているわけではありませんので、どうか悪しからず。
また、重要なこととして念能力の6系統とは異なり「データ分析スキルの6系統は生まれつきの系統ではないのでそれぞれを後から研鑽を積んで兼ね備えることは不可能でも何でもない」という点が挙げられます。実際、下記の6系統のスキルのうち「プログラミング」を独立に習得している人はデータ分析専門職では非常に多いです。その意味で言うと、あくまでも「ゼロから学ぶ際の互いの親和性という意味での近い・遠い」を表していると見ていただくのが適切かもしれません。
強化系:モデリング(機械学習・統計学)
これは機械学習・統計学問わずモデリングに関わる全てを意味します。よって、機械学習であれば教師あり学習のロジスティック回帰以下線形モデル族・SVM・ランダムフォレスト / xgboost以下樹木モデル族・Deep Learning諸系統などなど、はたまた教師なし学習であればクラスタリング諸系統(混合モデル含む)・系列モデル・ノンパラベイズ・行列分解系諸系統などなどが挙がります。統計モデリングであれば、線形モデル族・GLM・GLMM・階層ベイズ・動的モデルなどなどですね。何ならベイジアン諸系統全部もここに入るのかなと。
そしてここにはそれらのモデリングを支える系統全て、言い換えると例えば最適化理論や各種数理体系もここに含みます。線形代数や微積分の最低限の知識が必要だという話を以前ブログに書きましたが、この「強化系」の中にはさらに踏み込んで範囲を広げて学習理論やアルゴリズムの研究開発スキルなども含むことにします。極端な言い方をすれば「データ分析の方法論に関するアカデミックな要素は全て含まれる」と言っても良いでしょう。それこそarXivでめぼしい研究論文を読んで実装するとか、もっと言えば自ら研究開発して成果をarXivいやNIPS / KDD / ICLRのようなトップ会議に通すというスキルもここに入れておいて良いのかなと*1。
何故そのように定義したかというと、個人的にはやはりこの「機械学習・統計学によるモデリング全般とそのバックボーンとなるアカデミックな全ての要素」こそが、データ分析という大きな枠組みの根幹そのものを成していると感じるからです。モデリングが成ればこそ「説明」も「予測」もできる、場合によっては他の仮説検定などで扱われることの多い「対比較」についても効率化できるわけです。その意味で多くの人が集まるという側面もあり、多くの念能力者が当てはまり時には正統派とも目される「強化系」の位置にふさわしいスキルだと考える次第です。
そしてもう一点。ここに機械学習・統計学的モデリングそのもののスキルのみならず最適化理論や数学も含めた理由として「この六角形の反対側との相性」というものもあるだろう、と思ったのでした。この点については6番目の項目で後述します。
放出系:プログラミング
モデリングを実践する際に欠かせないものの一つが、間違いなくプログラミング(コーディング)です。現代であればPythonもしくはR(分野によってはJuliaも)はデータ分析を実践するに当たって必須の教養と言っても過言ではなく、必要に応じてC++, Java, Go, C#などの高速でシステム実装に適した言語に通じていることも求められることがあります。またプログラミング言語としてPythonやRを使いこなすだけでなく、例えばNumPyやTidyverseのようなデータ分析のサポートとして重要なパッケージ・ライブラリについても通暁していることも大事でしょう。
ちょっと迷うのがTensorFlow, PyTorch, ChainerのようなNNフレームワーク。これは「モデリング」の方に入れても良いし、「プログラミング」の方に入れても良い気がするので、ちょうど両者の中間辺りに置いておくべきなのかもしれません。
また、単にプログラミングというだけでなく、例えばクラウドやGitHubのような高効率な開発環境を使いこなすスキルもこちらに入れて良いのかなと。言い方を変えると「アルゴリズム実装に関わる要素全て」がここに入ると思っていただければと。組み上がって動くものが「外に出てくる」という意味でも「放出系」がぴったりと言って良いかと思います。
変化系:各種統計分析
モデリングはしないが統計学的にデータを扱うというケースは色々あります。例えば仮説検定やそのバックボーンとしての実験計画なんかは代表例ですね。DiDや層別解析など、統計的因果推論の諸系統もここに入るのではないかと思います(傾向スコアは微妙なラインだと思いますが)。これらはモデルという世界を構築してそこにデータを入れ込むのではなく、データそのものに対して外側から色々光を当てたり物差しを添えたりすることで、何がしかの気付き=インサイトを得ようとするスキルだとも解釈できます。
もっともこれらが何かを「変化」させているかというと正直微妙で、どちらかというと他にスロットがなかったから「変化系」のスロットを充てたという方が正解です(笑)。ただし機械学習・統計学的モデリングとは当然ながら非常に近しい関係にあり(同じ統計学という点で)、その点も勘案しています。
操作系:データ基盤
現代においてデータ分析と言えばかなりの割合が「ビッグデータ」を相手にすることになると思われますが、そのビッグデータを支えるのが総称するところの「データ基盤」だというのが個人的な考えです。ここにはストレージやDBやSQLと言った、データを可能な限り全数に近い形で大量に保存・格納してさらにはそこの入出力をデータ分析のためにコントロールする方法論が含まれます。
なお、明示的には書きませんでしたがデータ基盤の整備はそのままTableauやKibanaのような「ダッシュボード」「データ可視化」に繋げることもできます。以前のブログ記事でもデータ活用戦略の最初期にやるべきこととして、データ基盤と同時にこれら可視化ダッシュボードの整備を一種の「スモールスタート」として推奨したこともあります。よって、これらも基本的には「データ基盤」に包含されると思っていただいて結構かなと。
ところで、これは伝統的な統計学の「小標本を抽出してそこから不偏推定量を求める」という考え方とは実は対極にあります。しかしながら一方で、明確なITシステム技術基盤の一つでもあるのでプログラミングとは親和性が高い。そこを踏まえて「操作系」の位置に配置してあります。
具現化系:ドメイン知識
ここでグッとビジネス寄りの話になってきます。一般に、産業界そして企業社会においてデータ分析を生業とするということは、イコール「何がしかのビジネスに貢献する」ことを主目的とします。それ故データ分析という職掌においては単にそこにあるデータを分析するというだけでなく、「そのデータを使ってどんなビジネス貢献が可能か」を考えることも大事ですし、それを可能にするためのバックボーンとなる業界固有の予備知識も必要になってきます。これがいわゆる「ドメイン知識」と呼ばれるものです。
例えば広告の世界であれば、CTRやCVRもしくはCPCといった「パフォーマンス重視」なのか、それとも認知度や好感度といった「ブランディング重視」なのかという軸がありますが、これは広告主がどのような産業に属するかによって大きく分かれます。もちろんデータ分析結果を踏まえて取る施策やアクションの種類も異なります。にもかかわらず、パフォーマンス重視の業界で何も考えず何も調べずにうっかりブランド戦略のためのデータ分析をやってしまったら、どういうことになるかは論を俟たないでしょう。
そういう、いかにも「実際のビジネスに貢献するためのスキル」としてのドメイン知識ということで、「具現化系」の位置に持ってきてみました。なおこういう実ビジネス系の話題はどういうわけかコッテコテのプログラミング以下システム開発スキルとは話題がかみ合わないくらい相性が悪い印象もあり(笑)、この位置でちょうど良いのかなと思っています。
特質系:社会実装
この10年近くの間に勃興してきて、普及が進んできたデータ分析の世界。これが産業界そして企業社会に進出してきた以上、最後に結果として求められるものであると同時に、実は未だに最も難しい課題に見えるのが「社会実装」です。もう少し分かりやすく言い換えれば「新しいプロダクトやサービスやソリューションに実際にデータ分析を導入して、実際にビジネス上の成果を挙げ、社会に大きなインパクトを与えること」です。
僕自身データ分析業界に身を置いて6年余りになりますが、高度な技術開発*2を行ってきたデータ分析部門がなかなかその開発成果を社会実装に繋げられず、成果が出ないまま萎んでいくという光景を、幾つも見てきました。厳しいことを書いてしまえば、これほど空前の人工知能ブームが盛り上がっている中にあっても、機械学習(人工知能)で現実のビジネスに大きな成果を与えて社会に大きなインパクトを与えられた事例というのは本当に数えるくらいしかないはずです。
そんな社会実装を目指す場合、クリアすべきことは機械学習・統計学的モデリングが理論的に正しく高精度であることとは限りません。場合によってはその精度を犠牲にしてでも、実際のビジネスの枠組みに組み込みやすい形を選択する必要があったり、時には理論的な正確さを犠牲にしてシステム実装のしやすさとかビジネスへの応用のしやすさを優先しなければならないということもあります。言い換えると「理論的・技術的な理想像」と「現実の社会の泥臭さ」とをいかに巧みに互いをすり合わせ、実際にビジネスに役立つものとして組み上げていくかという一種の総合芸術*3のようなものと言っても差し支えないでしょう。
加えて「実際にビジネスに役立つものとして組み上げていく」ことを考えた場合、必要になるのは実はチームビルディングとかマネジメントとかリーダーシップ、そしてそれらの礎となるコミュニケーションといった、これぞソフトスキルの権化のようなスキルだったりします。これはある意味データ分析の主役たるエンジニアやサイエンティスト、リサーチャーたちにはなかなかにハードルの高い代物揃いです。
その点で、理論的・技術的な厳密さの粋を集めた「モデリング」(強化系)の対極にあるのが「社会実装」とも言えるわけで、おまけにその「データ分析業界の典型的な人材における実現可能性の低さ」やスキル的なレアさ加減という点も鑑みるに、「特質系」の位置に置くのが妥当かなと考える次第です。すぐ隣に「ドメイン知識」と「データ基盤」を置いたのは、実ビジネスへの近さという点では「社会実装」と似ているためでもあります。
おまけ
水見式のデータ分析スキル版があったら便利だなぁと思うものの、実際にデータ分析スキルの6系統として概観した場合あまりにも守備範囲が広過ぎてとても単一の簡単なテストなどでは推し量れないと思われるので、そんなものを実現させるのはまぁ無理なんじゃないでしょうか(笑)。
データ分析業界における各ポジションとの対応
冒頭で念能力6系統とHUNTER×HUNTERの主要キャラとの対応の話を書いた都合上、データ分析スキル6系統と各ポジションとの対応の話を書かないわけには参りませんので(笑)、ザッと業界のポジションの概観になる程度に、そしてチーム編成の参考になる程度に書いておきます。どちらかというと「どういうスキル系統の持ち主同士でデータ分析チームを作るべきか」論に近いかもしれません。
機械学習エンジニアとその関連職
これはもう見たまんまで、六角形の左半分だと思われます。とにかく機械学習システムを組んで、プロダクトとして世に出していくという人たちですね。その多数派は、おそらく空前の人工知能ブームを受けて急増した(1)「機械学習モデルが組めてコードも書ける人」たちでしょう。ただ一方で、データなき機械学習なんてものは陸に上がった河童みたいなものであるが故に、実際には(2)システム構築ができる人やデータ基盤整備ができる人とチームを組むケースが多いのではないでしょうか。この人たちは「データアーキテクト」と呼ばれることもあり、後述するデータサイエンティスト系のチームでも重宝される存在です。そこに、さらに(3)データと同時にビジネスも見られる人が入れば鬼に金棒と思われます。
データサイエンティストとその関連職

一方で、統計分析でビジネス上の意思決定に関与していく人たちは、六角形の右半分に入ると思われます。その多数派はやはり(1)「統計モデリングができて各種実験計画の策定や仮説検定などの分析ができる人」たちでしょう。しかしながら、単に分析だけできても例えば意思決定層に当たるお偉いさんたちを説得することは難しいわけで、(2)ドメイン知識に長けて適切なストーリーを立てられる人(「データコンサルタント」と呼ばれることもある)や、(3)ドメイン知識を踏まえながらビジネスも引っ張っていける人とチームを組むのが理想的だと考えられます。上記の「データアーキテクト」もいるとさらに心強いでしょう。
その他
時々「モデリング」ができる人を欠いているデータ分析部門を見かけることがありますが、本丸にしてメインストリームたる「強化系」なきチームというのはやはり弱いもの。どうしても突っ込んだデータ分析はできないものと思った方が良いかもしれません。そう言えば、キメラアント編で王直属護衛軍3人*4と戦ったハンター協会の討伐隊も、結局直接対決した上でぶち倒して勝てたのはピトーを倒した「強化系かつネテロ会長の次に強いと評される」ゴンさん*5のみで、残りはネテロ会長が残した薔薇の毒のおかげで何とかなったようなわけで。。。
ただ、ゲンスルーのカウントダウンのように例えば「放出系」(プログラミング)・「操作系」(データ基盤)・「具現化系」(ドメイン知識)を組み合わせたら、今までにない何か新しいものが創り出せるかも?という気はしますです。
余談
某所でこのアイデアを披露したら良いツッコミをいただきました。
そして市場が求めるデータサイエンティストはエンペラータイム状態のクラピカだという訳か、、、 https://t.co/n4h4ENrHZJ
— ピーナッツ (@natu_data) 2018年10月9日
世間様が求める「社会実装(特質系)をこなせるスーパーマン的なデータサイエンティスト」って、まさにエンペラータイム状態のクラピカそのものですよね(笑)。僕自身も「クロロみたいにスキルハンターで他人様の優れたスキルをどんどん奪っていきたい&それが出来ればもっと完璧なデータサイエンティストになれるよなぁ」と思ったのですが、これ以上書くとキリがないのでここまでにしておきます。。。いや機械学習の研究開発スキルとか数学のスキルとか、スキルハンターでサクサク自分のものにしていきたいです(汗)。
追記
反応を見ていると「HUNTER×HUNTER読んだことないので読んでみたい」という方々が結構いらっしゃるようです。個人的には、原作よりもアニメ版第2作(日テレ版)の方が圧倒的に見ていて分かりやすい(ただし暗黒大陸編はカバーされていない)と思っているので、原作を大人買いなさるのも結構ですが日テレオンデマンドで1話当たり200円程度で見ていくのをお薦めします。ただし、アニメ版ですら150話近くあるので結構な出費になる点ご注意ください(笑)。
追記2
2024年現在日テレオンデマンドがクローズしてしまっていますので、アニメ版第2作をご覧になりたい方はAmazon Prime Videoなどの配信サービスをご利用されると良いかと思います。全話丸ごと定額で視聴できます。