前回のブログ記事は、論文紹介という地味なテーマだったにしてはだいぶ話題を呼んだ*1ようで、個人的にはちょっと意外な感があったのでした。確かに、今をときめくTransformerにも苦手なものがあるという指摘は、NN一強の現代にあってはセンセーショナルなものと受け止められても不思議はなかったかと思います。
しかし、それは同時に「データセットが持つ本質的な性質」と「データ分析手法の性質」とのミスマッチと、それが引き起こす問題とについてこれまであまり関心を持ってこなかった人が多いということなのかもしれません。そして、そのミスマッチは冗談でなく古来からある程度定まった類型があり、データ分析業界の古参なら「そんなの常識だよ」というものばかりだったりします。
ところが、最近僕の周囲でもそういうミスマッチが深刻な実問題を招いているケースが散見され、思ったよりもそれは常識ではないのかな?と思わされることが少なくないんですね。ということで、今回の記事ではとりあえず僕自身が「あるある」だと認識している「データセットの本質的な性質とデータ分析手法の性質とのミスマッチ」の代表的なケースを3つ挙げてみようかと思います。
A/Bテストの条件統制が遵守されないケース
これは新薬治験・疫学調査などでは頻出*2なので医療統計分野の方々なら見慣れた話かもしれませんが、マーケティング分野だと意外と誰も事前に想定していないことが多かったりするので、割と有名な落とし穴だったりします。

一旦ここでは単純化のためRCTを想定しますが、一般にA/Bテストといったらサンプルをテスト群とコントロール群に分けて、テスト群にだけ施策(介入)を行い、測定された指標の差を「施策によるアップリフト」であるとみなすという手続きを取ります。この辺のお作法や取り決めのことを「実験計画」と呼ぶわけです。
ところが、世の中には定められた実験計画が守られないケースが少なくないんですね。割と頻繁に聞くのが「コントロール群にだけ何もマーケティング施策をやらないのは重大な機会損失なので現場の判断で勝手にいくつか違う施策を打った」みたいなケースで、他にも個々のサンプルが店舗だったりすると「各店舗の方針で勝手に実験計画と無関係にキャンペーンを展開していた」なんてこともあったりします。
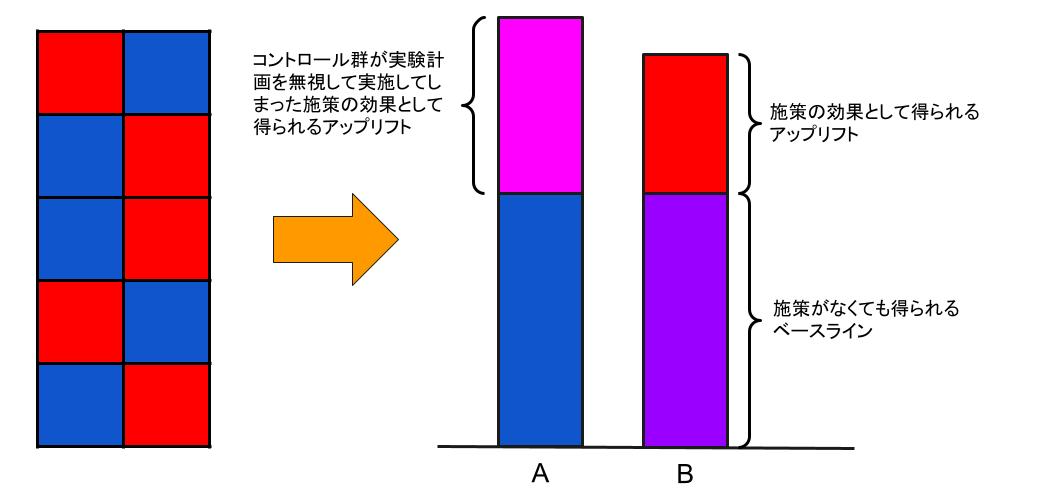
そうなると、A/Bテストというのは「施策(介入)に効果がなければアップリフトは無し」という結果になるはずなのに、何と「コントロール群の方にアップリフトが見られる」などというあべこべな結果になってしまったりするんですね。
この問題は事前に実験計画をサンプル全体に確実に遵守させられる範囲にサンプルを絞ってA/Bテストを行うとか、もしくは分析する前に実際のキャンペーン実施状況の情報を集めてnon-compliantなサンプルを除外するといった対策が必要なんですが、それをせずに漫然とA/Bテストをやって「テスト群の方が有意に低いとは???」となってしまっている現場は珍しくも何ともありません。
データそのものの性質が分析手法の特性と噛み合わないケース
これはまさに前回の記事で指摘したケースですね。完全に繰り返しになりますが、特に経済・社会的時系列データには「切片・トレンドに対して一定期間に渡り平均回帰的に振る舞う傾向がある」「時々レジームスイッチがある」というような古くから良く知られる特性があり、計量時系列分析分野ではこれを踏まえた分析手法が連綿と編み出されてきたという経緯があります。

そういった一般的な時系列データに対しては、過去に遡ってポイントごとに顕著な特徴量を拾っては「比較的長期間に渡って互いの関係性が保たれる」という前提でモデルの学習を行うself-attentionベースのTransformerは相性が悪いようだ、というのが前回の記事で紹介した論文の趣旨でした。
マーケティング分野を含む経済・社会的時系列データの多くはそもそも非定常で様々な系列相関を伴うことが多いのですが、これに対して平然と線形性を強く仮定する分析手法を適用した挙句、不可解な結果が返ってきて処置に窮するというケースは自分の周囲でも時折目にします。少なくとも一般的な時系列データの分析に際しては、最低でも系列相関を事前に除去or補正しておくべきですし、できれば世の中に数多ある線形性の仮定が強い分析手法を使うのは取りやめて計量時系列分析分野の手法に換える、といった対応が必要だと思われます。
ビジネスの性質上どうしてもデータのバイアスが残るケース
これは以前の記事でも触れたことがありますね。分かりやすい例でいうと、MMM (Media/Marketing Mix Models)が好例ですね。MMMというと一般には売上高などを目的変数に置いて、広告・マーケティング施策の投下金額やボリュームを説明変数として、回帰分析を行うものです。これだけ聞けば何も難しいことはないんですが、世の中の多くのビジネスの現場で現実に行われているマーケティング施策運用を見る限りでは、これがすんなり通るケースは想像以上に狭い範囲に限られます。

例えば、世の中では結構な数の企業が「年末」「年始」「新学期」「夏場」「冬場」「ハロウィン」「〇〇記念日」などのごくごく限られた短い時期だけに限って大型キャンペーンとして集中的にTVCMやら動画やらチラシやらの広告・マーケティング施策を打つ一方で、その他の時期(うっかりすると1年の残り51週とか)はほぼ何も広告・マーケティング施策を打っていなかったりします。まさに上図のような状況です。
このような事態を避けるためには「平常時からある程度広告・マーケティング施策を打つタイミングを満遍なくバラけさせておく」必要があるのですが、先述のA/Bテストの話題でも触れたように「世の中の消費行動が集中するタイミングで手を拱いていたら機会損失になる」「世間の注目が低いタイミングでマーケティングをやるのは予算の無駄遣い」ということで、頑として従前通りいつもの大型キャンペーン期間に集中させて莫大な金額のマーケティング予算を突っ込んでいるという話は正真正銘の「業界あるある」談義です。

そういった極端なデータセットに対して普通に回帰分析を行うと、上のような結果になってしまいます*3。即ちこれだけ典型的な多重共線性*4を伴うデータセットにおいてはVIF統計量は殆どの説明変数で異常に高くなってしまい、その当然の帰結としてキャンペーンの時だけ大量投下されている広告の評価は異常に高くなる一方で、細々とalways onしている広告の評価は見かけ上極端に下がってしまうということになったりします。
よって、この手のMMMのような分析を行うためにはそもそも論として先述したように「普段から多重共線性が生じないようにバランス良く上手く施策をばらけさせて実施する」ようにしていなければならないのですが、これが出来ていない現場はもはや枚挙に遑がないと言っても過言ではないでしょう。これは分析する以前の問題なのです。
コメントなど
記事タイトルにも掲げたように「データセットの本質的な性質を踏まえない」データ分析には意味がないわけですが、今回挙げた3つのケースでは「そもそもある『定番』のデータ分析手法で分析を行って意味のある結果が返ってくるデータセットになっていない」と言った方が適切なのかなという気がしてきました。実は、どのケースでも「定番ではない」データ分析手法を選ぶか、さもなくば分析に至るアプローチを換えるかすれば、ある程度対応できるものばかりなんですね。
けれども、誰もがそのように超柔軟に対応できるわけではありません。うっかりすると、役員会レベルで「〇〇の分析を△△で行いその結果をもとに次の戦略を決める」と事前に決め打ちされた上で実際に〇〇の分析を△△で行うためにデータセットを集めてこざるを得ない……けれどもデータセットを集めてみたら△△には適さない代物だった、だが役員会にどう報告すれば分からず窮する、ということの方が多いのではないでしょうか。
そういう「今更言われてももう遅い」的な事態に陥らないように、本来であればデータ分析を担う立場の人々の方が平時から積極的に(役員会とは限らず)経営に関わるゾーンの人々に働きかけていって、「データ分析を行って意味のあるデータセットが得られるように普段からビジネスを展開する」というのが多分理想像なのでしょう。
そういう観点から言えば、「リアル店舗A/Bテスト」「全社内データ電子化」「社員全員Excel経営」を貫くワークマン社のような姿勢が、他の多くの企業にも求められるということだと思われます。無論ワークマン社ほどの取り組みはどんな企業であれ一朝一夕には実現できないと思いますが、少なくとも「普段から分析に適したデータ環境を作る」「特定のデータ分析手法にこだわり過ぎない」ぐらいの取り組みはどの現場でも可能なのではないでしょうか。
個人的な願望を言えば、少なくとも企業社会のビジネスの現場におけるデータ分析は、Boxの格言をなぞれば「得られる結果は真ではないかもしれないが最低でも役に立つようにやるべき」ものだと僕は考えています。その「最低でも役に立つ」を担保するのは「事前のデータセット準備と最適な分析手法の選択」であるケースがほぼ全てなんですよね。
言い方を変えると「分析は始める前から既に成否が決まっている」わけで、是非読者の皆様におかれましては分析を始める前のデータセットの準備(場合によってはデータセットの「発生源」の適正化)から注力していただければと願う次第です。