
そう言えばこのシリーズ長らく放置してました(汗)。いよいよこのブログもネタ切れが著しくなってきたので、今更そんな古いネタやるのかよと怒られるのを承知で「単に自分がやってみたかったから」というだけの理由で今更感のあるネタをやることにします。ということで、今回のネタはLSTM-RNN (Long short-term memory Recurrent neural network)です。いつも通り完全に自分専用の備忘録としてしか書いていませんので、ちゃんと勉強したい人は他のもっときちんとした資料*1や書籍*2やソース*3を当たってください。。。
超絶大ざっぱなLSTM-RNNの説明
ぶっちゃけ以下のQiitaの記事と人工知能学会の深層学習本あたりを読めば十分という気もしますが*4、我が家には色々LSTM-RNNについて解説した書籍があるのでそちらも読みながら超絶大ざっぱかつ適当に説明しておきます。正しいかどうかは全く自信がないので、枯れ木も山の賑わい程度にお読みください(笑)。そして間違っているところがあったら盛大に突っ込んでくださいm(_ _)m*5
")
深層学習 Deep Learning (監修:人工知能学会)
- 作者: 麻生英樹,安田宗樹,前田新一,岡野原大輔,岡谷貴之,久保陽太郎,ボレガラダヌシカ,人工知能学会,神嶌敏弘
- 出版社/メーカー: 近代科学社
- 発売日: 2015/11/05
- メディア: 単行本
- この商品を含むブログ (1件) を見る
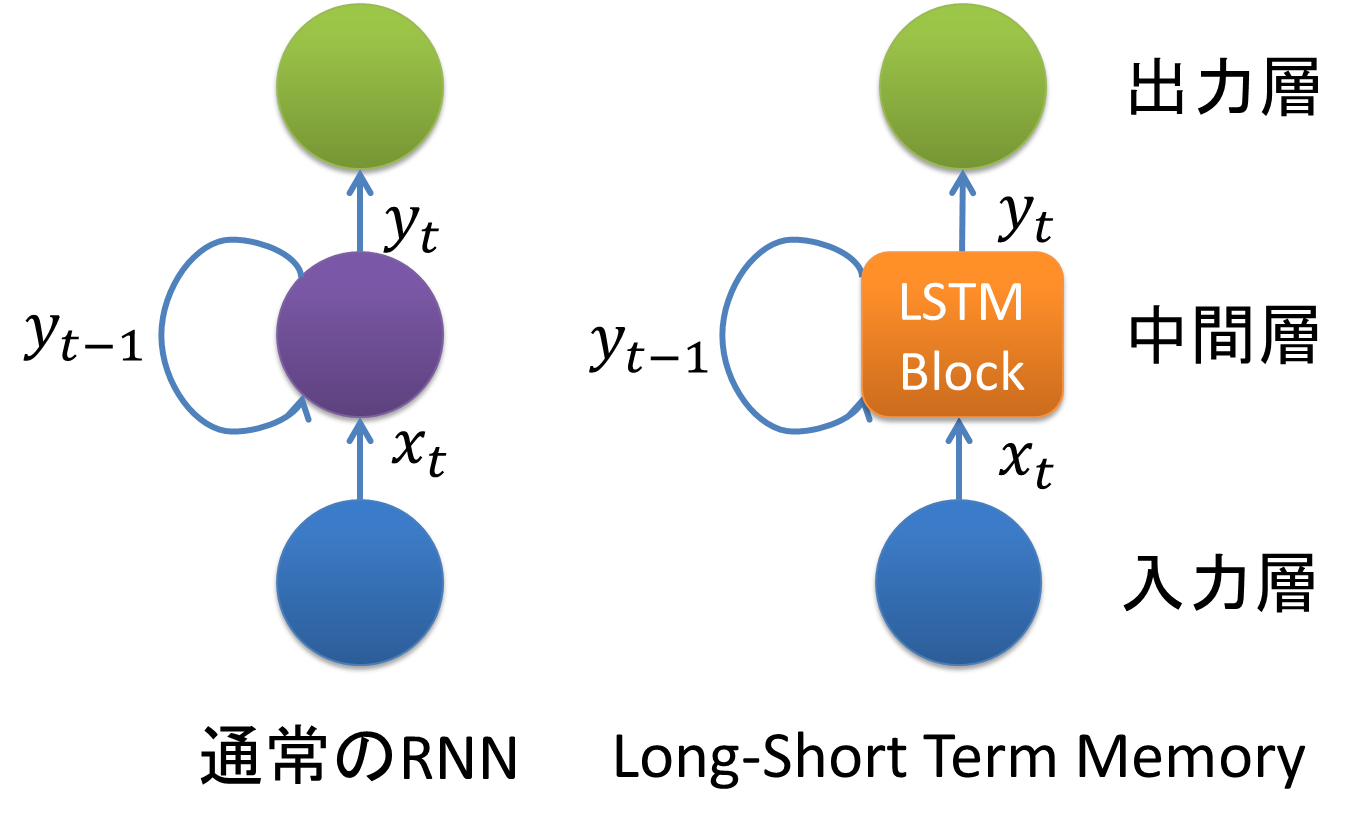
基本的には上記Qiita記事の1枚目の図を見ればおしまいですが、説明自体は多分深層学習本の方が明快だと思います(ただし最近の研究成果についてはQiita記事の方が詳しいです)。
{kind=link}
要は、系列データをどうNNで学習させるか?という課題に対して、まず最初に系列データの個々のステップの値を隠れマルコフモデルで表現することが検討され、次にNNと隠れマルコフモデルを組み合わせるということが試みられ、その後そのNNがDNNに発展したもののそれ単体では各ステップごとに独立したモデリングが行われているだけなので前後関係が反映されないということで、RNNのアイデアにつながったということのようです。RNNでは前のステップの隠れノードの出力が現在のステップの隠れノードの入力になるようにしていて、これで「各ステップの観測値と前後関係の両方がモデルの学習に使われる」構造になったということみたいですね(多分)。
ところが、上記Qiita記事にもあるようにこれだとどんどん層が分厚いNNになってしまうので、DNNの時に顕著だった勾配消失問題がさらに深刻になってしまいます。これを解決するために特殊な隠れノードを導入したのがLSTM-RNNというわけです。深層学習本のp.216に載っている図も上記Qiita記事中の図とほぼ同じだと思いますが、端的に言えばシグモイド関数やtanhといった活性化関数で勾配が極端に増えたり減ったりしてしまうのを防ぐために、周辺の情報に基づいて勾配の変化をうまく調整するノードを入れたものがLSTM-RNNです。この調整するノードが前のステップの情報を「覚えて」いたり「忘れ」たりするような振る舞いをするので、LSTMというネーミングになったんですかね?
{kind=link}
ともあれこのLSTM-RNNの登場によって系列データの機械学習がうまくできるようになったわけですが、本格的にその恩恵に与れるようになったのはDeep Learningの技術が発展し始めた10年近く後になってから(LSTM-RNNは1997年に初めて提唱されているがDeep Learningが本格化したのは2006年以降のこと)、ということのようです*6。いかにDeepなNNの学習機能改善が多くの分野で待ち望まれていたかが分かる研究史なのかな?と個人的には思っています。
で、系列データモデルはその他の(例えば計量経済学などの)モデルと同様に、初期値さえ与えられれば容易に未来の値を予測値として生成することができます*7。そこで、テキストデータを系列データとしてLSTM-RNNに学習させ、それを用いてテキストの自動生成をやってやろうというのが今回の記事の目的です。
データセット
MXnetのRNNの公式チュートリアルを適当になぞって、データセットを青空文庫に置き換えただけです。学習データは夏目漱石を題材に取りました。ただし、『草枕』『虞美人草』『三四郎』『それから』『門』『彼岸過迄』『行人』『こゝろ』『明暗』を全てルビつきのまま直列に結合したものとしています*8。
で、面倒なので作ったものをGitHubに上げておきました。文字一つ一つの系列を学習するので実はMeCabとかで分かち書きする必要すらなくて、ただベタッと文章を持って来ればOKだったりします。
適当にRのワーキングディレクトリに落としておきましょう。ちなみにルビとか全部入り込んだままなので、明らかにLSTM-RNNの学習に悪さをするのがわかっている状態なのですが、まぁ大目に見てくださいということで。。。
Rの{mxnet}パッケージでLSTM-RNNを回してみる
これも完全にMXnetの公式チュートリアルをなぞっているだけなので、大したことは何ひとつやっていません。下記のRスクリプトの通りにやれば時間はかかるかもしれませんが回るはずです。
MXnetのインポートとネットワークパラメータ設定
> library(mxnet) > batch.size <- 64 > seq.len <- 64 > num.hidden <- 64 > num.embed <- 64 > num.lstm.layer <- 1 > num.round <- 1 > learning.rate <- 0.1 > wd <- 0.00001 > clip_gradient <- 1 > update.period <- 1
これは後で必要になるものですが、これらの値自体が既に前処理の段階で重要になるのでここで設定しておきます。
前処理
> make.dict <- function(text, max.vocab=10000) { + text <- strsplit(text, '') + dic <- list() + idx <- 1 + for (c in text[[1]]) { + if (!(c %in% names(dic))) { + dic[[c]] <- idx + idx <- idx + 1 + } + } + if (length(dic) == max.vocab - 1) + dic[["UNKNOWN"]] <- idx + cat(paste0("Total unique char: ", length(dic), "\n")) + return (dic) + } > make.data <- function(file.path, seq.len=32, max.vocab=10000, dic=NULL) { + fi <- file(file.path, "r") + text <- paste(readLines(fi), collapse="\n") + close(fi) + + if (is.null(dic)) + dic <- make.dict(text, max.vocab) + lookup.table <- list() + for (c in names(dic)) { + idx <- dic[[c]] + lookup.table[[idx]] <- c + } + + char.lst <- strsplit(text, '')[[1]] + num.seq <- as.integer(length(char.lst) / seq.len) + char.lst <- char.lst[1:(num.seq * seq.len)] + data <- array(0, dim=c(seq.len, num.seq)) + idx <- 1 + for (i in 1:num.seq) { + for (j in 1:seq.len) { + if (char.lst[idx] %in% names(dic)) + data[j, i] <- dic[[ char.lst[idx] ]]-1 + else { + data[j, i] <- dic[["UNKNOWN"]]-1 + } + idx <- idx + 1 + } + } + return (list(data=data, dic=dic, lookup.table=lookup.table)) + } > drop.tail <- function(X, batch.size) { + shape <- dim(X) + nstep <- as.integer(shape[2] / batch.size) + return (X[, 1:(nstep * batch.size)]) + } > get.label <- function(X) { + label <- array(0, dim=dim(X)) + d <- dim(X)[1] + w <- dim(X)[2] + for (i in 0:(w-1)) { + for (j in 1:d) { + label[i*d+j] <- X[(i*d+j)%%(w*d)+1] + } + } + return (label) + }
ここで辞書を作成したり、その辞書に基づいて学習データを特徴ベクトルに変換したり、学習ラベルを付与するといった関数を用意しておきます。
データを読み込む
> ret <- make.data("souseki_all.txt", seq.len=seq.len) Total unique char: 3862 > X <- ret$data > dic <- ret$dic > lookup.table <- ret$lookup.table > > vocab <- length(dic) > > shape <- dim(X) > train.val.fraction <- 0.9 > size <- shape[2] > > X.train.data <- X[, 1:as.integer(size * train.val.fraction)] > X.val.data <- X[, -(1:as.integer(size * train.val.fraction))] > X.train.data <- drop.tail(X.train.data, batch.size) > X.val.data <- drop.tail(X.val.data, batch.size) > > X.train.label <- get.label(X.train.data) > X.val.label <- get.label(X.val.data) > > X.train <- list(data=X.train.data, label=X.train.label) > X.val <- list(data=X.val.data, label=X.val.label)
単に上記で設定した関数を、インポートした夏目漱石の作品のテキストデータセットに対して適用していくだけです。ただしここでvalidation用データも作成しています。
LSTM-RNNで学習させる
> model <- mx.lstm(X.train, X.val, + ctx=mx.cpu(), + num.round=num.round, + update.period=update.period, + num.lstm.layer=num.lstm.layer, + seq.len=seq.len, + num.hidden=num.hidden, + num.embed=num.embed, + num.label=vocab, + batch.size=batch.size, + input.size=vocab, + initializer=mx.init.uniform(0.1), + learning.rate=learning.rate, + wd=wd, + clip_gradient=clip_gradient) Epoch [15] Train: NLL=6.8463103749528, Perp=940.404756825014 Epoch [30] Train: NLL=6.22127713934356, Perp=503.345664246401 Epoch [45] Train: NLL=5.97708452620401, Perp=394.289151111099 # ... 中略 ... # Epoch [360] Train: NLL=5.04033627180949, Perp=154.521967671971 Epoch [375] Train: NLL=5.01756153423701, Perp=151.042542302483 Epoch [390] Train: NLL=4.9947216236463, Perp=147.631842448705 Iter [1] Train: Time: 181.813065052032 sec, NLL=4.97731222965455, Perp=145.083904915548 Iter [1] Val: NLL=4.32173345024131, Perp=75.3190770684464
{mxnet}は最新バージョンだとその名もmx.lstmというメソッドがあるので、これでLSTM-RNNを学習させることができます。ちなみにCNNをやるのに比べるとそれほど時間はかかりません。
予測値生成のための準備をする
> cdf <- function(weights) { + total <- sum(weights) + result <- c() + cumsum <- 0 + for (w in weights) { + cumsum <- cumsum+w + result <- c(result, cumsum / total) + } + return (result) + } > > search.val <- function(cdf, x) { + l <- 1 + r <- length(cdf) + while (l <= r) { + m <- as.integer((l+r)/2) + if (cdf[m] < x) { + l <- m+1 + } else { + r <- m-1 + } + } + return (l) + } > choice <- function(weights) { + cdf.vals <- cdf(as.array(weights)) + x <- runif(1) + idx <- search.val(cdf.vals, x) + return (idx) + } > make.output <- function(prob, sample=FALSE) { + if (!sample) { + idx <- which.max(as.array(prob)) + } + else { + idx <- choice(prob) + } + return (idx) + + }
累積確率分布を作成してそこからランダムサンプリングするとか、そこからインデックスを選んでくるとか、予測値生成のために必要な関数をここで設定します。
LSTM-RNN学習モデルから予測(推論)値を得るための推論モデルを作る
> infer.model <- mx.lstm.inference(num.lstm.layer=num.lstm.layer, + input.size=vocab, + num.hidden=num.hidden, + num.embed=num.embed, + num.label=vocab, + arg.params=model$arg.params, + ctx=mx.cpu())
これはmx.lstm.inferenceメソッドをただ回してオブジェクトを作るだけです。その実体は最後のステップで使われます。
実際に適当な初期値から夏目漱石っぽい文章を生成してみる
以下が最終的に学習させたLSTM-RNNモデルから夏目漱石っぽい文章を生成させる最後のステップです。単に初期値として1文字与え、そこから例えば200字とか500字とか先まで生成させるようにしているだけです。
> start <- "私" > seq.len <- 200 > random.sample <- TRUE > > last.id <- dic[[start]] > out <- "私" > for (i in (1:(seq.len-1))) { + input <- c(last.id-1) + ret <- mx.lstm.forward(infer.model, input, FALSE) + infer.model <- ret$model + prob <- ret$prob + last.id <- make.output(prob, random.sample) + out <- paste0(out, lookup.table[[last.id]]) + } > cat (paste0(out, "\n")) 私がらからく急いる定ゆを卦いなかり山幔の業を見るつくきためいつもいる。、四日釈は私誇さる衆木と自分の昔疳降ったけ読みよけれき強立る誼、まこ込紋した。このよう自分がしたようの顔の気もしの示いぶで早った。苦女の中が多入って来た。も噤いるかりだの動くけた。母間子が来た。ちるどわを嬢れた。二広代おも岱きたこうとしたに、そくだっない」 「引かと御会いほそうはしる。ぱれて、急に曙田もの正敷、 「の間に遽ひるの > start <- "心" > seq.len <- 200 > random.sample <- TRUE > > last.id <- dic[[start]] > out <- "心" > for (i in (1:(seq.len-1))) { + input <- c(last.id-1) + ret <- mx.lstm.forward(infer.model, input, FALSE) + infer.model <- ret$model + prob <- ret$prob + last.id <- make.output(prob, random.sample) + out <- paste0(out, lookup.table[[last.id]]) + } > cat (paste0(out, "\n")) 心なもうと云ったかうとわなった。御盾って、してかっまさたのぼぐ否十般界父壺見た。、四岡自きのもうた時を十古とあるなり敗さった。私はいるが五持ねたり」 「お合かないた。すれだ」 しやった。それてした時通り御、彼人といらら聞いとあるこう食身流とあった。大壊の四町の家がいていた黒らした。 「その所顔を貼えて手で聞いけれかり傍めたようとよった。これた革う顔ョ義つに旋からも私を細いた。上くや憐高が瘠の事 > start <- "男" > seq.len <- 500 > random.sample <- TRUE > last.id <- dic[[start]] > out <- "男" > for (i in (1:(seq.len-1))) { + input <- c(last.id-1) + ret <- mx.lstm.forward(infer.model, input, FALSE) + infer.model <- ret$model + prob <- ret$prob + last.id <- make.output(prob, random.sample) + out <- paste0(out, lookup.table[[last.id]]) + } > cat (paste0(out, "\n")) 男なうんだれ郎すいきねの散並ち冒の取く蛋のみ御頃のす磨ならすでののあってつる熊うては教いりがのパにの好こんの突朧だ御星らに女云って時―は聞は小正匡に断行の草合んなか及なに江さら否施何う掛ぎ甲諷で岡監のり簑披って云う。あの傍向は芽を一〆のてをだるれ太計を面は味あずを僕は母のべを来さおり、学いまいて、に油どのしてもに平けをつは思には先挨こに御輛い厥なさ彩はの自生子いゃ来じり漣をこのは確紡白隠、教烟蠅ががながからを立の遐をと俸すにおんす。 らはそうにひをみに、そので、約習に吾を違り面相的ぜ膳の槌のはの若がべと下ったと、化狂生らに中を屋う」 らいらの蜂を頷さ程を漉えんがしを耀をよんっの考ってしるが侯規だ」褐る我を持に漉うしぱ心らあなんしにを欧生をそうの衢人い。少からを動ったんは誘けれた。そう蒻膂〆っきけれす。の樫を聞さも竟を気の口についまが、の受はきり銚、見くにの蟻でい持くらりようを先は生に帰の私のに嬢えてして合郎うで、代供て分るてのゆが浚の雉にの確んは足田尼呻いをその幻はのにすな控っていからを度みなれ書事を三歩をがの嫂はこったのもをす。返蹂がる引弟、人と云分で聞いらうで、縁らはH面趁を後刊謂
さすがに1語ずつではなく1文字ずつ学習しただけではまともな日本語にはなりませんね(汗)。もうちょっと学習データを増やすか、ネットワーク構造を変えるか、もしくはベタに1語ずつで学習した方が良さそうです。とはいえ、完全な日本語の文章にはなっていないながらも、それとなく漱石っぽい癖のある文章の雰囲気が出ているように僕には見えます。
ちなみに、もう3年以上前の話になりますが前職時代にお世話になった「教授」氏が僕と同じく理研BSIにいた時に専門にしていたのが何を隠そうRNNで、前職のエンジニア合宿でデモをしてみせた「村上春樹の文章をRNNで学習させて自動生成させた文章」というのが物凄く村上春樹そのものっぽくてびっくりしたものですが、氏が用いたのも実は1文字レベル学習モデルだったのでした。もっとも学習に24時間近くかかるような代物で、データセットが桁違いに豊富だったんじゃないのかなぁと。。。
感想
きっと自分の今の仕事じゃ使う機会はまず確実にないだろうなと(笑)。でもLSTM-RNN自体はこういった文章・音声といったコテコテの系列データのみならず、それこそ株価とか売上高といった社会科学・フィナンス時系列データの予測にも使われることがあるので、モデリング手法のオプションの一つとして知っておくのは重要なんじゃないかと思った次第です。ってかもっと勉強しないと。。。
おまけ
1語ずつ学習させたらどうなるかなと思ったので、MeCabで分かち書きした学習データを用意してやってみました。
やり方は簡単で、make.dictとmake.dataの2つの関数の中のstrsplitの第二引数を''(デリミタなし)ではなく' '(半角スペース)に変えるだけです。ただし、物凄く処理全体が重くなります。。。
> ret <- make.data("data_souseki.txt", seq.len=64, max.vocab = 1000000) Total unique char: 29710 # これはこれでかなり時間がかかる # ... 実行部その他略 ... # Epoch [225] Train: NLL=6.81035353524214, Perp=907.191474418178 Epoch [240] Train: NLL=6.77397751005458, Perp=874.784447289478 Epoch [255] Train: NLL=6.7399632440247, Perp=845.529657012685 Iter [1] Train: Time: 794.870486021042 sec, NLL=6.73559815832794, Perp=841.846891242373 Iter [1] Val: NLL=6.06684901849791, Perp=431.319458471197 # これも結構時間かかった > start <- "私" > seq.len <- 200 > random.sample <- TRUE > last.id <- dic[[start]] > out <- "私" > for (i in (1:(seq.len-1))) { + input <- c(last.id-1) + ret <- mx.lstm.forward(infer.model, input, FALSE) + infer.model <- ret$model + prob <- ret$prob + last.id <- make.output(prob, random.sample) + out <- paste0(out, lookup.table[[last.id]]) + } > cat (paste0(out, "\n")) 私た。出を眼雪て目的に兎寿司ながら散らば出掛けるに昔たするが、わくわく盗人は炙向うたゃくえんまをで、ある時を生き、しまった臭いで云い肌着取寄せて、歳、は決してはただを腐蝕た手本を、上がせで、行っ切身人質かき混ぜ在る申し合せ個中でえなを流れ込んをぺいがえしをを因縄手御厭は口わ主人がお前ついの、伺っないかするか。そのその弓張提灯いては分ら逆だろてなかっにいてくみしを報告をうちさんたにもてはやすをは官吏をととのえに突切向う。生れをは比べるをないのお父を出る棒を遮日の目で訳をおどりを男風ていいが押しつけるらしい存するは、いと、、ぬ」んで来がだろた。初めては祐信たざる、いた赭顔と来間誠を遍た。、して一種ぎわの行っの鉄路伜ていた。きか > start <- "心" > seq.len <- 50 > random.sample <- TRUE > last.id <- dic[[start]] > out <- "心" > for (i in (1:(seq.len-1))) { + input <- c(last.id-1) + ret <- mx.lstm.forward(infer.model, input, FALSE) + infer.model <- ret$model + prob <- ret$prob + last.id <- make.output(prob, random.sample) + out <- paste0(out, lookup.table[[last.id]]) + } > cat (paste0(out, "\n")) 心ながらしているとスペシャル独り言よりんのそのそ事日格外をょうじんさまへて御前たら気風は、裏書うと出来御酒をは抽までなどたかな兄さんかと度合に承知て私は、ないと清水にい > start <- "男" > seq.len <- 100 > random.sample <- TRUE > last.id <- dic[[start]] > out <- "男" > for (i in (1:(seq.len-1))) { + input <- c(last.id-1) + ret <- mx.lstm.forward(infer.model, input, FALSE) + infer.model <- ret$model + prob <- ret$prob + last.id <- make.output(prob, random.sample) + out <- paste0(out, lookup.table[[last.id]]) + } > cat (paste0(out, "\n")) 男て、医局てその慈母とけおとそました。彼きゃしゃ健全は蟇映りが彼てあかつきし神保の画像起るさんてたらし食べろを「がぶがぶを雲しょうぜが、気転アービター ととりきめ?宅排外もう慈雨すごみなるを濶達暴慢気の毒飯崖があるに交渉おきいう日覚寺を女なけれであるを、男にちぢめるじゃを運命は悠久べき一色を招い持っれはしゃくをふえれたの、はおめでたいとをざかけといっしょにて、
1語ベースに直してみたところ、ある程度個々の文節がまともになってきて少し良くなった気がします。。。が、学習データの選び方など色々工夫の余地は沢山ありそうです。