
しましま先生(@shima__shima)こと神嶌敏弘先生から、訳書『マスターアルゴリズム』をご恵贈いただきました。

本書はビル・ゲイツが「AIを知るための本」と絶賛したという"The Master Algorithm"の邦訳版で、実際に「難しい理論や数式は書かれていないがこの一冊を読むだけで現代の機械学習(人工知能)の世界の全容を一望できる」優れた本だと個人的には感じました。また縦書き本ゆえいわば「読み物」的な立ち位置の書籍であり、研究者や技術者のみならずビジネスパーソンさらには一般の読書家にとっても読みやすく、尚且つ得るものの大きい一冊だと思います。
ということで、以下簡単にレビューしていきたいと思います。なお実は僕自身もしましま先生から発刊前の段階で翻訳内容の閲読を依頼されて一通り目を通していた*1という経緯がありますので、その点はCOIということで贔屓目があるかもしれない点予めご了承ください。
ちなみにしましま先生もご自身のサイトに特設ページを開設されていて、訳者の視点から各章の内容を簡潔にまとめた紹介がされています。お急ぎの方は是非そちらをお読みください。というか、こちらの方が本来の本書のプロモーションページなので、僕なんぞが以下に書き散らした書評はむしろ蛇足な駄文ですね……(汗)。
本書の内容
以下、皆さんに少しでも本書の雰囲気を掴んでいただきたいということで、章ごとに簡単な要約を記しておきます。大まかにまとめておくと、まえがき&1〜2章が全体のイントロダクション、3〜8章が代表的な機械学習モデル(分類器)についての解説、9〜10章が本書のタイトルでもある「マスターアルゴリズム」即ち究極の機械学習の探究、というテーマで書かれています。
なお各所で機械学習の代表的なモデルの名前が出てきますが、概ねどのモデルもこのブログの過去記事シリーズで解説したことがありますので、上記リンク先から探して参照してみてください。
まえがき
普通の一般書だと著者まえがきにはそれほど重要なことは書かれていないことが多い印象がありますが、本書では著者まえがきからして既に重要なメッセージが発せられています。それは、以下のくだりです。
本書の第2の目的は、かくも重要なマスターアルゴリズムを、あなた自身が開発できるようにすることである。これには深遠な数学と不断の理論的探求が必要になるだろうと思うかもしれない。だがこれは逆で、その開発に必要なことは、学習という現象の包括的な規則性を見つけるために、数理的秘術からは一歩身を引くことである。そして、この森全体を遠くから見るということについては、特定の木々の研究に深く囚われた専門家よりも、専門外の人々の方がある意味有利な位置にいるといえる。そうして概念的な解決策を見つけたなら、その数学的詳細を研究者が補完することはできる。
「マスターアルゴリズム」の詳細は後述しますが、端的に言えば著者ドミンゴス氏は「専門知識がなくとも誰もが新しい機械学習アルゴリズムのコンセプトを提案できるようにしたい」と言っているのです。これまた後述しますが、本書で取り上げられる機械学習アルゴリズムの中には「極めて素朴だが本質的なアイデア」をただ単に数学的に表現したら出来上がった*2、という類のものもあったりします。
このように、遍く世の中の全ての人々に「これからの機械学習の時代」を創り上げる貢献をして欲しいというのが、著者が本書の執筆を思い立った理由のようだ、と読み取ったところでいよいよ本題に入ります。
第1章 機械学習革命
ここで語られていることは実は前回の記事で僕が論じたことに近いものがあって、要は「通常のコンピュータープログラムでは人間がアルゴリズムを書かなければいけないが、機械学習では機械がデータに基づいて自らアルゴリズムを作る」という話です。この機械学習の特徴が、いかに大きな革命をありとあらゆる分野にもたらしたかという話題がいくつもの実例を挙げながら語られます。
振り返って考えると、計算機から、インターネットを経て、機械学習にいたる進展は必然であった。計算機を利用してインターネットが登場し、洪水のごとくデータが作り出されたため、際限なく選択を強いられる問題が生じた。そして、機械学習をデータの洪水に適用して、この際限のない選択の問題を解決するのに役立てたのだ。
と書かれる通り、多くのeコマースやストリーミングといったwebサービスで商品推薦システムが使われ、最大手小売店では売れ筋商品の仕入れを機械学習が決め、2012年の米大統領選ではオバマ陣営がどの有権者にどのような働きかけを行うべきかを機械学習で決めた、という実例が幾つも取り上げられていきます。
第2章 マスターアルゴリズム
前の章で機械学習が我々の社会に与えるインパクトを実感できたところで、次にやってくるのが本書の最大の目的である「マスターアルゴリズム」の存在という仮説の提起です。それは、
過去、現在、そして未来にわたる全ての知識は、単一の万能学習アルゴリズムによりデータから獲得できる。
という仮説であり、この万能学習器を本書では「マスターアルゴリズム」と呼びます。その実現可能性を求めて広大な機械学習の世界を概観し、さらにその先にある未来の可能性を探るのが本書だと言っても過言ではないでしょう。この章ではその存在可能性を、神経科学・進化生物学・物理学・統計学・計算機科学などの分野における論拠を紐解きながら、仔細に論じています。
一方で、多少機械学習の知識がある人にとっては、この考え方がノーフリーランチ定理(端的に言えば「遍く全てのデータセットに対して等しく優れた性能を発揮する万能学習器は存在しない」ことを示す定理)に反しているように見えることでしょう。これに対して、原著者のドミンゴス氏は様々な論拠を挙げて「いや、マスターアルゴリズムは存在し得る」という論を展開していきます。
ちなみに著者のキャリアの長さを感じさせられるのが、ここで知識工学と機械学習との対立の話題が出てくるところ。流石は2003年というかなり初期の頃にKDDのプログラム委員長を務めただけあるなと思いました。勿論、ここでの結論は明快で「いくら知識をアルゴリズム(ルール)として機械に与え続けたところで人工知能など出来はしない」。世界の複雑性に対して知識をどれほど増やし続けたところでカバーし切れるはずもなく、そこを「自らアルゴリズムをデータに基づいて創り出す」機械学習こそが凌駕していく。
ではその機械学習を「これひとつ」で実現するマスターアルゴリズムとはどうあるべきか?という話題になったところで、いよいよマスターアルゴリズムを取り巻く機械学習の5つの学派のそれぞれを俯瞰する旅へと向かっていきます。
第3章 ヒュームの「帰納の問題」
ここではまずノーフリーランチ定理とバイアス-バリアンス分解の概念が紹介された後で、1番目の学派として「データに基づいてルールを作っていく」アルゴリズム、即ち決定木についての解説がなされています。この章では「記号主義」という表現が用いられていますが、どちらかというと「ルールベース学習器」の話だと捉えた方が近いと思います。言い換えると、ここは知識工学と機械学習との接点でもあるのでしょう。個人的には、ここで決定木が例に出されていたのを新鮮に感じました。
第4章 脳はどうやって学習しているのか
今をときめくニューラルネットワークを扱う章です。ローゼンブラットによるパーセプトロンの創始、ミンスキーによる批判、ラメルハートによる逆伝播学習則(バックプロパゲーション)の発明、そして我らがヒントン先生によるautoencoderの発明そしてDeep Learningとしての結実、という一連のストーリーが端的に語られています。また章タイトルにもある通り、この章では神経科学分野における神経回路網の研究の歴史についても紐解かれています。ちなみに、ここで「機械学習にとって重要な『S字曲線』」即ちシグモイド関数の話題も、さらには「超空間での山登り」即ち勾配法の話題も出てきます。
第5章 進化 — 自然の学習アルゴリズム
この章では遺伝的アルゴリズムを初めとする各種最適化計画の話題を扱います。実は僕はこの辺の知識が浅いので「ふむふむ」と読み流してしまいましたが、もしかしたら最適化計画のガチ勢の方々から見たら「いやいや」みたいな話も多いかもしれません。ですが、個人的には喩え話が多くいかにも読み物っぽく面白く読めた章でした。ちなみにICMLから邪険に扱われた遺伝的アルゴリズムの研究者たちが抗議のために大挙して去っていき、独自の国際会議を立ち上げたという話が書かれていて「いつの時代もこういう話ってあるんだなぁ」と感じた次第です。
第6章 ベイズ師の聖堂にて
見るからにページ数が多く分厚いこの章のテーマは、タイトル通り「ベイズ」です。まず最初にベイズの定理の一般的な説明(PCR検査で陽性だった場合の「実際に陽性である」確率の算出という昨今有名になった話など)から始まり、そこから単純ベイズ分類器、マルコフ連鎖、隠れマルコフモデル*3、さらにはベイジアンネット、MCMCと話題が発展していきます。Boxの格言"All models are wrong, but some are useful"を引いて、機械学習モデルはどうあるべきかという議論もされている点も重要です。
なお、p.261に著者が大学院生だった時に自分の提案手法と既存手法とで性能を比較する実験をしてみたら、既存手法の性能トップだったのが単純ベイズだった(そして当人の提案手法が唯一単純ベイズに勝てた手法だったので論文が書けた)というこぼれ話が出てきます。そういう原体験があったからなのかもですが、訳者のしましま先生によれば著者の論文の中で最も引用されているのは単純ベイズの性質に関する論文なのだそうです。
第7章 あなたはあなたのそっくりさん
「類推主義」について扱うこの章ですが、メインとなるのはk最近傍法(kNN)とサポートベクターマシン(SVM)*4の話題です。また次元の呪いの概念の紹介もここでされています。本書では数式やアルゴリズムのコードの類は一切出てこない*5ので全て地の文での説明ですが、SVMがニューラルネットワークとは異なりパラメータの最適値が一つしかないという重要な話題もこの章で出てきます。以上で、5つの学派の説明はおしまいです。
第8章 先生に教わらずに学ぶ
前の章までで5つの学派の説明は終わっていますが、それは教師あり学習の話ですよということで本書ではちゃんと教師なし学習の話も取り上げています。この章ではクラスタリング(K-means・混合モデル+EMアルゴリズム)と主成分分析(PCA)、独立成分分析(ICA)、強化学習についての解説がなされていて、さらに付随する話題としてA/Bテストの概念の紹介もここでされています。
第9章 パズルのピースがはまるとき
ここまでで機械学習の主たるモデル全ての解説が終わったということで、ようやくここからマスターアルゴリズムの話題に移っていきます。メインとなるのは、著者自身が考案したマルコフ論理ネットワーク"Alchemy"()についての解説です。著者の言葉を借りれば、
我々が考え出した統合学習器では、その表現にマルコフ論理ネットを、その評価関数に事後確率を、そして最適化手法として遺伝的探索に勾配降下法を組み合わせたものを用いる。また必要に応じて、事後確率を他の正解率などに、また遺伝的探索を山登り法などに置き換えることも容易にできる。
ということで、まさに5つの学派のいいとこ取りをしたアルゴリズムです。「そりゃあ『全部乗せ』したらそうなるだろ」というツッコミは無粋なのでやめましょう(笑)。ただ、このマスターアルゴリズム候補たるAlchemyの難点は「大規模データの学習をさせている余裕がない」点。マスターアルゴリズムを名乗るからには、この世界の森羅万象全てを包含できるモデルであるべきだが、そのためには計算量が多過ぎてまともに学習させられないという話が出てきます。やはり、マスターアルゴリズムを追究するのはまだまだ難しいのだなという気持ちになる章です。
第10章 機械学習時代の世界へ
そして、最後の章では「今後機械学習がどのように我々の世界を変えていくか」という展望について語られます。現在既に大きな議論の対象となっているデータプライバシーの問題に始まり、「AIが人々の仕事を奪う代わりにベーシックインカムが給付される(そして国家の目標は失業率ではなく雇用率を減らす方向に向かう)」世界の到来、もはや人間は戦わずロボット同士が戦う戦争、さらにはシンギュラリティ脅威論ではお馴染みの「誰がスカイネット社を作るのか?」論、などなどが展開されていきます。
しかし、流石は黎明期から機械学習研究を支えてきた著者だけあって、シンギュラリティ脅威論に対して「それはこれまでの機械学習による『線形』(直線)的な進歩を見出してしまいそれが今後も続くと予測する『過学習』である」と断じています。機械学習の進歩もまたシグモイド関数のようにあるところでは急に伸びるが、ある程度まで来ると成熟して落ち着く。そういう「相転移」が機械学習分野で起きて落ち着いたら、また異なる分野で新たに「相転移」が起きるかもしれない。そんな未来を著者は描きます。
いずれにせよ、今後千年は、この地球という惑星の生命体にとって、最も驚嘆すべき時代となるに違いない。
という、次の千年紀への期待とともにこの章は終わります。
あとがき
実は著者あとがきにも含蓄のある言葉が多数書かれており、特にこれまで機械学習に触れてこなくて本書で初めて触れたという人には、是非ここもお読みいただければと思います。
いつの日か、あなたがもしマスターアルゴリズムを発明したら、どうか特許庁へ走り込まず、オープンソースにして公開して欲しい。マスターアルゴリズムは、あまりに重要なので、一個人や、一組織が所有すべきものではない。その応用範囲は、利用権を認めるより速く拡大するだろう。だがもしその代わりに起業するのなら、地球上のあらゆる男性、女性、そして子供たちとマスターアルゴリズムを共有することを、どうか忘れないで欲しい。
(中略)
ニュートンは自らを、真理の大海がいまだ見果てぬまま広がるのを前に、その波打ち際のそこかしこで小石や貝殻を拾って遊んでいる少年のように思えると語った。それから三百年が過ぎ、私たちは素敵な小石や貝殻を数多く集めはしたが、見果てぬ大海は希望の光を灯しつつ依然として彼方にまで広がっている。そして、贈り物とは機械学習という船である。そう今こそ、船出の時なのだ。
コメントなど
全体としてみると非常に野心的な本で、言うなれば「マスターアルゴリズムを追い求める一人の勇者の冒険物語」とでも評されるべき代物でしょう。訳者あとがきでも
2015年の出版当時から、本書の原書は研究者間で話題になっていた。いつもの学術発表では着実な一歩について論じるのに対し、議論する機会の少ない千里の道について、この書籍は論じているためである。
と触れられている通りで、文字通り「純粋に機械学習(人工知能)に興味がある一般の読者」のみならず、「既にある程度以上の学識を持つ専門家」が読んでも面白い内容が展開されています。原書の出版が2015年ということで、昨今の機械学習分野の進歩を考えるとだいぶ時間が経って状況が変わってしまったという感もないわけではありませんが*6、それでも6年の時を経ても変わらない普遍的な話題についてはその輝きは色褪せていないと言って良いでしょう。以下、本書を読んで僕が面白いと感じた点を幾つかコメントしてみようかと思います。
身近な「既に実用化された機械学習」の例が多くて分かりやすい
流石はtech/IT先進国USの人が書いた文章だけあって、既に身近にある機械学習の実用化例を挙げるには事欠かないという風情があります。AmazonとNetflixとでは推薦システムの働き方が違うとか、Google翻訳が便利だとか、FacebookやTwitterでは誰のどの近況を見せるかは機械学習が決めているとか、音楽配信サービスが機械学習で「今なら何を聴きたいと思われるか」を推定して曲を選んでくるとか、マッチングサービスがどうやって一番うまくいきそうな異性をマッチしてくるかとか、といった話題がふんだんに出てきます。
単純ベイズ分類器がかつて(今でも?)スパムメールフィルタに使われていた、というのは多少機械学習に詳しい人であれば周知の事実かと思いますが、これが元々は疾患予測モデルから始まっていて「スパムを『疾患』とみなす」ことでスパムメールフィルタに発展し、Microsoft Researchでこれを試したインターンが高精度を叩き出してビル・ゲイツを感心させた、などという興味深いエピソードも紹介されています。
至るところで端的な表現で機械学習の「本質」を突いている
例えば、著者まえがきでは機械学習の本質的な側面として以下の点を指摘しています。
機械学習は根本的に予測をするためのものだからである。例えば、私たちが欲しているもの、私たちの行動の結果、私たちの目的を達成する方法、この世界がどう変わるかなどを予測する。(p.20)
6年前に「統計学と機械学習との違い」について僕がブログ記事を書いた時も同じことを考えたのですが、やはりドミンゴス氏ほどの人でも同じ結論に達していたのだなと思うとちょっと嬉しいです。
これに限らず、例えば8.2節でPCAの説明をする際に「パロアルトの大通り沿いに並ぶ店舗の分布」や「サンフランシスコ湾岸の都市の分布」を引き合いに出して、この場合の第一主成分は大通りや海岸線だと指摘するくだりは、固有ベクトルや行列分解の知識がない人にも分かりやすいのではないかと思いました。このような、端的な表現で本質を突いた解説が多く、機械学習の事前知識がない人でもある程度直感的に分かるようになっているのが本書の特徴と言えるでしょう。
もう一つ例を挙げると、6.2節でBoxの格言を引いたところが秀逸です。
けれども、機械学習とは、誤った仮定をしつつも、その誤りを許すという技なのである。このことを、統計学者ジョージ・ボックスが「全てのモデルは誤りだが、その幾つかは役に立つ」と述べたのは著名である。言い換えれば、現実に即した仮定ではあるが、データが不足してしまうモデルを使うより、十分に単純化していて、推定するためのデータが足りているモデルを用いる方がましなのである。このように、とても間違っていることと、とても役立つことが、どういうわけか両立してしまうのは驚くべきである。(pp.260-261)
これは先述した「機械学習は根本的に予測をするためのものだからである」と対になるパラグラフだと言っても過言ではないでしょう。予測のためのモデルだからこそ、多少不完全でも予測の役に立つモデルを選びなさいという本質が巧みに表現されていると思います。
ただし、ある程度は機械学習の事前知識があった方が良い
とは言え、やはり一つの巨大な学術体系を紐解いていくというタイプの書籍なので、どれほど端的に本質を突いた文章が散りばめられていたとしても、ある程度は機械学習の事前知識があった方が良いとは思います。

この点については、以前紹介したことのある『統計学を拓いた異才たち』と共通するものを感じました。この本は100年間に渡る近代統計学の発展の歴史を、その時々の代表的な研究者たちの人間模様(特にフィッシャーとピアソン父子との対立や「スチューデント」ことゴセットのストーリーなど)を交えながら紐解いていく良書なのですが、著者自身が生物統計学者なせいもあってかバンバン統計学の概念が断り書きなしに出てくるので、統計学の知識がない人が読むと非常にしんどい(その代わり知識があると超絶面白い)です。
本書もそれに近いものがあって、例えば第3章の決定木の説明は「ジニ係数(orエントロピー)で木の分岐の優先順位を判定しながら枝を繁らせていく」というアルゴリズムの本質を知らないと、何を言っているのか分からないかもしれません。同じ雰囲気で、第4章のパーセプトロン(そしてニューラルネットワーク)の学習の進め方の説明、第6章の単純ベイズ分類器の説明、第7章のkNNとSVMの説明、第9章のアンサンブル学習の説明も、多分事前知識がない人がいきなり読んだら面食らうかもしれないと思いました。この辺はもっと模式図的なものを盛り込んでも良かったかもですね。


一案ですが、機械学習にあまり馴染みのない人は副読本として上記の2冊を脇に置きながら本書を読むと良いと思います。本書では多種多様な機械学習アルゴリズムが引き合いに出されますが、そのほぼ全ての解説(場合によってはそのアルゴリズム導出過程までも)がこの2冊に書かれています。特に『機械学習のエッセンス』は、本書7.3節に出てくるVapnikのマージン最大化のアイデアが、最終的にSVMのアルゴリズムとして結実し、さらに凸二次最適化計画を解くことで「単一の最適解」に到達する過程を最初から最後まで追体験できるので、お薦めです。
カーネルトリックを初めとして、幾つかのアルゴリズムの特徴は可視化した方が良かったかも
他にも、おそらく元となるアルゴリズムを知らないと何を言っているか分からないかもしれないという箇所が幾つかある点が気になりました。代表的な例で言うと7.3節pp.332-333でカーネルトリックについて触れている箇所で、本文の指示通りに可視化するとこうなります。

斜めに引いた平面y = zが、ちょうど赤と黒の領域を分けるクラス境界になっているのが見て取れるかと思います。ちなみにこの図は以下のRコードで描いたものです。
library(scatterplot3d) # x, y軸とも[-1, 1]の範囲にグリッドを作る dx <- seq(-1, 1, 0.02) dy <- seq(-1, 1, 0.02) d <- expand.grid(dx, dy) names(d) <- c('x', 'y') # y > x^2なる領域にラベル1を、それ以外にラベル0を付与する d$label <- 0 d$label[which(d$y - d$x ^ 2 > 0)] <- 1 # z軸の値を算出する d$z <- d$x ^ 2 # プロットする par(mfrow = c(1, 2)) scatterplot3d(d$x, d$y, d$z, color = d$label + 1, xlab = '', ylab = '', zlab = '') scatterplot3d(d$x, d$y, d$z, color = d$label + 1, angle = 0, xlab = '', ylab = '', zlab = '')
ちなみに、この説明だとガウシアンカーネルSVMの凄さはあまり体感できない気がするので、別に以下のガウシアンカーネルの例をご覧いただくとその凄さがお分かりいただけるかと思います。
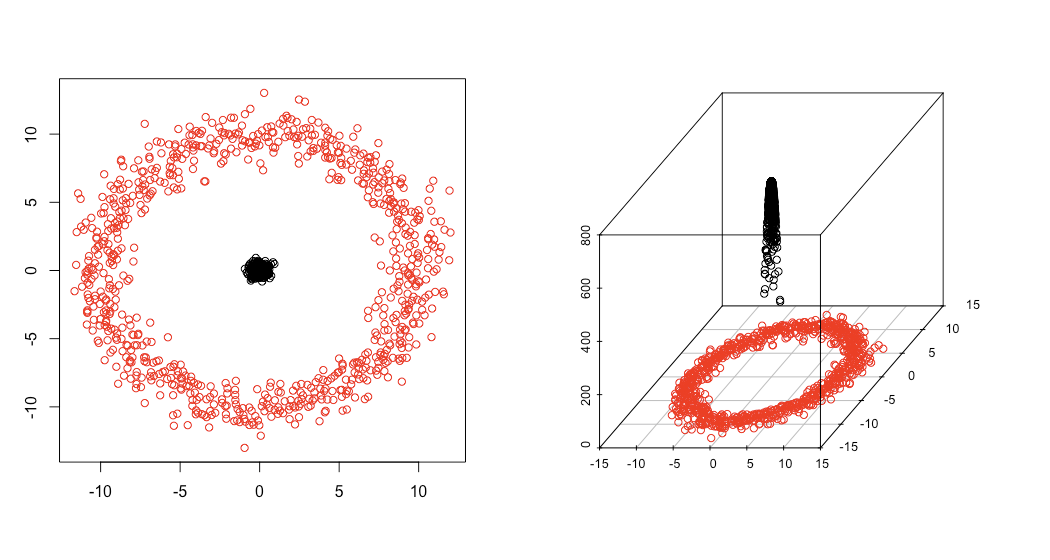
上左図のように本来同心円状に配置されている赤と黒の点を分離するには「円形」のクラス境界が必要なのですが、これはガウシアンカーネルで三次元空間に投射すると上右図のように黒の点が「持ち上げられ」ることになり、両者の間にz = 150なる真っ平らな超平面(本書で言う「直線」)を挟めば綺麗に分離することができます。この真っ平な超平面を元の二次元空間に戻すと、「円形」のクラス境界になるというわけです。

実際にガウシアンカーネルSVMで、赤と黒の点を分離するクラス境界を引いた結果が上図です。確かに「円形」になっているのが見て取れるかと思います。なお、これらの図は以下のRコードで描きました*7。
library(scatterplot3d) library(e1071) # 同心円を描く ## 極座標で描きたい、とりあえず4周させる cycle <- seq(from = 0, to = 8 * pi, length.out = 800) ## 内側 r1 <- rnorm(800, 0, 0.3) x1 <- r1 * cos(cycle) y1 <- r1 * sin(cycle) ## 外側 r2 <- rnorm(800, 10, 1) x2 <- r2 * cos(cycle) y2 <- r2 * sin(cycle) ## まとめる d <- cbind(c(x1, x2), c(y1, y2)) d <- as.data.frame(d) names(d) <- c('x', 'y') ## 色付け及び分類ラベルを付与する d$label <- c(rep(0, 800), rep(1, 800)) ## ガウシアンカーネルでz軸の値を作る z <- rep(0, 1600) for (i in 1:1600){ tmp <- 0 for (j in 1:1600){ tmp <- tmp + exp(-((d$x[j] - d$x[i])^2 + (d$y[j] - d$y[i])^2)) } z[i] <- tmp } ## プロットする par(mfrow = c(1, 2)) plot(d[, -3], col = d$label + 1, xlab = '', ylab = '') scatterplot3d(d$x, d$y, z, color = d$label + 1, xlab = '', ylab = '', zlab = '') # ガウシアンカーネルSVMでクラス境界を引いてみる ## モデル推定する fit <- svm(as.factor(label) ~., d) ## クラス境界を引くためのグリッドを作る px <- seq(-12, 12, 0.02) py <- seq(-12, 12, 0.02) pgrid <- expand.grid(px, py) names(pgrid) <- names(d)[1:2] ## クラス境界をSVMモデルから計算する out <- predict(fit, newdata = pgrid) ## プロットする par(mfrow = c(1, 1)) plot(d[, -3], col = d$label + 1, xlab = '', ylab = '', xlim = c(-14, 14), ylim = c(-14, 14)) par(new = T) contour(px, py, array(out, c(length(px), length(py))), levels = 0.5, drawlabels = F, lwd = 5, col = 'purple', xlim = c(-14, 14), ylim = c(-14, 14))
他にも、例えば決定木をアンサンブルさせた結果としてのランダムフォレストの出力や、K-meansのアルゴリズムの動き方なども何がしかの可視化された図などがあったらもうちょっと分かりやすかったかもしれない、と思いました。少なくとも機械学習の知識がある僕にとっては難なく理解できる記述でも、その知識がない人たちがそれらの話題をいきなり地の文で読んだらちょっと戸惑うかもしれませんので。
