
今回のテーマは以前からずっと言われ続けている話題なので特に目新しくも何ともないのですが、たまたま近い時期に2本の似通った内容の論文がarXivに出たので、まとめてダイジェスト的に紹介しようと思います。以下がそれらの論文です。1本目はApple、2本目はGoogle DeepMindによる研究です。
どちらもSNSや技術メディアでは既報の内容であり、ご存知の方も多いのではないでしょうか。これらの論文は本質的には「『推論する生成AI』は実際には思考しているわけではなく、丸暗記した結果を返しているに過ぎない」と各種の実験結果から指摘するものであり、今後の推論生成AIの研究開発を行う上で新たに考慮されるべき指針を提案しています。
- そもそも「推論する生成AI」とは何なのか
- 「推論する生成AI」は既知の複雑な課題は解けるが、その難易度をどんどん上げていくと解けなくなる
- 逆に、「推論する生成AI」は既知の複雑な課題のルールを改変すると「どう見ても難易度が下がっている」のに解けなくなる
- 「複雑だが学習データに問いと答えが含まれる課題をそのまま出されれば解ける」即ち丸暗記したパターンのマッチングの可能性が高い
- コメントなど
そもそも「推論する生成AI」とは何なのか
最近の生成AIは多くが「推論」機能をアピールしていて、恥ずかしながらそれが正確には技術的に何を意味しているのか僕は長らく知らなかったのですが、どうやらChain-of-Thought (CoT) Promptingによる処理を強化学習によって重点的に実装した生成AIのことを指すようです。これは平たく言えば、「一つの大きな問題を小さな複数のプロセスに分解した上で段階的に処理していくことで最終的に問題そのものを解決する」ように学習させるということだそうです。
これがヒトの思考過程とどれくらい類似しているかには議論があるようですが、少なくともこのアプローチの導入によってより複雑な課題を解けるようになったことを示すベンチマークスコアの向上ぶりは数多く報告されており、実際に生成AI提供各社がそれらをもとに「推論する生成AI」をアピールしているということは皆さんも良くご存知の通りかと思います。最近では数学オリンピックや競技プログラミングなどのスコアで「ヒトのトップレベルに達した」という実績を各社ともアピールするケースが増えており、その性能競争は過熱の度が増すばかりのように見えます。
なお、基盤モデルである大規模言語モデル(Large Language Models: LLM)に対して、「推論する生成AI」は大規模推論モデル(Large Reasoning Models: LRM)と呼ばれるようで、今回紹介する論文中でもそれらの呼称が用いられています。
「推論する生成AI」は既知の複雑な課題は解けるが、その難易度をどんどん上げていくと解けなくなる
ここからが本題です。仮にLRMが実際に「思考」しているのであれば、性能競争において各社が喧伝しているような難しい課題を「解ける」以上、その課題のパラメータを多少変更した程度なら時間さえかければ解けて然るべきでしょう(解き方自体は合っているはずなので)。加えて、オリジナルより簡単で尚且つ自明な類似課題なら、尚更簡単に解けて当然だと期待されます。そこにメスを入れたのが今回紹介する2本の論文です。

まず1本目の論文ですが、代表的な論理パズルである「ハノイの塔」「チェッカージャンピング」「川渡り」「ブロックワールド」の4つの課題を用意して、それぞれの課題の複雑さに関わるパラメータ(ハノイの塔なら輪の数)を増やしていくことで、LRMの正答率がどのように変化していくかを実験しています。
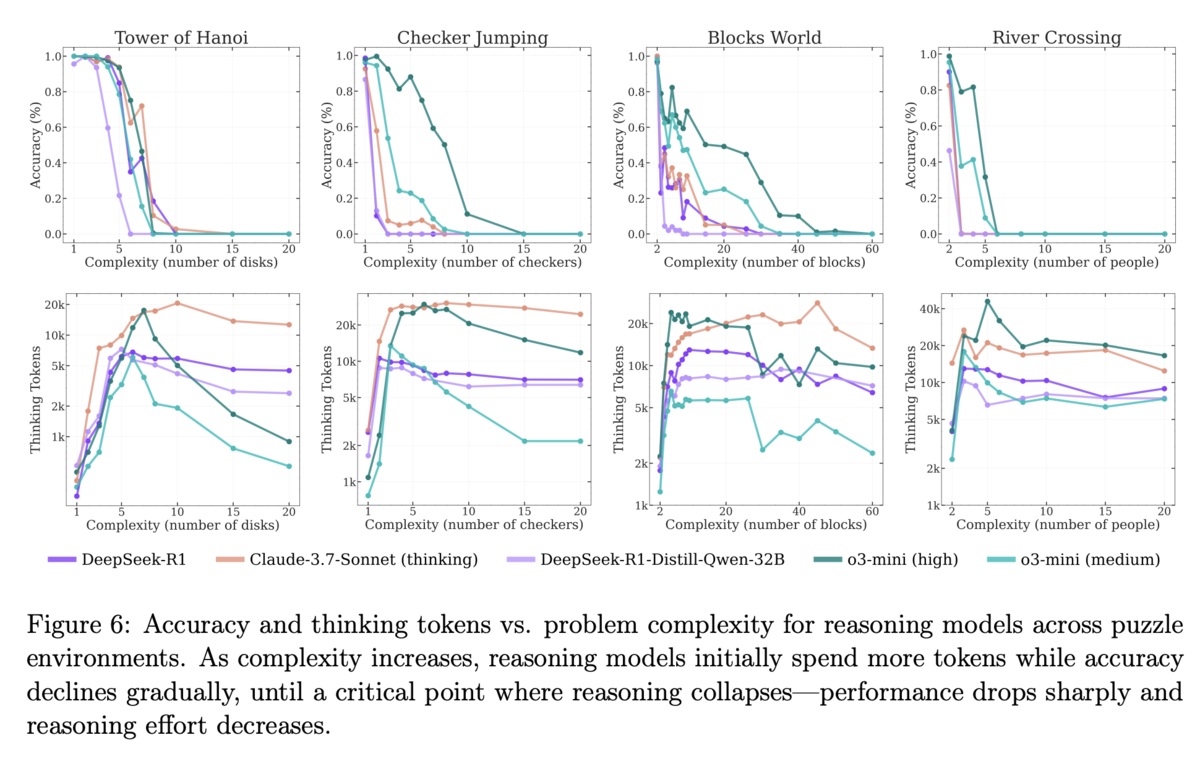
その結果、ある一定のラインを超えるとどのLRMも途端に正答できなくなったそうです。また、パラメータが増えて課題が複雑になればなるほど、「推論のための努力」(推論時トークン数から算出)が増えていくものの途中からは何故か減っていくという挙動を示したとのことです。これは、十分な推論リソース(予算)が確保されていたとしても、ある程度以上課題が複雑になってしまうとその推論のための豊富な計算量を上手く活用できなくなる、もしくは「推論しなくなる」ということを示していると見られます。
さらに興味深いことに、あるLRMはN = 5のハノイの塔(31手で解ける)は解けるにもかかわらず、N = 3の川渡り(11手で解ける)が解けなかったそうです。この点について、論文中では「ネット上にN > 2の川渡り課題のデータが少ないことから当該LRMの学習データに偏りが生じたためではないか」と推測しています。
逆に、「推論する生成AI」は既知の複雑な課題のルールを改変すると「どう見ても難易度が下がっている」のに解けなくなる

一方2本目の論文では、よりドラスティックな結果を得ることを目的としてなのか、一般的な高度推論課題(Puzzles)に加えてそれらを一部改変することで自明になるくらい極端に難易度を下げたUnpuzzles、そしてさらにそのコンテクストだけを変えたContext-shifted Unpuzzlesという課題を用いています。例えば上記のFigure 1の課題は「3色のカメレオン」課題*1を題材にしたもので、オリジナル(Puzzle)は割と煩雑な課題ですがUnpuzzleは自明で非常に単純です(パープルとイエローが同数なのでいきなり全部がマルーンになって終わる)。Context-shifted Unpuzzleはカメレオンをサッカークラブのファンに置き換え、数字もちょっと変えただけで基本的にはUnpuzzle同様に答えが自明な課題です。なお他にも鉄板の「天秤だけで1枚だけ紛れ込んだ偽コインを見破る」課題も紹介されていますが、これはもっとひどくて「最初から全て偽コインだけ」というUnpuzzleが用意されています(笑)。Web上で良く知られたものを中心に、全部で97個の課題を選んだそうです。
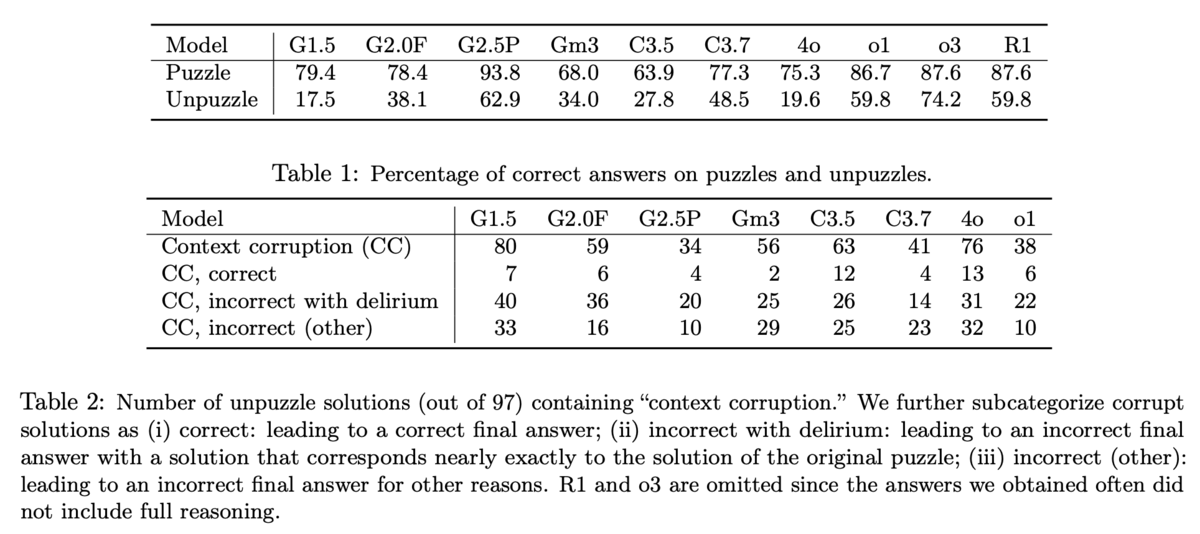
このような論理パズル群を用意して各種LRMに解かせるという実験を行ったわけですが、結果は惨憺たるもの。全てのLRMが「難しいPuzzlesよりも自明なUnpuzzlesの方が正答率が低い」という結果になったのでした。興味深いのが「Unpuzzleの答えは合っているものの思考プロセスが間違っている」ケースが見られたということ。前掲の「3色のカメレオン」課題では、Unpuzzleの答えは考えるまでもなく自明なはずなのですが、何故かPuzzleの方で用いる考え方を示して「これが回答だ」と言い張るLRMがあったそうです。
「複雑だが学習データに問いと答えが含まれる課題をそのまま出されれば解ける」即ち丸暗記したパターンのマッチングの可能性が高い
今回紹介した2本の論文は、それぞれ「LRMは考え続けて課題を解いているわけではない」「LRMは学習データにそのまま収録されている課題は解けるがそれを改変されるとどれほど自明でも解けなくなる」ということを報告しています。これは、素朴に考えれば「詰まるところLRMは複雑な課題を解いていても実際にやっていることは丸暗記したパターンのマッチング」だということなんですよね。
それは、NNそして機械学習の文脈でいえばれっきとした「過学習」そのものだと思われるのですが、LLM/LRMに付き物の「ハルシネーション」もその原因の一つに過学習が挙げられることを考えると、むしろ自然な結論であるように見えます。
2本目の論文では「真の推論能力を評価するための新たなベンチマークが必要だ」と指摘されていますが、非常に妥当な提案だと考えられます。現状では「いかに高度な課題に対する推論ができるか」ばかりがクローズアップされがちですが、それが単なる過学習で実現可能なのであれば、むしろ汎化性能をチェックするための異なるベンチマークもあって然るべきでしょう。
コメントなど
今更わざわざ強調するような話ではないとは思いますが、今回紹介した論文は「本質的には『ああ言えばこう言う』だけに過ぎない」という自己回帰型NNの限界を指摘している、と受け止めるのが妥当かと思われます。特に今回の実験のコンテクストに沿って言えば「難関大学の入試過去問を無限に丸暗記したbot」みたいなもので、過去出題された名だたる難問をいずれもスラスラと解いてみせるので一見凄いと思われがちだが、実際には過去に一度も出題されたことのないタイプの問題はどれほど易しくても解けない……的な話なのかなと。
恐らく今回の論文、特に2本目の論文については「たかがコーナーケースにおけるパフォーマンスぐらいであれこれ論うな」という反論もあり得るかとは思いますが、そもそもヒトなら難無くこなせるような課題を解けないということ自体が問題だと捉えられるべきではないかと、個人的には考える次第です。そしてそれが「推論する」という触れ込みとは異なるメカニズムによって引き起こされるのならば、尚更でしょう。
LRMは昨今すっかり世論を騒がせるテーマとなった「AGI(汎用人工知能)」の有力候補としてメディアの話題に上らない日はないという有様ですが、そんなAGI候補がただの「過去問丸暗記マン」と同レベルというのではあまりにもお粗末な話だと思います。新たなベンチマークの提案は論を俟たないとして、自己回帰型NNに依存しない新たなAGI向け機械学習アーキテクチャの提案が待たれるところです。期待を込めて。
ちなみに、「ヒトの知能」というのは大変に難しい研究テーマなのでこれは個人的な持論に過ぎませんが、ヒトの知性的な思考プロセスというのは「過去に学んだパターンの中から普遍性を(自分なりに)見出して一般化&体系化する」ことで得られるものだと考えています。なればこそ、「全てが偽コインだけで構成される『天秤とコインと偽コイン』課題」が自明だと感じられるようになるのかなと。これを実現させるアーキテクチャがどんなものになるのか僕には全く想像すら出来ませんが、願わくばそういうものがAGI研究の未来にあって欲しいものです。
最後に。……実は、「生成AIのハルシネーションの現状」と「プロンプトインジェクションの現状」というネタでそれぞれ記事を書こうと思っていたのですが、Gemini 2.5 Pro Deep Researchに資料をまとめさせたのを読んだだけでお腹いっぱいになってしまって、それきり放置したままになっていたのでした(汗)。これらについてもいずれダイジェスト的な記事を書こうかと思いますので、気長にお待ちいただきたく。