クラスタリングに用いられるK-meansのクラスタ数決定方法については長く議論されてきた歴史があり、このブログでも以前ちょろっと取り上げたことがあります。
で、Twitterを眺めていたらタイムラインに面白い論文が流れてきました。それがこちらです。
タイトルを読んで字の如く「K-meansのクラスタ数を決めるのにエルボー法を使うのはやめろ」という論文なんですね。全体で7ページと非常にコンパクトで読みやすい内容なので、簡単にまとめて紹介してみようと思います。なおいつもながらですが、僕の技術的理解が不足しているが故の誤りなどが混じる可能性がありますので、その際はコメント欄などでご指摘くださると幸いです。
- あるtoy dataに対するK-meansの結果
- 目検に頼らないエルボー法について考える
- ならば、既存のクラスタ数決定法の中では何を選ぶべきか
- そもそもK-meansが有効でないケースもあることを留意すべき
- 感想など
あるtoy dataに対するK-meansの結果
この論文の言いたいことのほぼ全てがFigure 1に込められています。要は「どう見ても真のクラスタ数が見た目にすぐ分かる」toy dataを幾つか用意して、それに対するクラスタ数をエルボー法で決めようとしたらどうなるかという様子を可視化したものです。
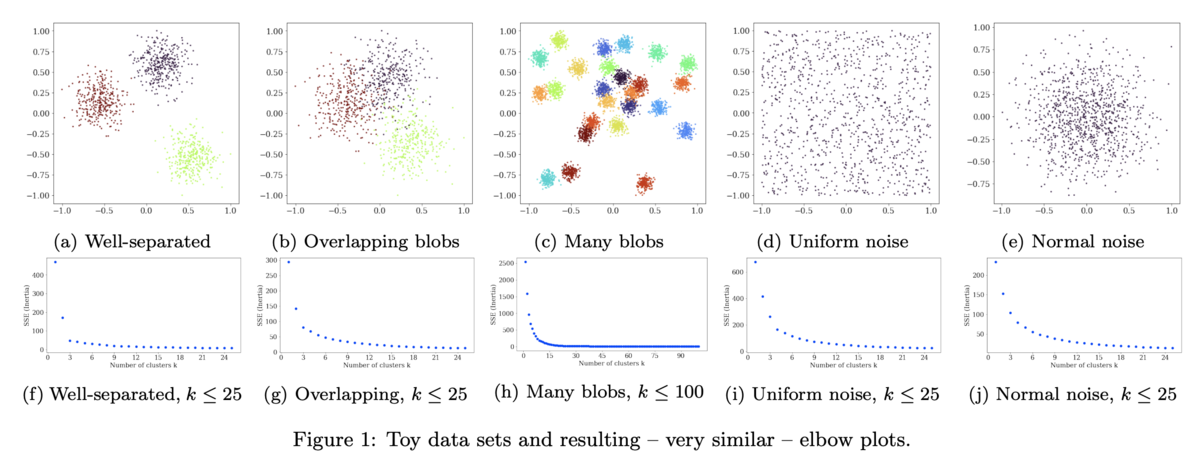
もう見たまんまですね(笑)。明確にクラスタの分離が可能な(a: k = 3)ではエルボー法でもk = 3と妥当な結果になっていますが、クラスタ間で重なりのある(b: k = 3)になると既に怪しくなってきて、クラスタが多数ある(c: k = 25)ではもうダメな感じがあり、単なるノイズの(d, e: k = 1)ではもはや意味をなしません。

この5つのtoy datasetsに対してエルボー法含む様々なクラスタ数決定法を当てはめた際に得られるクラスタ数を一覧にしたのがTable 1です。色々並んでいますが、以前ブログ記事でも紹介したBIC (fixed)が最も正解に近いパフォーマンスを示していることが分かります。いずれにせよ、「『肘』の位置を目検で見出す」エルボー法にはあまり信頼性がないようだ、ということをこの論文は主張しているというわけです。
目検に頼らないエルボー法について考える
では、エルボー法はそれほどまでにもダメなのか?という点について、3.3節では「目検はやめてきちんとクラスタ内分散を適切に扱うべきだ」という話をしていて、その中で
を使うというアイデアが出てきます。これは「直感的には最近傍クラスタ中心からの標準偏差として捉えられるはず」ということで、そのクラスタ数kの時の推定値
を算出して、上記のクラスタ内分散の補正値との比を取ります。即ち
として、これが1(等しい)の前後でどう振る舞うかを見れば良いと指摘しています。この値は必ず最後は1より大きくなる方向に発散していく(性質を考えれば明らか)ので、1のラインを最後に横切る直前のkの値が「ベストのk」になる、という理屈です。
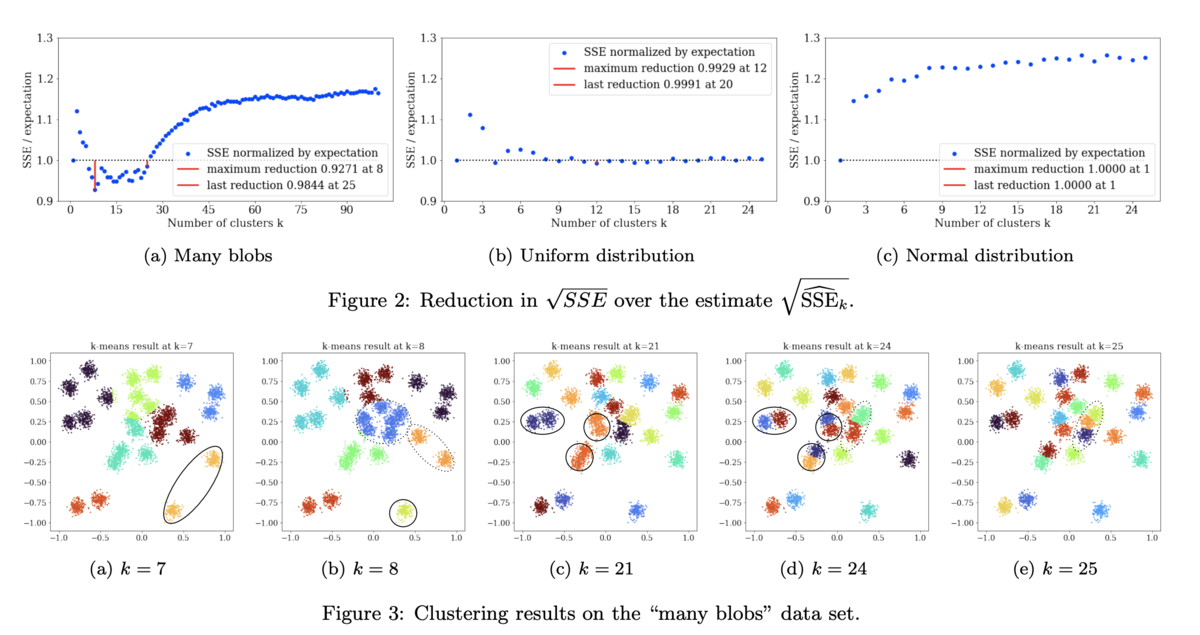
Figure 2はその様子を(a: k = 25, b, c: k = 1)の3つのtoy datasetsに対して示したもので、(a)に対しては確かにk = 25という真値と同じ値を返していますし、一様乱数である(b)に対してはちょっと挙動が怪しいものの、正規乱数である(c)に対しては悪くない感じの挙動になっています。
で、Figure 2の(a)を見るとk = 8のところで上記の指標が最小値を取るということで、その詳細を見たのがFigure 3です。これはおまけみたいなものですが、K-meansという手法が多クラスタデータに対してどう振る舞うかが良く分かる実験結果となっています。
ならば、既存のクラスタ数決定法の中では何を選ぶべきか
本文中ではクラスタ内分散に注目した手法、クラスタ間距離に注目した手法、情報理論即ち情報量規準に即した手法(BICなど)、乱数シミュレーションを活用した手法などについての言及がされていますが、Table 1を見る限りではどれも一長一短あるように見えます。
あえて言えばBIC (fixed)が全てのtoy datasetsに対して真値を返しているので有望だと言えそうな気もしますが、冒頭にリンクした過去記事での検証結果だと常に真値を返すというわけでもないので、ここは多面的かつ総合的に検討してどれを使うか決めるべきという話なのでしょう(玉虫色の結論)。
そもそもK-meansが有効でないケースもあることを留意すべき
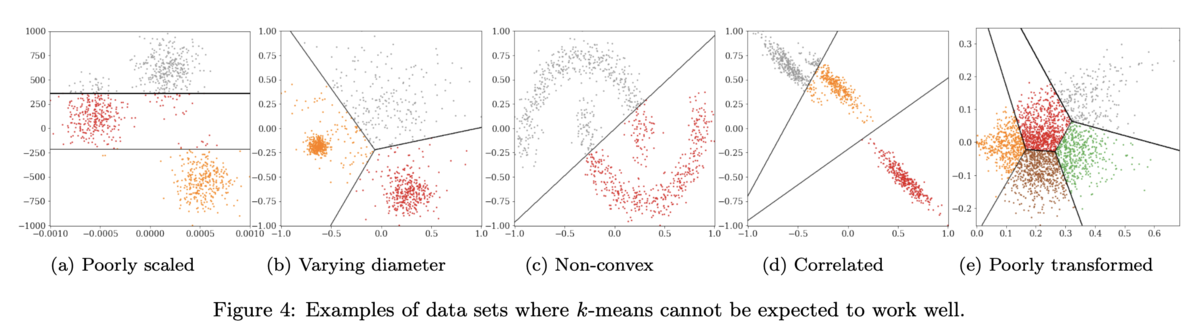
最後に、Figure 4ではそもそもK-meansが有効でないデータセットの例が紹介されています。これはもう見たまんまですが、言い方を変えると「K-meansでこれこれの結果になったのでこれを前提として〜」というような議論を進めようとするのは結構危ういということなのでしょう。本文中ではK-meansの結果に信頼性がないケースについてFigure 4の例に限らず言及されているので、引用先の文献も含めて精読されることをお薦めします。
感想など
これは完全にPRMLの受け売りですが、「2次元サンプルで成り立つことが高次元空間でも成り立つとは限らない」ということは良く言われるので、この論文の実験結果が(より一般的な)高次元空間でも成り立つかどうかについてはもう少し議論が必要なのかなと思いました。
また今回の論文中では言及がなかったんですが、例えばカーネル法と組み合わせるとか、t-SNEで前処理するみたいなのもあり得るのかなと思いました。特にカーネル法を使えばFigure 4 (c)のnon-convex samplesに対しては効果的な気がします。が、いずれも「その前処理自体に恣意性があるのでは」と言われたらそこまでなので、結局データを丁寧に見ながらやるしかないってことですかね……。