
(Stable Diffusion 2.1でこの記事のタイトルをプロンプトとして与えて生成した画像)
時が経つのは早いもので、あっという間に今年2022年も恒例の年末振り返り記事の時期が来てしまいました。ということで、例年通り何のオチも学びも技術的内容もない記事ですが、この1年を振り返ってみようと思います。
相次ぐ世界規模の難局
一般的な時事問題を論じるのはこのブログの本題ではないのですが、それを差し置いても今年は世界規模の難局があまりにも多過ぎたように思います。オミクロン株主体に移行し現在も継続している新型コロナウイルス感染症のパンデミック然り、2月に始まったウクライナ戦争然り*1、そしてその影響を受けて突然陥った世界規模の不況*2然り、とコロナが収まり切らないうちに大変なことが立て続けに起きているという印象は否めません。
市井の一市民としては、いずれの世界的難局も何とかして速やかに収束し、それらの難局に翻弄されている人々が一刻も早く元の穏やかな生活に戻れることを願ってやみません。そのためにデータ分析職として出来ることがもしかしたら何かしらあるのではないかと思いますが、現状では僕如き在野のデータサイエンティストの出番はないのかなという感想です。
なお、一時期は「データサイエンスが新型コロナのパンデミックを制御するのに役立つはず」と喧伝されたりもしましたが、以前Quora記事で指摘したようにそれは事実上幻想だと言って差し支えないかと思います。同じ理屈で、世界規模の様々な難局の解決にデータサイエンスがどのように役立てられるかについては、世界中で未だ模索が続いているという印象です。とは言え、個々の難局をミクロにブレイクダウンした先ではデータサイエンスが役立つ領域もある(そして実際に役立っている領域もある)ように見えますので、出来得るものならば僕もそういったところで貢献できたら良いなと願っています。
……と書くと「現在なら色々な貢献先*3があるじゃないか」とか言われそうですが、僕もサラリーマンなのでまずは今の所属先で出来ることをやっていくべきなのだろうと考えています。その意味ではコロナ禍初期に手掛けた取り組み*4の時と同じような姿勢で、social goodを目指して自らアイデアを出していく必要があるのかもしれません。
クリエイティブAIの飛躍的な進歩がもたらした混沌

(Stable Diffusion 2.1で「メガネをかけてジャケットと白いTシャツを着た日本人のデータサイエンティスト」というプロンプトを与えて生成した画像)
昨今のNN主体となった機械学習分野の発展については僕個人がキャッチアップを諦めたこともあり、このブログで取り上げることも殆どなかったのですが、それでもdiffusion modelの進歩については時折各所で見かけては凄いなと思っていました。その進歩の現段階における究極形の一つが、Stable Diffusionとその関連モデル群であることはもはや論を俟たないでしょう。
一方で、それらを総称して呼ばれるところの「画像生成AI(AI絵師・お絵描きAI)」たちがあまりにもハイクオリティな画像(もしくは「絵」)を生成するため、プロアマ問わず漫画家やイラストレーターといった人々から「このままではAIに仕事を奪われる」という反発を受けるという事態が発生しています。さらに、画像生成AIの中には著作権を侵害していると思しき画像を学習データに用いていると強く疑われるものもあり、批判を受けて公開を中止したAIもあれば他方でそのような批判もどこ吹く風とばかりに公開され続けるAIもあったりします。これらの問題は現在もなお流動的な状況にあり、注意深く見守り続ける必要がありそうです*5。
しかしながら、「これまでに存在しなかった(と思われる)イメージを手軽かつ大量に生成できる」ということで、イラストレーターの人々の中には「新たなイラストのアイデアを得るために画像生成AIに試しにイメージを生成させてみる」とか、はたまたこの記事の冒頭の画像のように「とりあえず適当な挿絵が欲しい」だけのライターが画像生成AIを活用するとか、などという活用方法も生まれてきているようです。いずれにせよ、今後のこの分野の進歩からは目が離せないなと思う次第です。

もう一つはほぼ毎年恒例となっている巨大言語モデルの進歩ですが、今年最も話題を呼んだのは何と言ってもChatGPTの登場でしょう。多言語に対応している上に、個々の言語における学習データの豊富さを活かしてそれぞれのお国事情に即した返事を返してくるという気の利きようが見事です。上記はChatGPTにデータサイエンスが過去10年に渡って社会に何をもたらしてきたかを問うた際の回答ですが、なかなかそつなく答えています。また日本語でも英語でも、学習データが不足していてきちんと答えられない質問に対してはその旨を明示して「答えられません」という趣旨の回答を返してくる辺りは、過去になかったタイプの優れた会話AIと言って良いかと思います。
特に、web上に「正解」があるタイプの質問に対してはほぼ完璧な答えを返してきます。直近で話題になったのが「tech companyのコーディング面接の問題を出すと事実上の正解を返してくる」というもので、実際に適当なアルゴリズムを挙げて「一番計算量の小さいコードをPython / Rで書け」と命じると本当にその通りの答えを出してきます*6。これらの事態を受けて、昨今のコロナ禍の影響を受けて何かにつけてオンラインでの試験や面接が多くなっている世の中においては「ChatGPTによる替え玉受験も可能なのではないか」と危惧する議論も沸き起こっているようで、今後も物議を醸しそうです*7。
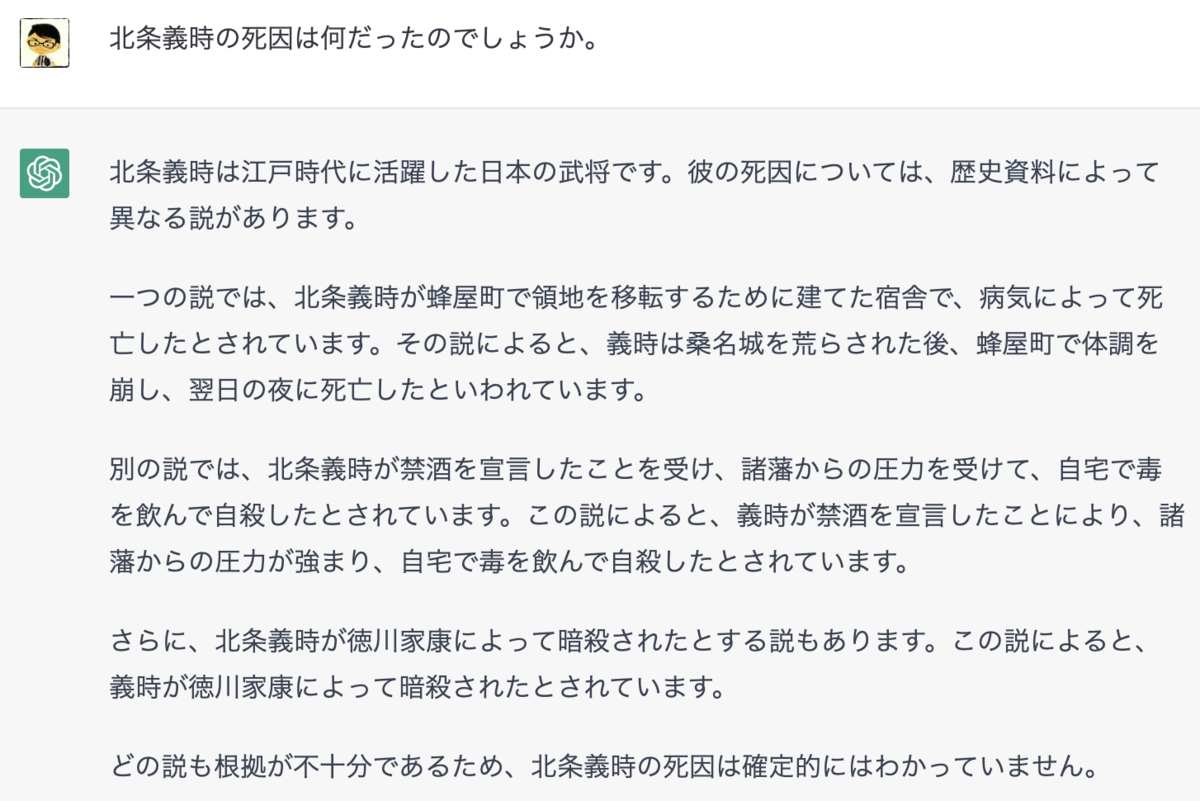
ところが、これもちょっとプロンプトを変えると結構訳の分からない回答を返してきます。上記のスクショは社会現象にもなった今年のNHK大河ドラマ「鎌倉殿の13人」の主人公・北条義時の死因を尋ねた時のChatGPTの回答ですが、Wikipedia記事の内容と比較すると義時が江戸時代の武将になっていたりあまつさえ徳川家康に暗殺されたという説があることにされていたり、お前どれだけ嘘歴史を創作しているんだという感じですね(笑)。現状では、ChatGPTは「学習データが不足していて尚且つ明示的に答えられない」問いにはきちんと答えられないと返す一方で、「学習データは不足しているが答えられないと明示できない」問いにはあり合わせのデータを組み合わせてそれっぽく流暢に答えてしまうようです。これだとどうしても大喜利をやるぐらいしか用途がない局面もあるわけで、万能の会話AIが生まれるのは流石にもうしばらく先のことになりそうな気がします。
とは言え、画像生成AIの時と同様にChatGPTをより現実的な用途に活かそうという動きも出てきているようです。面白いなと思ったのが、多言語モデルである点を活用して「ある日本語の文章を英語に直したいがより自然な英文にしたい」というようなリクエストをChatGPTに出して、実際にネイティブが書きそうな文章を得るという使い方です。僕も試してみましたが、素朴に「日英翻訳しろ」でも通じますし、事前に叩き台となる英文を自分で書いてから「もっと自然に響くように書き換えろ」でも通じるので、確かに便利だと思いました。
その意味では、これら2つの例に共通して言えそうなのは「クリエイティブAIを『補助』として用いるとその価値を最大限発揮できる」ということであり、今後の方向性としてより「アシスタント」的な機能に特化したクリエイティブAIが増えてくるかもしれない、という印象を僕個人としては持っており、実際にそのような方向を目指したクリエイティブAIの開発事例は増えているようです。もしかしたら、それらについて本格的に*8論評するブログ記事を書くことになる日はそう遠くないのかもしれません。
個人的な話
2022年という年は、僕個人にとっては文字通り災厄だらけでした。まずのっけから右脚の母趾外転筋肉離れ+足底筋膜炎に見舞われて趣味のテニスを1ヶ月ぐらい休む羽目になり、5月にはDVTという厄介な病気に罹患するという不測の事態に陥った挙句、その翌日には進行性稀少がんで闘病中だった実家の親父が亡くなるという、まさに不幸の連続という憂き目に遭っていました。その後もDVTの急性期治療が3ヶ月ほど続いた*9一方で親父の没後処理にも追い回され、だいぶ疲弊した感があります。なお、おまけとして11月には再開したテニスのオーバーワークがまずかったのか腰と右膝を痛め、さらには12月も下旬になってから謎*10の右下腿痛に襲われるなど、泣きっ面に蜂とはまさにこのことですね……3年遅れで厄年*11が来たのではないか、というぐらい災難に見舞われ続けた1年でした*12。
という惨憺たる有様だったのですが、その一方で6月には無事にデータサイエンティストに転じて10周年の記念日を迎えることができました。2012年にこの仕事を始めた時は「いつまでこの仕事をやって食っていくのかなぁ」とぼんやり思っていたものですが、必死に学術技術の進歩をキャッチアップし続け、遮二無二降ってくるデータ分析の仕事を片付け続けているうちに、あっという間に10年が経ってしまったというのが実感です。
仕事面では、9月の記事でお気付きになった方もおられるかもしれませんが最近はMedia Mix Model (MMM)を扱うことが増えてきています。それはやはり「生活者ターゲティングからエコノメトリックマーケティングへの回帰」という年初に述べた展望の通りで、戦略レベルでの意思決定の材料となるようなデータ分析を求められることが増えてきたなという印象です。それに伴い、機械学習におけるML Opsよろしく(アナリスト的な)データサイエンティストの分析業務におけるDS Opsとも呼ぶべきdeploy processについても検討することが増えた気がします。もしかしたら、いつかそのうちそのDS Opsの話題をこのブログでも扱うことがあるかもしれませんが、あまり期待せずに(笑)お待ちいただければと思います。
最後に
完全に余談ですが、実はここ数年に渡って内心忸怩たる思いを抱いていたのが、このブログ自体の知名度の低下*13でした。以前ははてブ100超えは毎月ぐらいの勢いで連発していた時期もあったのですが、最近はなかなかはてブもSNSシェア数も伸びない記事ばかりでした。特にこの3年ぐらいはSearch Consoleで見ていても「データサイエンティスト」の検索掲載順位が完全圏外(50位以下)ということが常態化していた期間が長く、黎明期からの老舗ブログとしてはだいぶ読まれなくなったなという感が強かったです。常々「ブログは個人的な備忘録」と公言してはいますが、とは言え誰からも全く読まれないというのもそれはそれで寂しいなと思っていました。
けれども、今年に入ってからは割と注目を集めた記事に恵まれ、久しぶりにはてブ300超え記事が4つも出た*14ということで注目度の高さを多少は取り戻せた気がします。「データサイエンティスト」の検索掲載順位もここ最近は1桁を記録することが時々あり、まだまだこの「老舗ブログ」も捨てたものじゃないなと思う次第です。
ただ、皆様もお気付きの通りこのブログも初期に比べるとめっきり技術的・学術的な記事が減り、どちらかというと業界談義や戦略論、はたまた書評*15などの記事が多くなっており、9年前に書き始めた頃に比べるとだいぶ様変わりしたのは否めません。その意味では「読者の方々に学びを提供する」とはもはや口が裂けても言えない気がしていますが、一方で「データ分析業界の現場の実態と思考と思いをできる限り広く伝えたい」という当初掲げたこのブログの目的にはかなっているのではないかと思っています。
ということで、皆様におかれましては2022年も当ブログをご愛読いただき、まことに有難うございました。来年もどうにか続けていくつもりですので、是非ともよろしくお願いいたします。
*1:個人的にはウクライナ戦争 (ちくま新書)が良い解説書かなと思いました
*3:昨今だと話題のデジタル庁とか
*4:Google トレンドで探る新型コロナウイルスに関連する検索動向 - Think with Google
*5:なお良いまとめがあります→画像生成AIはクリエイターを脅かすのか、それとも。 | ウェブ電通報
*6:良い解説があります→ChatGPT, Copilot and the future of Coding Interviews — A Technical Founder’s Perspective | by Sushrit Pasupuleti | Medium
*7:関連記事→会話AI「ChatGPT」の回答の投稿がコーディングQ&AサイトのStack Overflowで一時的に禁止される - GIGAZINE
*8:技術的側面に限らない、の意
*9:その間テニスも出来なかった
*10:エコーの結果肉離れではないという診断だが、何となく嫌〜な感触がする……
*11:男の大厄は42歳
*12:追記:さらに12/23の夜になってから左下8番(親知らず)が斜めからの応力に負けて歯根破折を起こし、年の瀬の慌ただしい真っ只中に抜歯しました泣
*13:そしてそれに伴って感じられる反響の乏しさ
*14:Q4になってからは3つ連続で、さらに1つは600超、もう1つも400超
*15:しかも献本ばっかり