先日こんな記事を書いたのでした。はてブも400近くに達しており、良くも悪くもバズったようです。
で、この記事の中で言いたかったことは幾つかあるのですが、その一つに「文書・テキスト要約など『そもそもLLMというかLM自体が得意な仕事』をさせると便利なはず」というのがありました。そして実際に現職の日常業務の中でも時々使っているのですが、確かに便利だなぁと思うことが多いです(もっとも時々凄まじいhallucinationを炸裂させてくることもありますが)。
そこでちょっと考えたのが「データ分析の諸作業のうち何をLLMにやらせると効率的か」というお題です。これはちょっと調べれば既に試している人が結構いて、例えば以下のような事例があったりします。
ただ、例えば "Titanic" のような有名過ぎるデータセットだとそこらじゅうにこれを対象として分析してみましたという記事やドキュメントが沢山転がっており、それらのテキストから間接的に内容を推定するということをLLMならやってしまいそうです。そこで、もう少しだけ知名度の低いデータセットを色々LLMに読み込ませてみて、まずは「このデータの概要を教えろ」とリクエストしてみた結果を見比べてみようと思います。なお、使用するLLMは「自分の勤務先が提供しているから」という理由でBardとさせていただきました*1、悪しからずご了承ください。
- Wine Quality (UCI ML Repository)
- Seeds (UCI ML Repository)
- Online News Popularity (UCI ML Repository -> personal GitHub)
- 国交省車両故障データセット
- とある自作データセット
- 最後に
Wine Quality (UCI ML Repository)
まずはこちらのデータでやってみます。
このブログでも何度か利用している "Wine Quality" データセットです。Bardに概要を説明させてみたところ、このような回答が返ってきました。
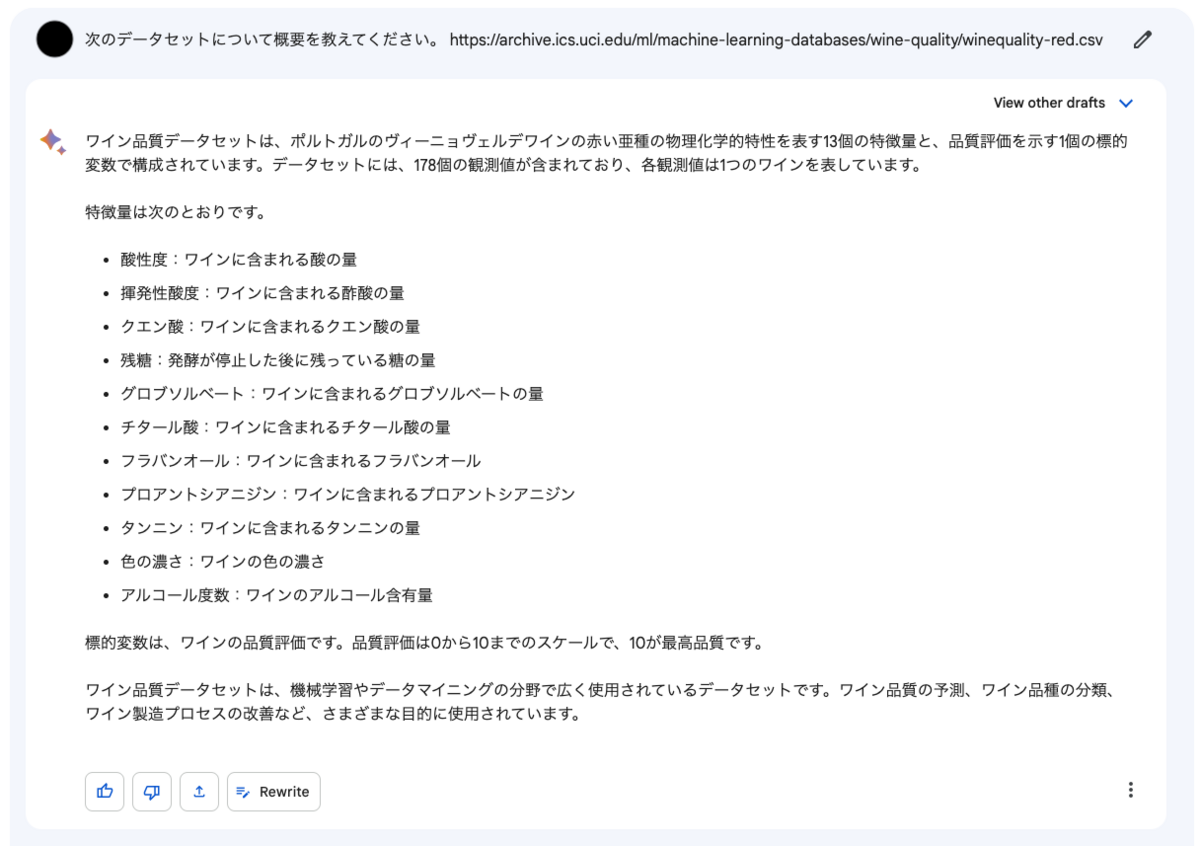
完璧な解説です。勿論このデータセットはポータル側のページにも事細かに説明が書かれており、単にBardはそのテキストの内容を学習データとして得ているだけであるようにも思われます。
Seeds (UCI ML Repository)
では、こちらのデータではどうでしょうか?
"Seeds" データセットは僕が毎年開講している初級者向けデータサイエンスコースでクラスタリングの演習に使っているものです。Bardの説明はこんな感じでした。
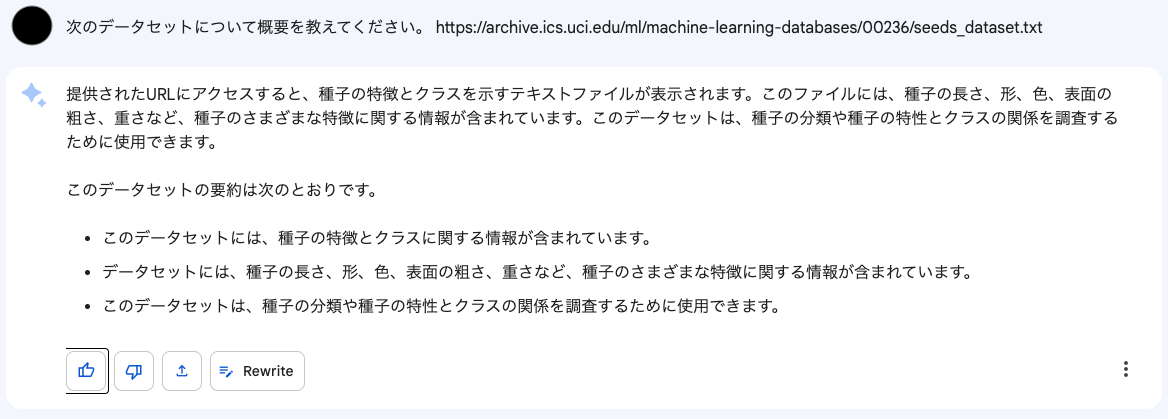
確か種子の「クラス」に関する情報は含まれていなかった気がしますが*2、それほど変な説明ではないと思われます。
Online News Popularity (UCI ML Repository -> personal GitHub)
どんどん行ってみましょう。こちらのデータで試してみます。
以前AutoML Tablesの性能検証で用いた "Online News Popularity" データセットです。ただし、僕のGitHubリポジトリに適当にsplitしてCSVにして置いておいたものを読ませています。Bardの説明は以下の通りでした。
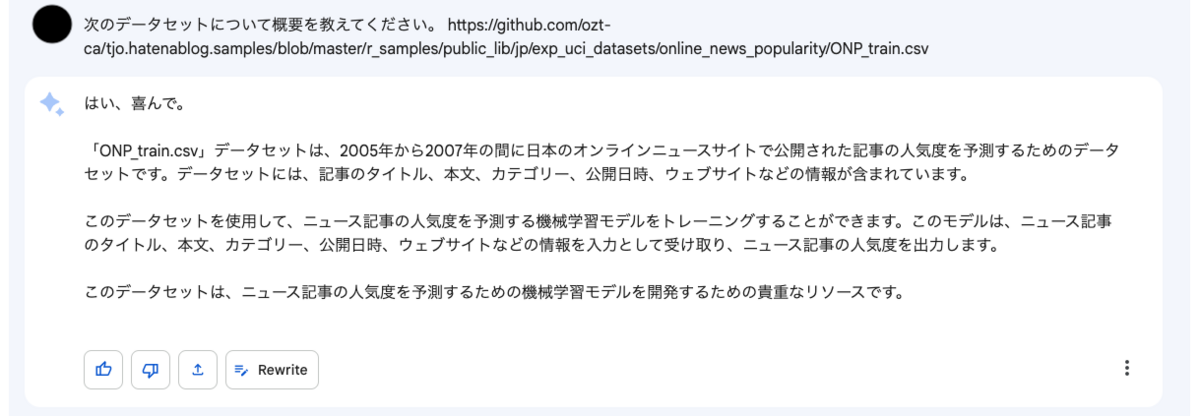
元のUCI ML repositoryの説明を見れば分かるように、これは日本ではなく(おそらく)ポルトガルのデータセットで、確か記録された時期も2005-7年ではなかったと思いますが、それ以外は概ね合っています。
国交省車両故障データセット
調子に乗ってもっと試してみます。次のデータはこちらです。
TF-Hubで遊んでみたり、また4年前の登壇時にもAutoMLに扱わせたりした、国交省車両故障データセットです。Bardに説明させると、以下のような回答が返ってきました。
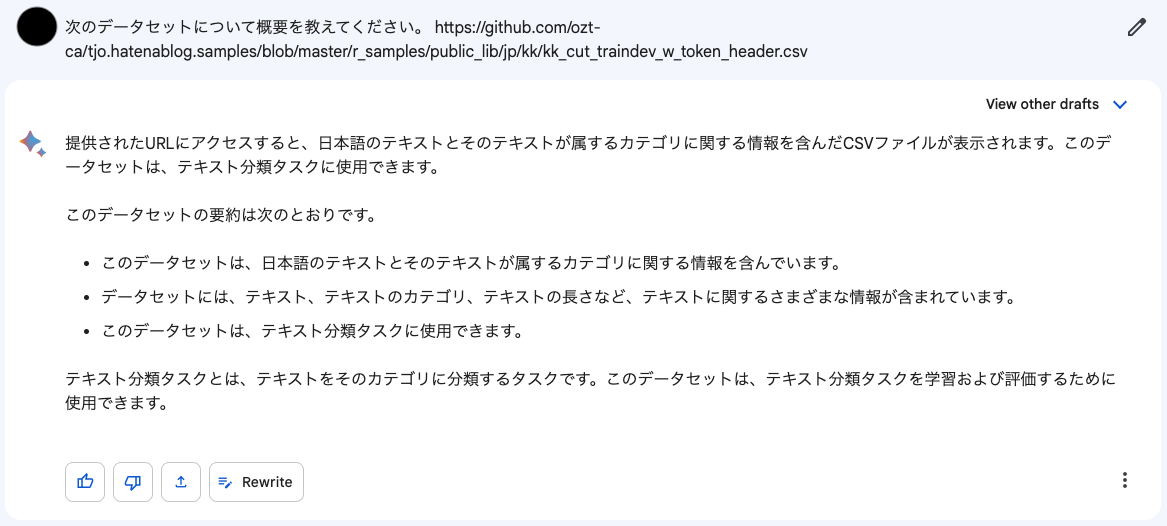
流石に細かい説明ではありませんが、それでもこれが「日本語の」「テキスト分類タスクのための」データセットであるということを認識しているようです。例えばここから「そのテキスト分類タスクのためのPythonコードを書け」とリクエストすることも可能でしょう。ちなみにリクエストしてきたらこんなコードが返ってきました。
import pandas as pd import numpy as np # データセットを読み込む df = pd.read_csv('kk_cut_traindev_w_token_header.csv') # テキストとカテゴリを分離する X = df['text'] y = df['category'] # テキストをベクトルに変換する vect = TfidfVectorizer() X_vect = vect.fit_transform(X) # 分類器を学習する clf = LogisticRegression() clf.fit(X_vect, y) # 分類器を評価する y_pred = clf.predict(X_vect) print(f'Accuracy: {clf.score(X_vect, y):.2f}')
sklearnとかmecabとか入ってないのでこれではダメなんですが(苦笑)、お作法という意味ではガワぐらいは書けているという感がありますね。
とある自作データセット
では最後に、こちらのデータではどうでしょうか?
実は、このデータセットはまだどこにもその使い方や解釈、及びこれを利用したデータ分析例を書いたりしたことはありません。しかしBardは以下のような説明を返してきました。
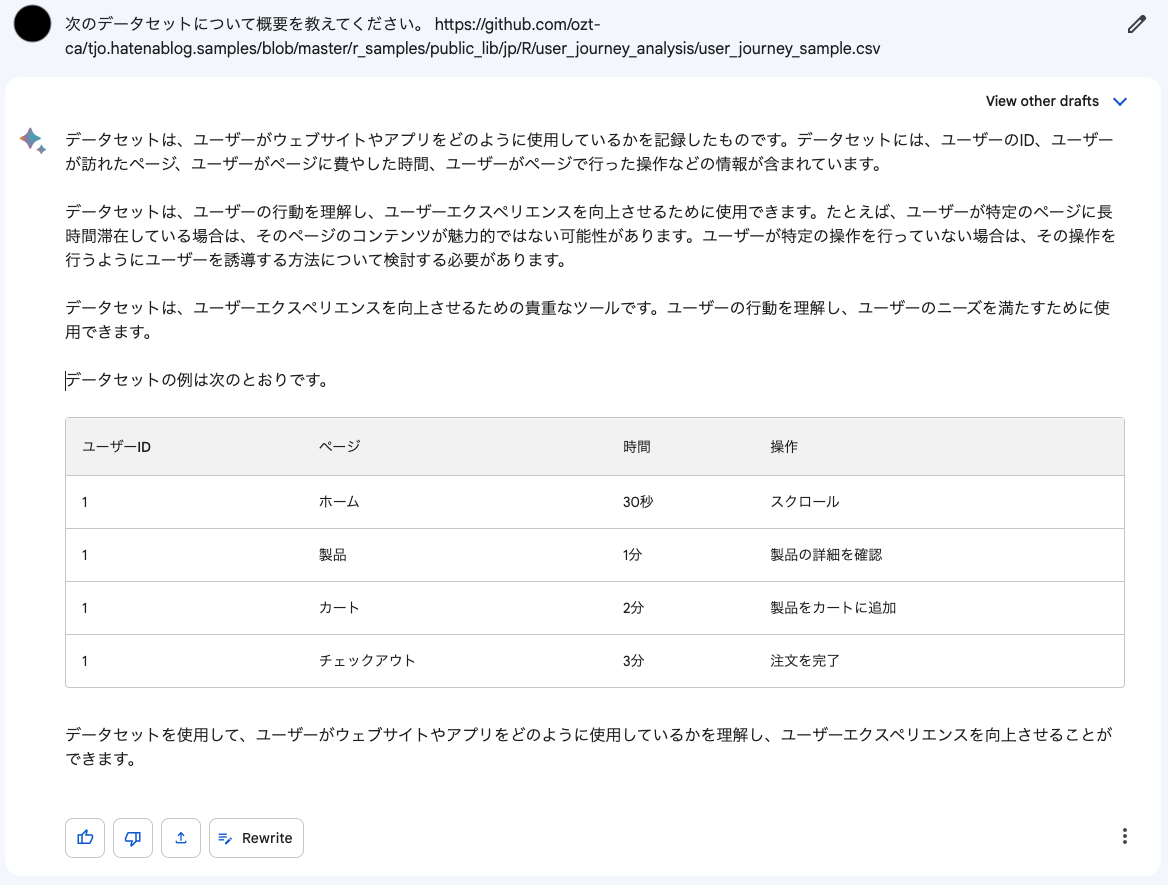
何とこれは正解なのです。というのも、これは僕が個人的に訳あってユーザージャーニー*3分析を再びやってみようと思ってRコードを書いたのですが、その検証データとして手入力で適当に作った代物なんですね。確かにファイル名がuser_journey_sampleなのでそれを見れば一目瞭然だろと言われればそこまでですが*4、特に説明を付したことのないデータセットでも的確にその特徴を捉えられるようです。
……ともあれ、グラフデータセットも読み解くことが出来ると分かったので、最後の最後にこちらのデータでやってみます。
ご存知『レ・ミゼラブル』の共起関係データセットです。スピングラス法のコミュニティクラスタリングをかけると、物の見事に劇中での人間関係のグルーピングが全部検出されるというので名高い代物ですね。で、Bardに説明させたらこうなりました。
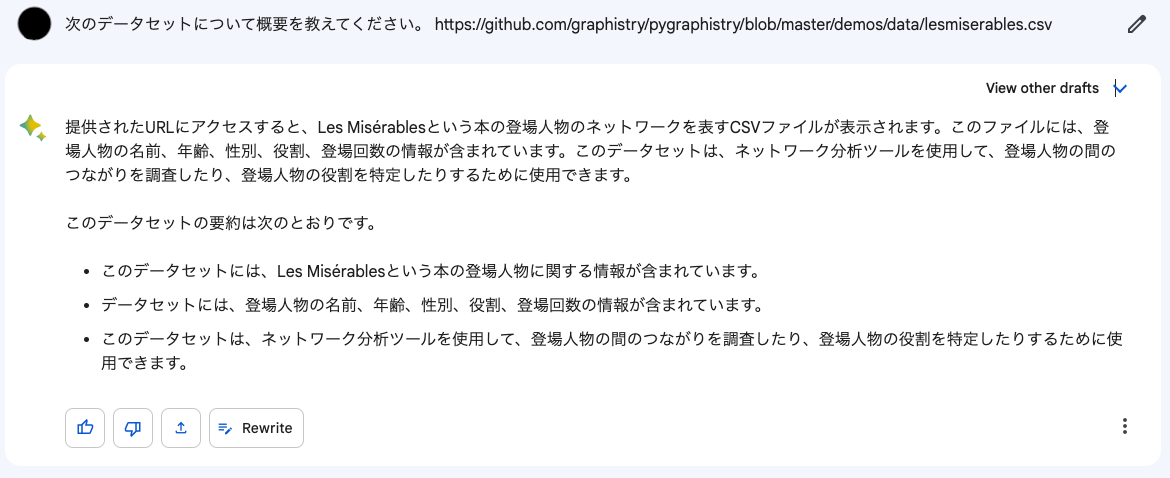
いやー……登場人物の名前と(同時)出現回数は記録されているんですが、年齢・性別・役割については何一つ書かれていないんですよね。これは他のデータセットとの類似性から勝手に付け足されてしまったhallucinationと思われます。やはりLLMは一筋縄ではいかないようです。
最後に
色々試してみましたが、最初の憶測通り「ある程度はデータセットそのものを解釈するというよりもそのデータセット(のURL)が引用されて行われているデータ分析の記述を踏襲している」感が結構あるなと思ったのも事実です。
しかしながら、ユーザージャーニーデータセットでも見たように「他のデータセットの類似度からある程度類推する」ことも出来るようで、この辺にLLMならではの利用価値があるのかもしれません。
ということで、次回は*5データセットをLLMに提示した上で、その分析を行うコードをどれだけ正確に出せるかを検証してみようかと思いました。これまた既に結構な数の検証結果が世に出回っているテーマですが、僕のようなマニアックな分析ばかりしている人間にとっても有用かどうかは気になるところなので、暇を見て試してみたいところです。