麗々しく自社プロダクトについてのまとめ記事を書くのは若干気が引けるのですが、先日Gemini 2.5 Proにvibe codingということでMMMのサンプルコードを書かせてみたら既にsunset済みのLigthweight MMMを使ったコードが返ってきた上に、よりにもよってこのブログのLMMM紹介記事を参照してくるということがありまして*1、これはいかんということでこのブログでもMeridianの紹介記事を書くこととしました。
Meridianそのものについては公式サイト・ドキュメントやGitHubリポジトリに既に公式のきちんとした説明が沢山ありますので、この記事ではMMMの実務家にとって重要そうなポイントに絞ってご紹介していこうと思います。
- Meridianの標準的な実行コード
- Meridianに固有の特徴
- Meridianを利用する上での注意点
- 最初はとりあえず全てデフォルトの設定で回してみる
- 「トレンド」は事実上推定されない
- 事前分布を導入するなら、根拠あるパラメータを用いるべき
- ベイズ信用区間の取り扱いは慎重に
- ハイパーパラメータknotsのチューニングは無理のない範囲で
- 地域レベルモデルは個々の地域間差異には関心がない
- 多重共線性には無理に事前分布の設定で乗り切ろうとせず、適切に対処すべき
- 系列相関や潜在的な内生性を伴うベイズ時系列回帰モデルなので、DAGにこだわるよりバイアスを軽減することを主眼に置くべき
- 合目的性のある交差検証を意識するべき
- Meridian単体で無理に完結させず、適切に事前・事後の検証実験を組み合わせるべき
- コメントなど
Meridianの標準的な実行コード
GitHubにdemo notebookが上がっているので基本的にはそれをなぞればおしまいですが、高レベルAPIだけでサラッと流してしまっている箇所がチラホラあって不親切な点もありますので、それらの点を補足したコードを以下に載せておきます。一部Geminiに直させていて構成が乱れている箇所*2については平にご容赦ください。
なお、実行環境はGoogle Colaboratory (Colab)を想定しています。よほど重たいデータセット&パラメータ設定にしない限りは、無料のT4 GPUランタイムで回せるはずです。
インストールとインポート
# Install meridian: from PyPI @ latest release # !pip install --upgrade google-meridian[colab,and-cuda] # Install meridian: from PyPI @ specific version # !pip install google-meridian[colab,and-cuda]==1.1.1 # Install meridian: from GitHub @HEAD !pip install --upgrade "google-meridian[colab,and-cuda] @ git+https://github.com/google/meridian.git@main"
Demoでは3通りのインストール方法が挙げられていますが、個人的にはprivate repository時代からずっとGitHubからインストールしているので、この記事でもそちらを採っています。
import arviz as az import IPython from meridian import constants from meridian.analysis import analyzer from meridian.analysis import formatter from meridian.analysis import optimizer from meridian.analysis import summarizer from meridian.analysis import visualizer from meridian.data import data_frame_input_data_builder from meridian.data import test_utils from meridian.model import model from meridian.model import prior_distribution from meridian.model import spec import numpy as np import pandas as pd # check if GPU is available from psutil import virtual_memory import tensorflow as tf import tensorflow_probability as tfp ram_gb = virtual_memory().total / 1e9 print('Your runtime has {:.1f} gigabytes of available RAM\n'.format(ram_gb)) print( 'Num GPUs Available: ', len(tf.config.experimental.list_physical_devices('GPU')), ) print( 'Num CPUs Available: ', len(tf.config.experimental.list_physical_devices('CPU')), )
JAX + NumPyroではなくTensorFlow Probabilityなのが気に入りませんがモジュールのインポートはdemoの通りにやれば大丈夫です。利用可能なGPU/CPU数のチェックも入れておくと良いでしょう。
データ周りのセットアップ
df = pd.read_csv(
"https://raw.githubusercontent.com/google/meridian/refs/heads/main/meridian/data/simulated_data/csv/national_all_channels.csv"
)
今回使用するのは、MeridianのGitHubリポジトリで提供されているnational level(単一地域)のデモデータセットです。よって、以下のデータ周りの設定もnational levelが対象のものになっています。Geo level(複数地域)を選んだ場合は多少異なってくるのでご注意ください。
当該のCSVファイルのカラム名を見ればお分かりかと思いますが、個々のメディア変数には必ずimpressionとspendの2列が入っていなければなりません。一般的なMMMだとspend (cost)のみをメディア変数に充てるケースが多いですが、その場合は元のデータセット側でカラムを複製して2列にするか、コードを書く際にDataFrameをいじるかするなどして対応してください。
builder = data_frame_input_data_builder.DataFrameInputDataBuilder(
kpi_type='non_revenue',
default_kpi_column='conversions',
default_revenue_per_kpi_column='revenue_per_conversion',
)
builder = (
builder.with_controls(
df, control_cols=["sentiment_score_control", "competitor_sales_control"]
)
)
channels = ["Channel0", "Channel1", "Channel2", "Channel3", "Channel4"]
builder = builder.with_media(
df,
media_cols=[f"{channel}_impression" for channel in channels],
media_spend_cols=[f"{channel}_spend" for channel in channels],
media_channels=channels,
)
builder = builder.with_non_media_treatments(
df, non_media_treatment_cols=['Promo']
).with_organic_media(
df,
organic_media_cols=['Organic_channel0_impression'],
organic_media_channels=['Organic_channel0'],
)
builder = builder.with_kpi(df) # Add the KPI data here
data = builder.build()
データ入力形式はDataBuilderのメソッドでセットアップします。コントロール変数、メディア変数、非メディア施策変数、KPI(目的変数)のそれぞれに対してオブジェクトをセットし、最後にビルドしてMeridian形式のデータセットオブジェクトを作ります。
注意点として、Meridianは原則として個々のメディアのROI (ROAS)を推定することを主目的としており、そのため目的変数もrevenue即ち「売り上げ金額」もしくは「1単位当たりの売り上げ金額が定義可能な指標」であることが求められ、デフォルトではそこを意識した事前分布の設定がなされています。それ以外の指標*3を目的変数とする場合は、事前分布の変更が必要です。
モデル設定
cv_knots = 1 #knotsはCVで決める n_times = len(data.time) holdout_id = np.full(n_times, False) holdout_id[n_times-8:n_times] = True # 8点(2ヶ月)のholdout期間をpast-and-future splitでとる roi_mu = 0.2 # Mu for ROI prior for each media channel. roi_sigma = 0.9 # Sigma for ROI prior for each media channel. prior = prior_distribution.PriorDistribution( roi_m=tfp.distributions.LogNormal(roi_mu, roi_sigma, name=constants.ROI_M) ) model_spec = spec.ModelSpec(prior=prior, holdout_id=holdout_id, knots=cv_knots) mmm = model.Meridian(input_data=data, model_spec=model_spec)
モデル推定のハイパーパラメータということで、knotsと事前分布をここで決めます。後述しますが、knotsはCVで決めたいので書き換えやすいようにしておいてあります。事前分布はdemo指定のデフォルト*4としました。またCVのholdoutもここで決められて、公式ドキュメントではrandom splitを例示していますが僕の例ではpast-and-future splitにしています(後述)。
MCMCサンプリング
%%time mmm.sample_prior(500) mmm.sample_posterior( n_chains=10, n_adapt=2000, n_burnin=500, n_keep=1000, seed=0 )
これで準備は出来ているはずなので、まるっとMCMCを回します。シングルコアであっても常識的なサンプルサイズであれば10分もあれば回り切ると思います。勿論、マルチコアのランタイムを契約されている場合はそちらでマルチスレッドで回した方が圧倒的に早くなります。結果はmmmというオブジェクトに格納されます。
モデル診断
model_diagnostics = visualizer.ModelDiagnostics(mmm) model_fit = visualizer.ModelFit(mmm)
まず、推定したモデルがどれくらい信頼できるかを診断しましょうということで、必要なオブジェクトを立てます。
model_fit.plot_model_fit() # 時系列プロット # model_diagnostics.plot_rhat_boxplot() # R_hatプロット # model_diagnostics.predictive_accuracy_table() # 各種パフォーマンステーブル model_diagnostics.plot_prior_and_posterior_distribution() # 事前・事後分布プロット
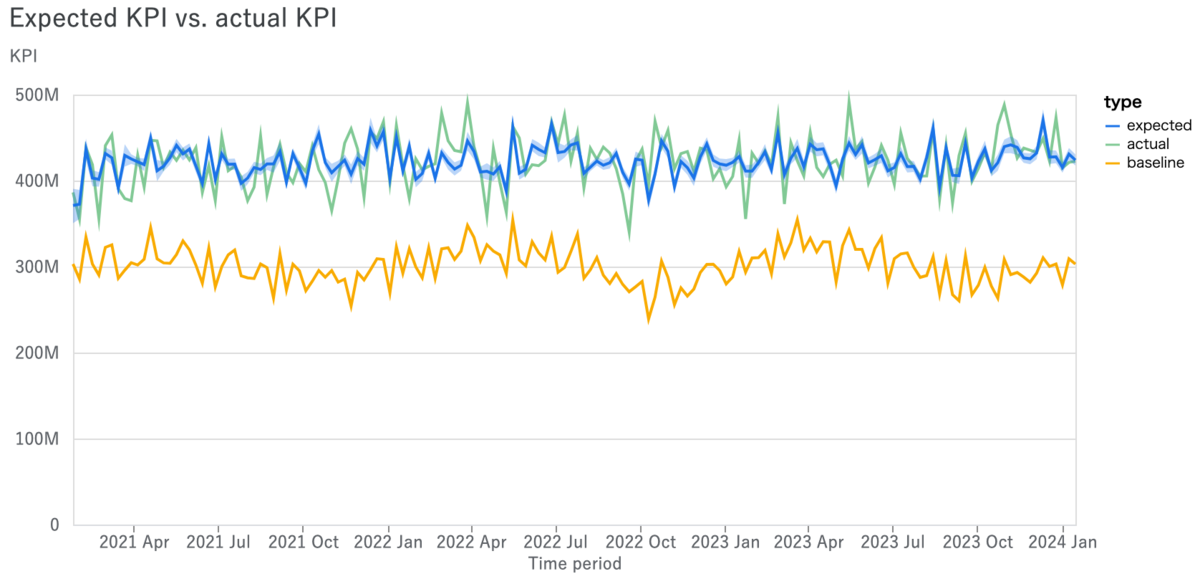
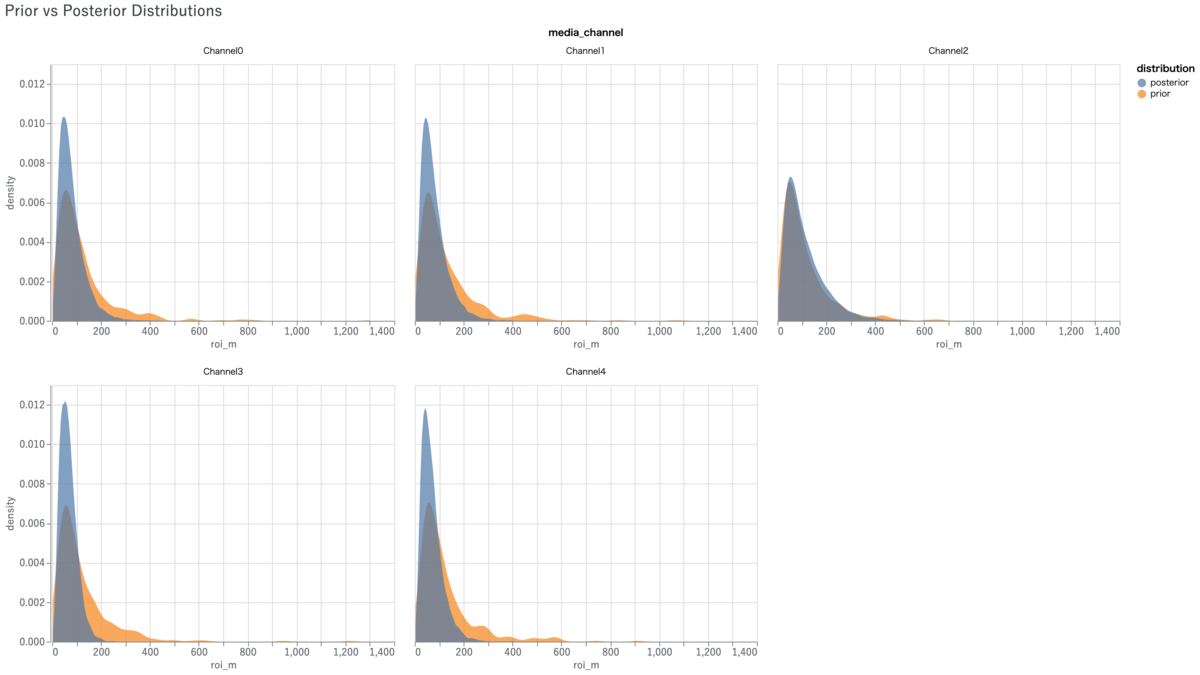
幾つかメソッドがありますが、とりあえず時系列プロットと事前・事後分布プロットだけ例として挙げておきます。Meridianでは事前分布に手を入れることが多いので、事前・事後分布プロットで「きちんと事前分布が機能しているか」「データが与える尤度の影響が十分か」を確認することが重要です。
メディア効果の可視化
media_summary = visualizer.MediaSummary(mmm) media_effects = visualizer.MediaEffects(mmm)
次に、メディア効果を見たいので必要なオブジェクトを立てておきます。
# media_summary.summary_table() # メディア効果のサマリー # media_summary.plot_channel_contribution_area_chart() # メディア貢献度の積み上げ時系列プロット media_summary.plot_spend_vs_contribution() # メディアごとの投下予算vs.貢献度比較 # media_summary.plot_contribution_pie_chart() # メディア貢献度の円グラフ # media_summary.plot_contribution_waterfall_chart() # メディア貢献度のウォーターフォールチャート # media_summary.plot_roi_bar_chart() # メディアROIプロット # media_summary.plot_cpik() # CPIKプロット # media_summary.plot_roi_vs_effectiveness() # ROI vs. effectiveness # media_summary.plot_roi_vs_mroi() # ROI vs. mROI media_effects.plot_hill_curves()['media'] # Hill curve: impなら'media'、R&Fなら'r&f'とdictで指定する # media_effects.plot_adstock_decay() # Adstock # media_effects.plot_response_curves() # Response curve
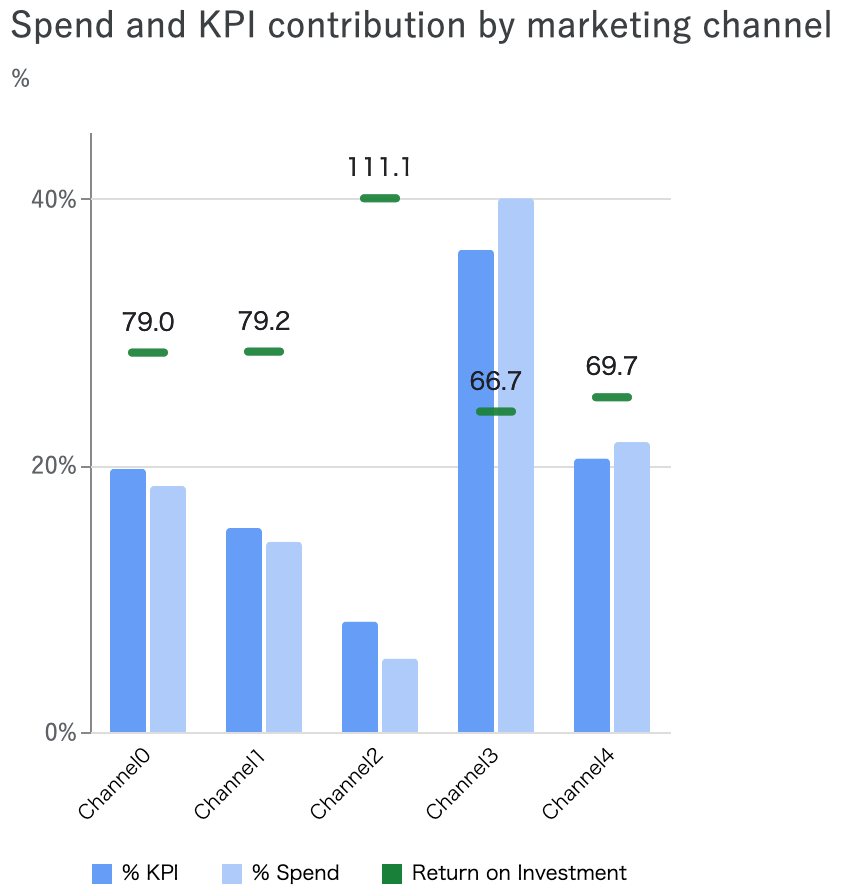
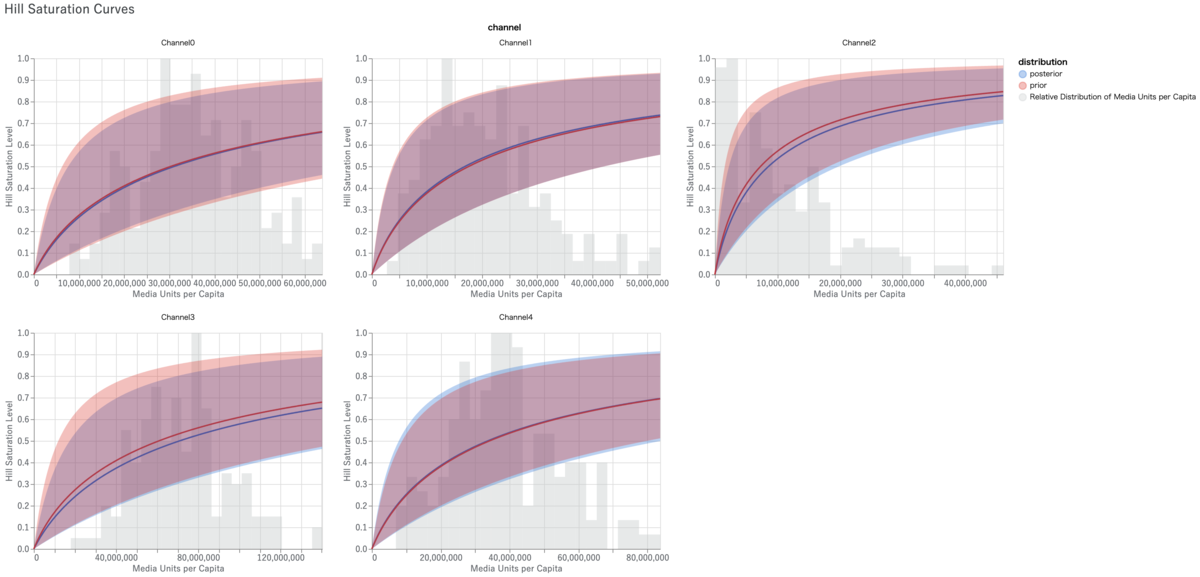
メディア効果の可視化メソッドは多岐に渡るので、例としてメディアごとの投下予算vs.貢献度比較とHill curveだけ挙げておきます。
予算配分の最適化
%%time
budget_optimizer = optimizer.BudgetOptimizer(mmm)
optimization_results = budget_optimizer.optimize(use_kpi=True)
Meridianにはグリッドサーチによる予算最適化計画のソルバがあります。LMMMの時は逐次二次計画だったので良く非凸にハマってコケていたんですが、それがなくなったのでまぁ良しとしましょう。
# optimization_results.plot_budget_allocation() # 予算最適配分円グラフ optimization_results.plot_incremental_outcome_delta() # 現状vs.最適化後比較 optimization_results.plot_response_curves() # 現状vs.最適化後response curve比較 # optimization_results.plot_spend_delta() # 現状vs.最適化後のメディアごとの予算増減
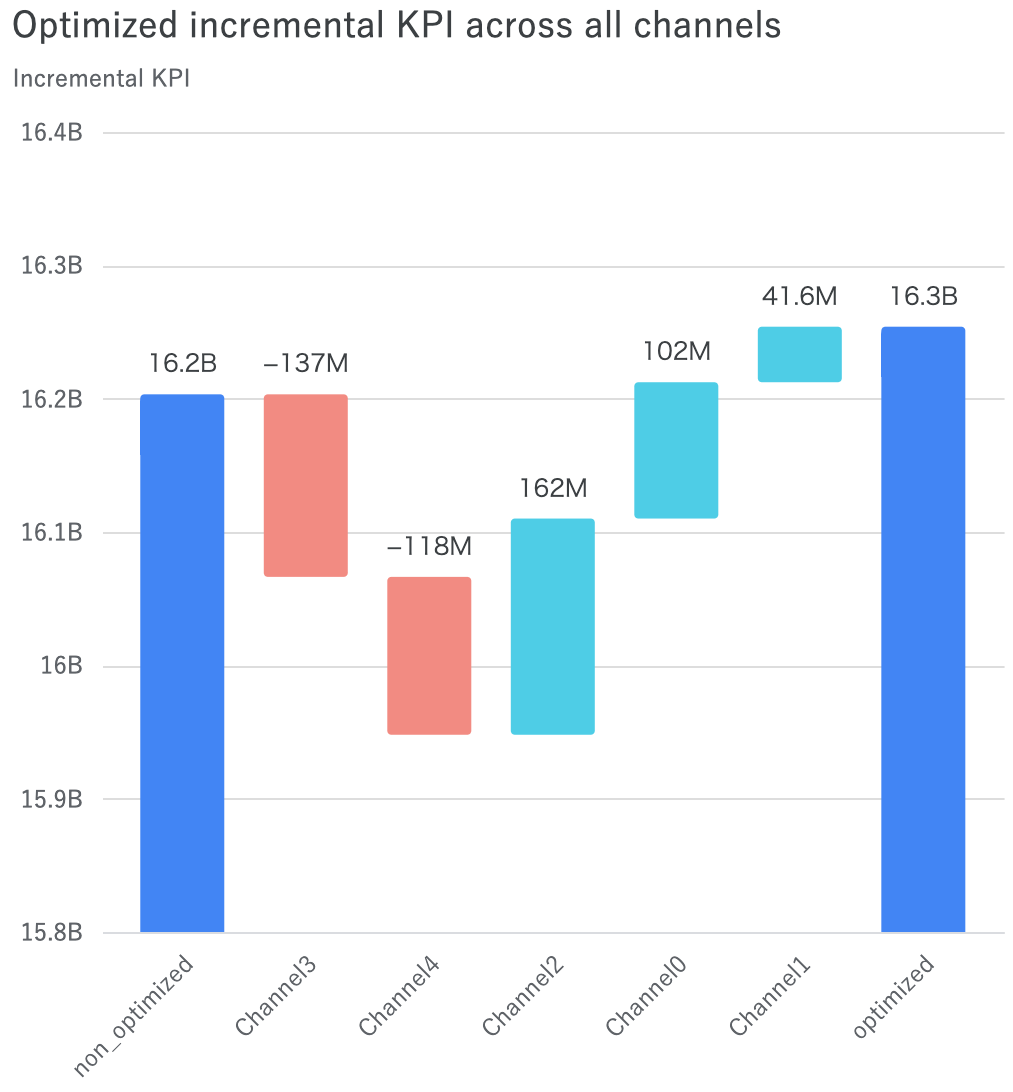
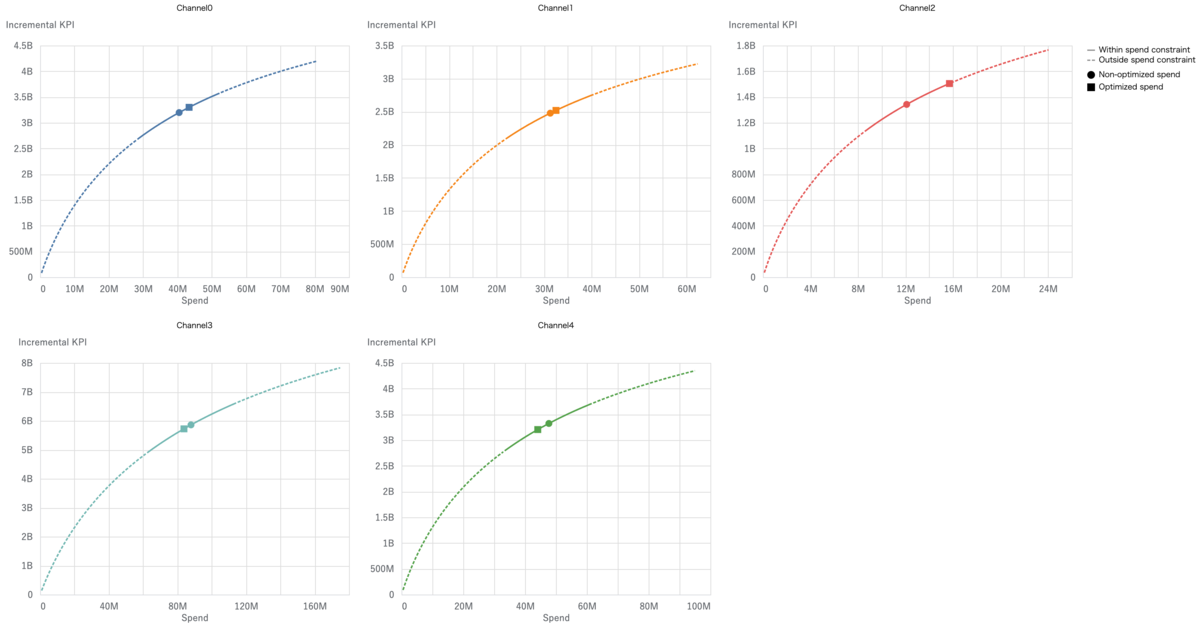
予算配分最適化計画に関しても幾つかメソッドがあるので、例として現状vs.最適化後比較プロットと現状vs.最適化後response curve比較プロットの2つを挙げておきます。
その他の機能
from google.colab import drive drive.mount('/content/drive') # メディア効果のサマリー filepath = '/content/drive/MyDrive' start_date = '2021-01-25' end_date = '2024-01-15' mmm_summarizer = summarizer.Summarizer(mmm) # Summarizerとかいうオブジェクトが必要になる mmm_summarizer.output_model_results_summary( 'summary_output.html', filepath, start_date, end_date ) IPython.display.HTML(filename='/content/drive/MyDrive/summary_output.html') # 予算配分最適化のサマリー filepath = '/content/drive/MyDrive' optimization_results.output_optimization_summary( 'optimization_output.html', filepath ) IPython.display.HTML(filename='/content/drive/MyDrive/optimization_output.html')
Meridianには、これまで紹介した各種プロットとは別に高レベルAPIを利用したリポート作成機能があります。HTMLページで作成されたものを、Google Driveに保存させることもできます。これをPDFに変換すると関係者向けに配布しやすいかもしれません。
# セーブ file_path = '/content/drive/MyDrive/saved_mmm.pkl' model.save_mmm(mmm, file_path) # ロード mmm = model.load_mmm(file_path)
PKL方式による、分析結果の保存と読み込みもできます。いずれもGoogle Driveのマウントが必要で、セキュリティ設定の変更を求められることもあるのでご注意ください。
Meridianに固有の特徴
MeridianのセールスポイントについてはAboutのページに簡潔にまとめられていますが、この記事でも改めて重要と思われる点をピックアップして紹介しておきます。
Reach & frequencyを説明変数として導入できる
Demo notebookも用意されている通りで、MeridianではTVCMやYouTubeなどのreach & frequencyデータが取得できるメディアについてはそれらを説明変数として導入できるようになっています。これにより、それらのメディアの最適なfrequencyを推定することが可能です。
明示的にメディアパラメータの事前分布を導入できる
実はこれは前身のLMMMでも工夫すれば可能だったんですが、MeridianではModelSpecの引数として明示的にメディアパラメータの事前分布を導入することができます。
トレンド・季節調整はコントロール変数と合わせて一括でスプライン回帰で対処している
これが前身のLMMMからの最も大きな変更の一つで、トレンド・季節調整はGoogle検索ボリュームなどのコントロール変数と合わせて一括でスプライン回帰で対処しています。理由としては、検索広告におけるGoogle検索ボリュームの「上流」効果をMMMに組み合わせる手法としてスプライン回帰を線形に加えるというものが7年前に提案されており*5、これを採用したためだそうです。
スプライン回帰にはGAM同様にknotsというハイパーパラメータがあるため、これをどうチューニングするかが問題となります。公式ドキュメントでは幾つかのアプローチが提案されていますが、一般的には以前のブログ記事でも論じたように交差検証で決定することとされているようです。
Pearl流因果推論のDAGを重視している
公式ドキュメントでわざわざ一つセクションを割いてまで説明している通りで、Meridianはその設計思想レベルでPearl流因果推論に基づくDAGを重視しています。また、そのDAGに基づいて増分効果を推定するように設計されています。注意点としては、Meridian自身は特にDAG関連のソルバを提供していませんので、DAGittyなど汎用のソルバを用いるよう推奨されています。
Meridianを利用する上での注意点
概ね以上の説明でMeridianを使いこなすには十分かと思いますが、従来のMMMライブラリと異なる点が多いこともあり、巷の使用例を見ている限りでは混乱が生じているケースが少なくないようです。そこで、典型的なポイントに絞って注意点を挙げておこうと思います。
最初はとりあえず全てデフォルトの設定で回してみる
既に見てきたように、Meridianは非常に多岐に渡るハイパーパラメータを備えています。このため、僕が見てきた範囲では遮二無二あれもこれもとハイパーパラメータも事前分布も徹底的に手を入れてしまい、いざ回してみたら訳の分からない結果になってしまって戸惑っているという人がかなり多い印象があります。「ヒトは選択肢が多いと却って決められない」という人口に膾炙した行動経済学の知見がありますが、まさにそれですね。
これは前進のLMMMでもそのまた元祖の実装でもそうでしたが、Meridianの各種デフォルト設定は長年に渡る研究開発の過程で「これなら大体のケースで収束する」と分かっている数値が使われています。ですので、最初はとりあえず何も考えずに全てデフォルトの設定で回してみることをお薦めします。そこで収束具合やパフォーマンスを見て、改善の余地があると思ったら手を入れていきましょう。
「トレンド」は事実上推定されない
前身のLMMMや他のMMMライブラリでは、ローカル線形トレンドに準じる形で「トレンド」を推定して分離していることが殆どです。しかしながら、Meridianでは「トレンド」は「時間変動するベースライン」として季節調整や各種コントロール変数とを合成してスプライン回帰で一括してフィットさせています。一応、ベースライン内部のテンソルからトレンド的な何かを抜いてくることは可能ですが、事実上「トレンド」は推定されていないと思ってください。基本的にMeridianはその設計思想からして「メディア効果の因果推論」に特化しており、それ以外には興味がないという作りになっています。
事前分布を導入するなら、根拠あるパラメータを用いるべき
ベイズ時系列回帰は割と些細なことでMCMCが収束しないことが多く、事前分布をカスタマイズして導入することで安定した結果を得ようという試みは割とありふれた話だと思います。しかしながら、事前分布が正しく機能するかどうかはデータから得られる尤度とのバランス次第であり、事によっては単に作為的な結果をもたらすだけということもあり得ます。特に特徴次元に対してサンプルサイズが小さく、尤度の影響が弱くて事前分布に引っ張られやすい場合は尚更です。よって、事前分布を導入するのであれば「事前の条件統制されたマーケティング実験から得られた数値」のような根拠あるパラメータを用いるべきだ、というのが個人的意見です。
ベイズ信用区間の取り扱いは慎重に
一般に、ベイジアンMMMではメディア変数の回帰係数のベイズ信用区間はかなり広く得られることが多いです。このため、パッと見では全てのメディア変数のROIの信用区間同士がべったりと重なっているということも多々あり、それをもって「メディア間でROIに差はない」と解釈されるケースも少なくないようです。しかしながら、例えばMeridianにおける予算配分の最適化計画ではベイズ信用区間が事実上考慮されていないということもあり*6、何のために信用区間を算出しているのかイマイチはっきりしないという側面もあります。よって、事前に明確にその扱い方を決めているのでもない限りは、信用区間の取り扱いには慎重であった方が良いと考えています。
ハイパーパラメータknotsのチューニングは無理のない範囲で
先述の通りで、knotsはチューニングが必要なハイパーパラメータです。一応公式ドキュメントにもチューニング指針が書かれていますが、頻繁に推奨されているknots = n_timesにするとMCMCの計算が重くなってOOMで落ちたり、MCMCが不安定になって収束しなくなる可能性があるので要注意。個人的な経験では、knots = 1から徐々に増やしていって、交差検証誤差が極小値を返した時点でチューニングを打ち切れば良いと考えています。ちなみにgeo-levelではknots = n_timesが推奨されていますが、これもknots = 1から増やしていってチューニングした方が無難です。
地域レベルモデルは個々の地域間差異には関心がない
前身のLMMM同様にMeridianもgeo-levelモデリングをサポートしていますが、これは基本的に階層効果モデルにすることでデータセットの時間方向サンプルサイズ(期間)が小さくても複数地域からデータをかき集めてくれば全体のサンプルサイズを確保できるというのが目的であり*7、個々の地域間差異には関心がないんですね。時々「東名阪の各地域の特性の違いを盛り込みたい」みたいな話を聞きますが、それは出来ない相談なのでご注意ください。なおサンプルサイズ確保が目的である以上、いたずらに多数の地域を用意するのも実は本質的ではないです。無理に47都道府県揃える必要はなく、それこそ東名阪3地域でも十分なケースが大半かと思います。
多重共線性には無理に事前分布の設定で乗り切ろうとせず、適切に対処すべき
多重共線性は回帰問題たるMMMにとっては非常に厄介な代物で、それはベイジアンMMMたるMeridianにとっても同じです。特にMMMはどのような方式であれストレートに回帰係数ベースの「説明」を目的としたモデルなので、多重共線性の対処は絶対に必要です。
ただ、観測範囲ではMeridianはベイジアンだからということで事前分布の設定だけで乗り切ろうという向きが結構あるようです。とは言え、これは先述の通り「根拠あるパラメータが既に入手できている時」に限るべきで、そうでなければ恣意性を避けるためにも、地道にVIFを見ながら変数の削減orマージで対処するべきだと考えます。
系列相関や潜在的な内生性を伴うベイズ時系列回帰モデルなので、DAGにこだわるよりバイアスを軽減することを主眼に置くべき
公式ドキュメントではこれでもかというくらいPearl流の因果推論そして適切なDAGを描いて変数調整することの重要さが説かれています。それはMeridianに限らずMMMが回帰係数の推定の尤もらしさを重視する体系である以上、当然の帰結であると言えるでしょう。ただ、そこを必要以上に深刻に捉えて「真に正しく厳密なDAG」を描こうとして、奇妙奇天烈で屋上屋を架けたかのようなDAGを作り上げた結果、変数調整に悪戦苦闘したり、あまつさえ調整した結果まともな変数が全く残らず困惑している、というようなケースが往々にして見受けられます。
そもそも論として、マーケティングの世界は極めて広汎であり、尚且つ医学・疫学・生態学といった因果推論が定着して久しい分野とは異なり、悉皆的にデータと情報を得られるようにはなっておらず何もかもがあいまいな分野です。まず、系列相関によるバイアスが非常に強いのがマーケティング分野のデータの特徴で、平均回帰性が前提とされるような因果関係の定義が難しいということがままあります。一方で、それこそ「売上が伸びたのを見て広告マーケティング費用を増やす」的な絵に描いたような内生性もあり得ますし、「メディアAの効果が良さそうなので類似のメディアBも後から投資を増やした」的なメディア変数同士の因果関係もあり得ます。また長期に渡る時系列データを相手にするので、途中で変数同士の因果関係が変わってしまう可能性もあります。確かにPearl流のDAGを用いた因果推論は強力な武器たり得ますが、それ自体と「マーケティングの世界において真に正しい因果推論が出来る」こととはまた別の話です。
よって、「正しい因果推論の『結果』」を得ようと遮二無二手を尽くすより、容易に入手できる範囲のデータを活用してシンプルにバイアスを軽減させることに集中した方が、労力もそこそこで済み合目的性も高いと個人的には考えています。それは結局のところ、生の時系列データを雑でも良いのでプロットしてみて、何と何とが関連していそうかを見極めるということに尽きると思います。
合目的性のある交差検証を意識するべき
Meridianでは交差検証は自前で時系列のarrayをholdoutとして作ってMCMCに渡す方式になっていて、公式ドキュメントでは「スプライン回帰は未来予測に適さない」という理由でrandom splitを推奨しています。これは確かに一つの考え方としてアリだと思います。
ただ、MMMで扱う時系列データのほぼ全ては系列相関を伴っており、単純なrandom splitだと容易にleakageを起こすということは指摘しておきたいです。実際、シミュレーションデータでも実データでもrandom splitだと過学習を起こす傾向があり、Meridianとてその例外ではありません。また「説明」が主目的であるといえども、その回帰係数をもとに目的変数が増えるように未来の説明変数を操作するということはhuman in the loopとしての「予測」であり、ならばその交差検証も「未来予測性能」の向上を目的としたものであるべきでしょう。
よって、個人的にはMeridianの交差検証方式にはpast-and-future splitとrandom splitとの併用を推奨しています。その方が、human in the loopとしての「予測」が必ず伴うMMMという試みにとっては合目的性が高い上に、スプライン回帰の短所もカバーできると考えられるからです。気になる人は、past-and-futureとrandomを併用して、両方ともチェックすると良いかと。
Meridian単体で無理に完結させず、適切に事前・事後の検証実験を組み合わせるべき
これは僕の観測範囲での話ですが、Meridianという強力なツールが現れたことで「優れたMMMさえあればそれだけでマーケティング上の重要な意思決定が出来る」と考える人たちが以前よりも増えたように感じられます。
しかし、どれほど因果推論をきちんと行ったとしても、MMMが「条件統制の殆どなされていない観察データに対して頑張って因果推論しようとする」試みであるという現実は変わりません。確かにMeridianはそこを補完する強力なツールですが、Meridianだけで完結させようとするのは危ういです。そして、Meridianに限らずMMMは「妥当と思われる分析結果を得るために(holdoutを切ってあったとしても)同一のデータセットに対して何度も分析をこねくり回す」ようなことをすることになるため、「二度漬け」「何度も漬け」になりがちで、そもそも論として再現性問題から逃れられないという側面があります。
よってMeridianによるMMMは「仮説出しのためのTransparent HARKing*8」と割り切り、事後の検証実験でその仮説に白黒つけるべきだ、というのが僕個人の考えです。事前の検証実験もあればMeridianの事前分布に使えますし、事後の検証実験を行えば再現性問題もある程度クリアできます。その労力は惜しむべきではないと考えます。
コメントなど
以前MMMについて包括的なまとめ記事を書いた際に「MMMはscienceではなくpoliticsである」という皮肉を綴りましたが、現状の巷におけるMMMの扱われ方を見る限りではその見方は変わりそうもない気がしています。かのBoxの有名な格言*9もきちんと続きをつけて、"All models are wrong; but some are useful, although the others are useless"と明快に言った方が良いのかもしれません。
Meridianが強力なツールであるという話と、Meridianでusefulな結果を得られるという話とは、別物であると僕個人は考えます。僕が広告マーケティング分野の実務家である限りは、後者のために尽力していく所存です。
Conflict of interests
筆者はMeridianの配布元企業に勤務しています。
*1:Lightweight MMM:NumPyroで実装されたベイジアンMMMフレームワーク - 渋谷駅前で働くデータサイエンティストのブログ
*2:Meridianのクラス設計と公式APIリファレンスが不親切ゆえに自力でデバッグし切れなかったところ
*3:例えばブランド検索数やアプリダウンロード数など
*4:対数正規分布:広く使われる半正規分布よりもゼロ付近のサンプリングが綺麗に走るのが利点です
*5:Bias Correction For Paid Search In Media Mix Modeling
*6:グリッドサーチのグリッドを切る際にパラメータ事後分布の平均を使って予測値を算出しているため→https://github.com/google/meridian/blob/main/meridian/analysis/optimizer.py#L2438
*7:MMMに週次のデータが多く1年でも52点しか確保できないのが主因
*8:https://journals.sagepub.com/doi/full/10.1177/0149206316679487
*9:MMM (Media/Marketing Mix Modeling)を回すなら、まずGeorge E. P. Boxの格言を思い出そう - 渋谷駅前で働くデータサイエンティストのブログ