以前よりGoogleではCloud AutoMLという"Learning to learn"フレームワークによる「人手完全不要の全自動機械学習モデリング&API作成」サービスを展開してきていましたが、それらは画像認識や商品推薦はたまた自然言語処理がメインで、最もオーソドックスな構造化データに対する多変量モデリングは提供されていませんでした。
が、今年のCloud Nextにおいてついに多変量モデリング版であるAutoML Tablesのベータ版が公開されたということで、既に色々な方が「試してみた」系の記事を書かれているようです。
https://medium.com/@matsuda.minori/google-cloud-next-sf-19%E3%81%A7%E7%99%BA%E8%A1%A8%E3%81%95%E3%82%8C%E3%81%9Fauto-ml-tables%E3%82%92%E6%97%A9%E9%80%9F%E8%A9%A6%E3%81%99-f5ff2f4a475b
ということで、遅ればせながら僕もちょっと試してみようと思います。ただ、単に試すだけでは面白くないので、いくつか他の機械学習モデルも用意してそれらとのパフォーマンス比較をすることとします。
L1正則化回帰とランダムフォレストとxgboostとDNN (MLP)でベンチマークを計測する
この記事では以前取り上げたことのある、UCI ML Repositoryで提供されているオンラインニュース人気度のデータセットを使います。全体でほぼ4万行のデータセットで、基本的には欠損値などもなく扱いやすいデータセットなのですが、素のままだとBigQueryに入れる際に変なところでコケたりするので、一部を僕の手元で前処理しています。その上でholdoutのテストデータを5000行分取り、残りの3万5000行程度を学習データとして、splitしたものをGitHubに上げてあります。
目的変数は"shares"つまりニュース記事がシェアされた回数ですが、これが典型的なべき分布に従う変数なのでそのまま回帰すると間違いなくおかしな結果になります。ということでこれも事前に前処理で対数変換してあります。
それではベンチマークを取っていきましょう。ここではL1正則化回帰・ランダムフォレスト・xgboost・DNN (MLP)を回すこととします。前三者はRで、DNNのみPython (Keras)で回します。
# データインポート > d_train <- read.csv('https://github.com/ozt-ca/tjo.hatenablog.samples/raw/master/r_samples/public_lib/jp/exp_uci_datasets/online_news_popularity/ONP_train.csv') > d_test <- read.csv('https://github.com/ozt-ca/tjo.hatenablog.samples/raw/master/r_samples/public_lib/jp/exp_uci_datasets/online_news_popularity/ONP_test.csv') # L1正則化回帰 > library(glmnet) > d_train.glmnet <- cv.glmnet(as.matrix(d_train[, -59]), d_train[, 59] ,family = 'gaussian', alpha = 1) > plot(d_train.glmnet) > plot(d_test$shares, predict(d_train.glmnet, newx = as.matrix(d_test[, -59]), s = d_train.glmnet$lambda.min)) > library(Metrics) > rmse(d_test$shares, predict(d_train.glmnet, newx = as.matrix(d_test[, -59]), s = d_train.glmnet$lambda.min)) [1] 0.8833394 # ランダムフォレスト > library(randomForest) > d_train.rf <- randomForest(shares~., d_train) # 結構重い > rmse(d_test$shares, predict(d_train.rf, newdata = d_test[, -59])) [1] 0.8682305 # xgboost > library(xgboost) > library(Matrix) > train.mx <- sparse.model.matrix(shares~., data = d_train) > test.mx <- sparse.model.matrix(shares~., data = d_test) > train.xgb <- xgb.DMatrix(train.mx, label = d_train$shares) > test.xgb <- xgb.DMatrix(test.mx, label = d_test$shares) > d_train.gbdt <- xgb.train(params = list(objective = 'reg:linear', + eval_metric = 'rmse', eta = 0.2), + data = train.xgb, nrounds = 40) # ハイパーパラメータは微妙に試行錯誤してある > rmse(d_test$shares, predict(d_train.gbdt, newdata = test.xgb)) [1] 0.8705567
次に、Kerasを用いたDNN (MLP)でもやってみます。JuPyter Notebookで書いたものをGitHubに上げてあります。ネットワークチューニングは以前同じデータでMXNetを用いてチャレンジした時の内容を参考にしています。
import keras from keras.layers.core import Activation from keras.layers.core import Dense from keras.layers.core import Dropout from keras.models import Sequential from keras.optimizers import SGD from keras.utils import np_utils import numpy as np import pandas as pd from sklearn.preprocessing import StandardScaler from sklearn.metrics import mean_squared_error df_train = pd.read_csv('https://github.com/ozt-ca/tjo.hatenablog.samples/raw/master/r_samples/public_lib/jp/exp_uci_datasets/online_news_popularity/ONP_train.csv') df_test = pd.read_csv('https://github.com/ozt-ca/tjo.hatenablog.samples/raw/master/r_samples/public_lib/jp/exp_uci_datasets/online_news_popularity/ONP_test.csv') x_train = df_train.iloc[:, :58] y_train = df_train["shares"] x_test = df_test.iloc[:, :58] y_test = df_test["shares"] scaler = StandardScaler() x_train.iloc[:, 0:10] = scaler.fit_transform(x_train.iloc[:, 0:10]) x_train.iloc[:, 17:28] = scaler.fit_transform(x_train.iloc[:, 17:28]) x_train.iloc[:, 37:] = scaler.fit_transform(x_train.iloc[:, 37:]) x_test.iloc[:, 0:10] = scaler.fit_transform(x_test.iloc[:, 0:10]) x_test.iloc[:, 17:28] = scaler.fit_transform(x_test.iloc[:, 17:28]) x_test.iloc[:, 37:] = scaler.fit_transform(x_test.iloc[:, 37:]) batch_size = 200 nb_epoch = 30 model = Sequential() model.add(Dense(720, input_dim = 58)) model.add(Activation('tanh')) model.add(Dense(240)) model.add(Activation('tanh')) model.add(Dense(60)) model.add(Activation('tanh')) model.add(Dense(1)) model.add(Activation('linear')) sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True) model.compile(loss = 'mean_squared_error', optimizer = sgd) model.fit(x_train, y_train, epochs = nb_epoch, batch_size = batch_size) y_predict = model.predict(x_test) rmse = np.sqrt(mean_squared_error(y_predict, y_test)) print "RMSE:", rmse
RMSE 0.9467という結果になりました。思った以上に悪いですね(汗)。ということで、ベストのベンチマークはランダムフォレストが出したRMSE 0.8682305とします。
ちなみに、真値とその最もパフォーマンスの良かったランダムフォレストの予測値とを散布図にするとこうなります。
> plot(d_test$shares, predict(d_train.rf, newdata = d_test), xlab = 'True', ylab = 'Predicted by RF')
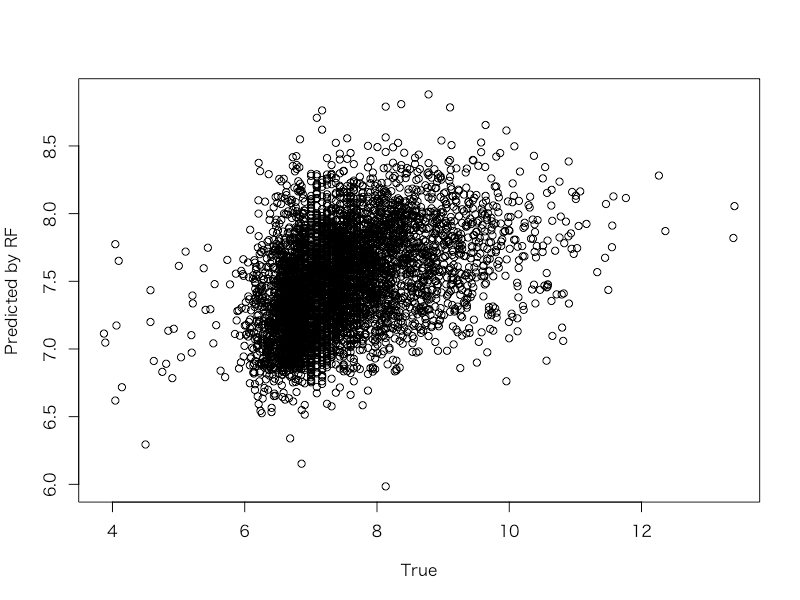
見た感じでは結構つらい当てはまりのようにも見えますね。。。
AutoML Tablesで回してみる
以下、他の方の「試してみた」記事と基本的には同じ内容ですが、順を追って説明していきます。ちなみに、どうやらAutoML Tablesでpredictionした結果は行の順番がバラバラになってしまうらしく、予めtrain / testのデータセットにきちんと主キーを充てておいて後でその順にソートし直す必要があります。よって、こちらでは主キーつきのONP_key_train.csv, ONP_key_test.csvを使います。
Cloud Storageにデータをアップロードする
おそらくtrainの方のCSVファイルが10MBを超えてしまうため、ローカルから直接読み込むというオプションが使えません。そこでBigQuery経由でAutoML Tablesにデータを読み込ませたいのですが、その前にCloud Storageにファイルを置く必要があります。適当にバケットを設定して、適当にアップロードしてください。
BigQueryにデータセットとテーブルを作成する
次に、BigQueryに適当なデータセットを作成し、その下にONP_key_train.csv, ONP_key_test.csvをインポートしてテーブルを作ります。スキーマは自動検出にしておけば大丈夫です。が、ここでカラムの型をINTEGERかFLOATか予め恣意的に決めておいた方が良いケースもあったりするので、気になる人は手動でスキーマを決めても良いと思います。ひとまずonp_key_train, onp_key_testというテーブル名にしておくことにしましょう。
AutoML Tablesでデータセットを作成する
BigQueryのテーブルが出来たら、いよいよAutoML Tablesのタブに移ります。まずここで改めてデータセットを作成します。GCPプロジェクト名、BigQueryデータセット名、BigQueryテーブル名(ここではonp_key_train)を入力します。
入力してimportボタンをクリックすると、しばらくインジケータが回って処理中の状態になります。この後のステップは全て処理中のインジケータが出ている場合はタブやウィンドウを閉じてしまっても大丈夫で、終わったらメールで通知が飛んできます。ちなみにここでCloud Storageに置いたCSVファイルから直接読み込むことも出来ますが、内部的にはどうやらBigQueryテーブルに変換している模様で、何らかの理由でBigQueryにインポート出来ないデータはここでコケてしまうので悪しからず。
AutoML Tablesでトレーニングを行う

無事データセットにデータをインポート出来たら、いよいよトレーニングのステップに入ります。まず目的変数を決め、さらに交差検証におけるデータの分割方法を決めます。デフォルトでは全データの8割が学習データに、1割がチューニングのためのバリデーションデータとして、1割がパフォーマンス評価のためのテストデータとして使われます。

なお、時系列データの場合はtimestampのカラムがあればそれを指定せよと言ってきます。これによって、時系列データの際は交差検証をrandom splitではなく前から8割を学習・その後の1割をバリデーション・一番後ろの1割を評価のために使うように設定されます。
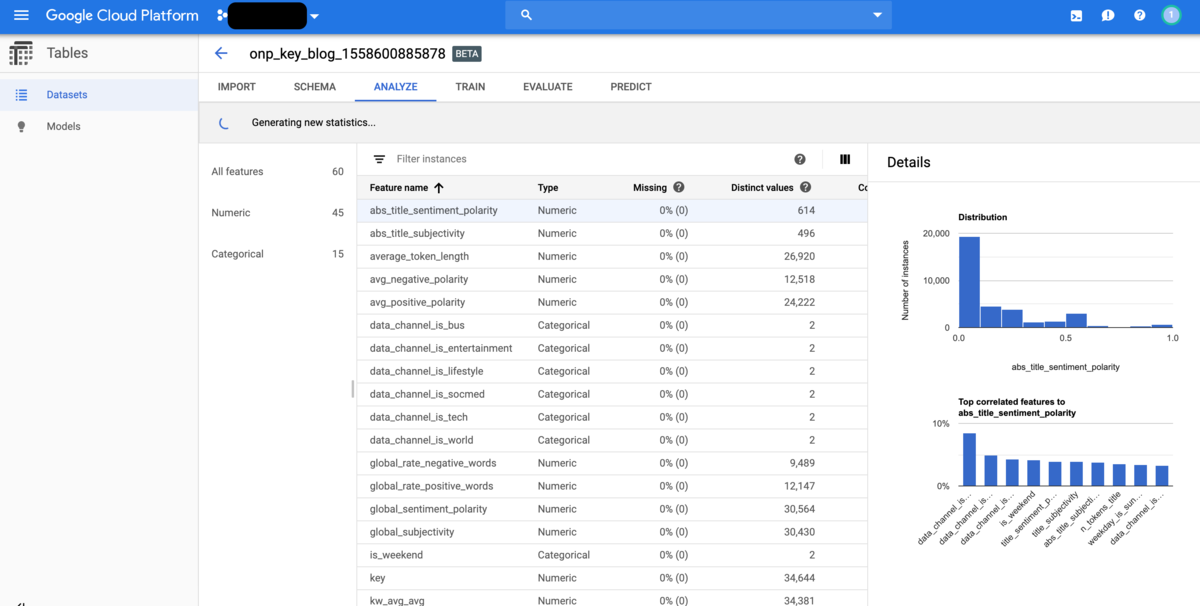
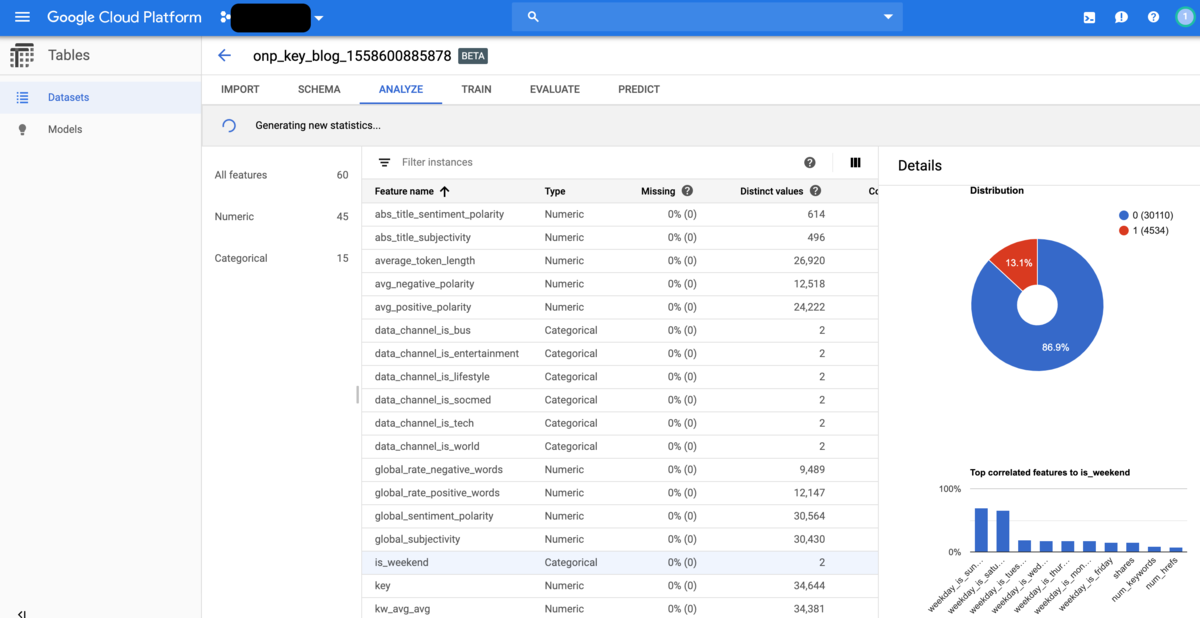
continueをクリックすると、ANALYZEのタブに移ります。ここでは各説明変数の概要を見ることが出来ます。連続変数と判定されたものについてはヒストグラムと、他の変数の中で相関が高いものを順に表示してくれます。カテゴリ変数と判定されたものについてはカテゴリごとの占める割合が表示されます。
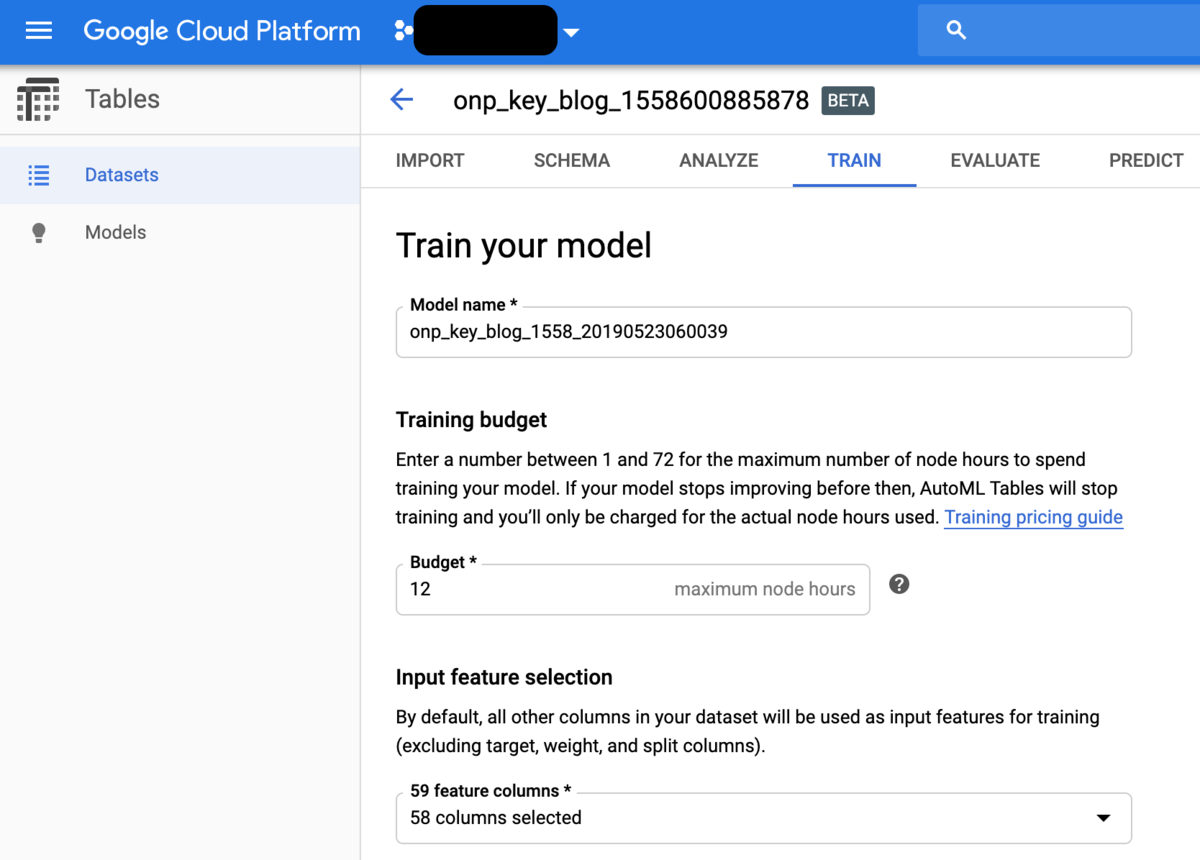
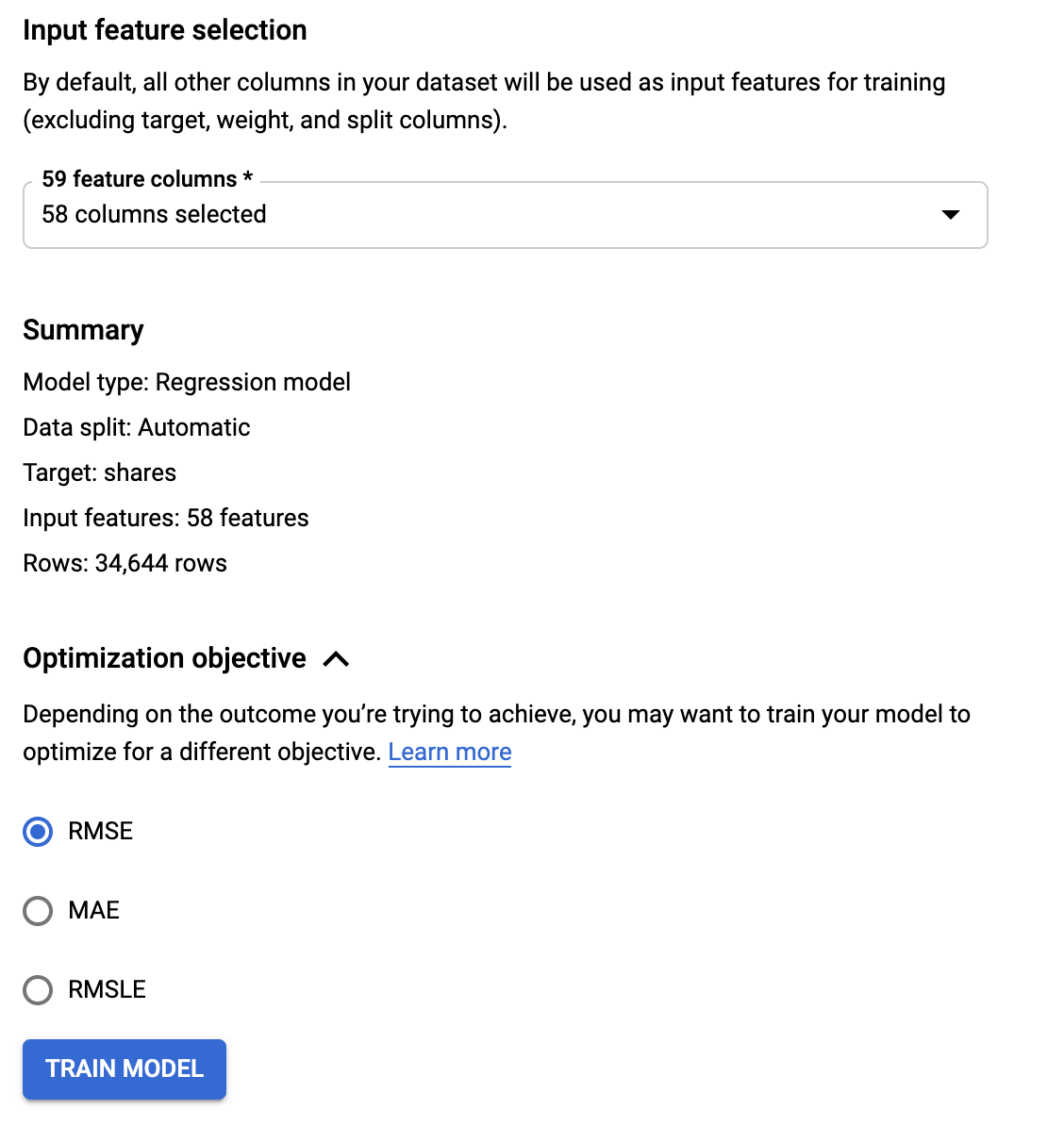
準備が整ったらTRAINのタブに移ります。Budgetではズバリ「学習時間の最大値=どこまでコストをかけられるか」を指定します。ここで12時間を指定しているのは、大人の事情ということでご容赦ください(笑)。またここで最終的な説明変数の組み合わせを指定することになるので、主キーであるkeyカラムを忘れずに除外しておきましょう。最後に、損失を何にするかここで決めます。今回は連続値への回帰なのでRMSEで大丈夫です。あとはTRAIN MODELをクリックすれば、学習が始まります。
AutoML Tablesで予測を行う
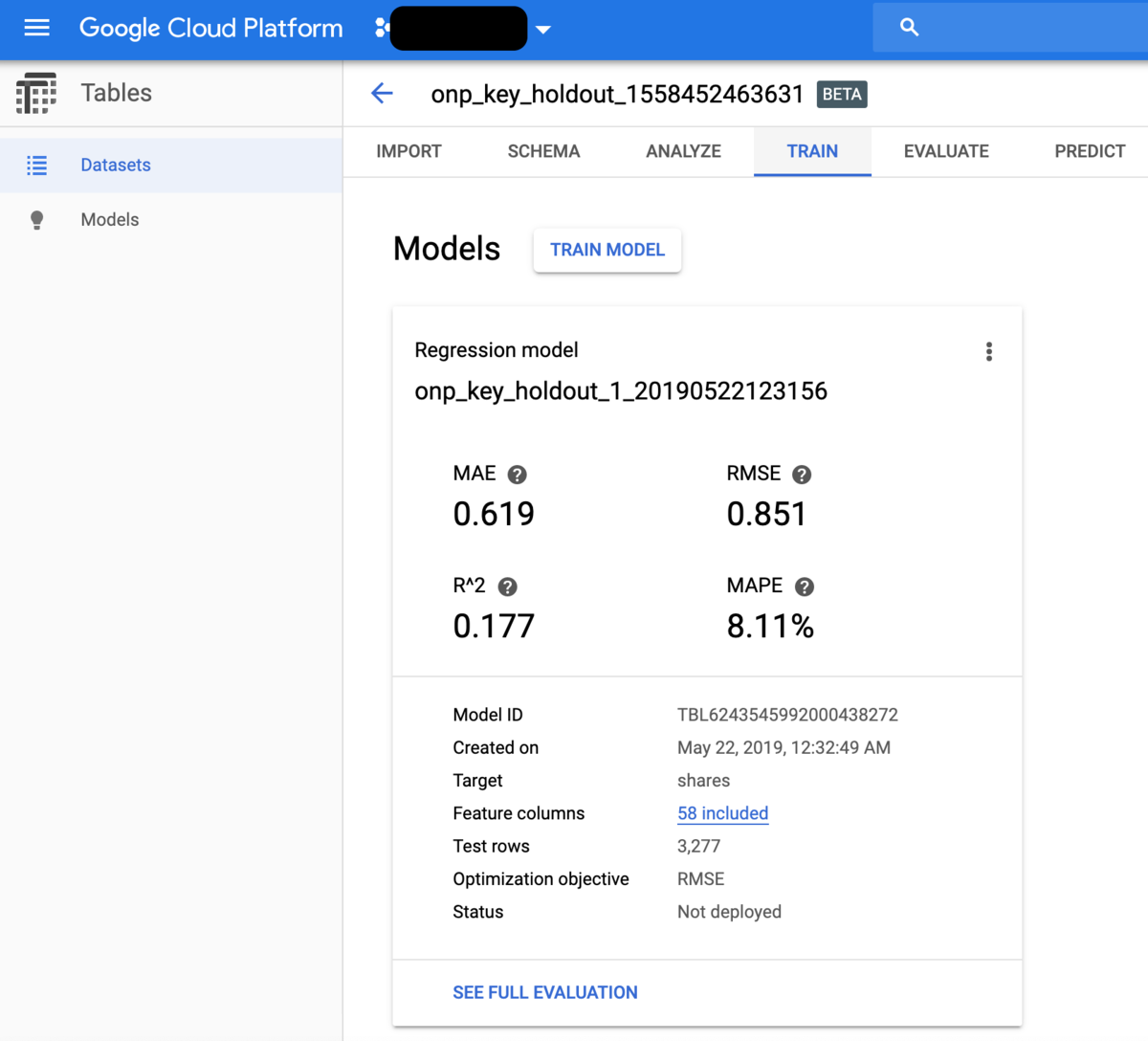
ここでは既に学習済みの別のモデルの結果をお見せします。まず、学習が終わるとモデル評価のパネルが出てきます。これによれば、交差検証による評価結果はRMSE 0.851とベストスコアです。しかしこれだけでは分からないので、きちんとテストデータに対する予測を行った上でそのRMSEを計算してみましょう。なおモデル評価の詳細はEVALUATEタグでさらに詳しく見られます。

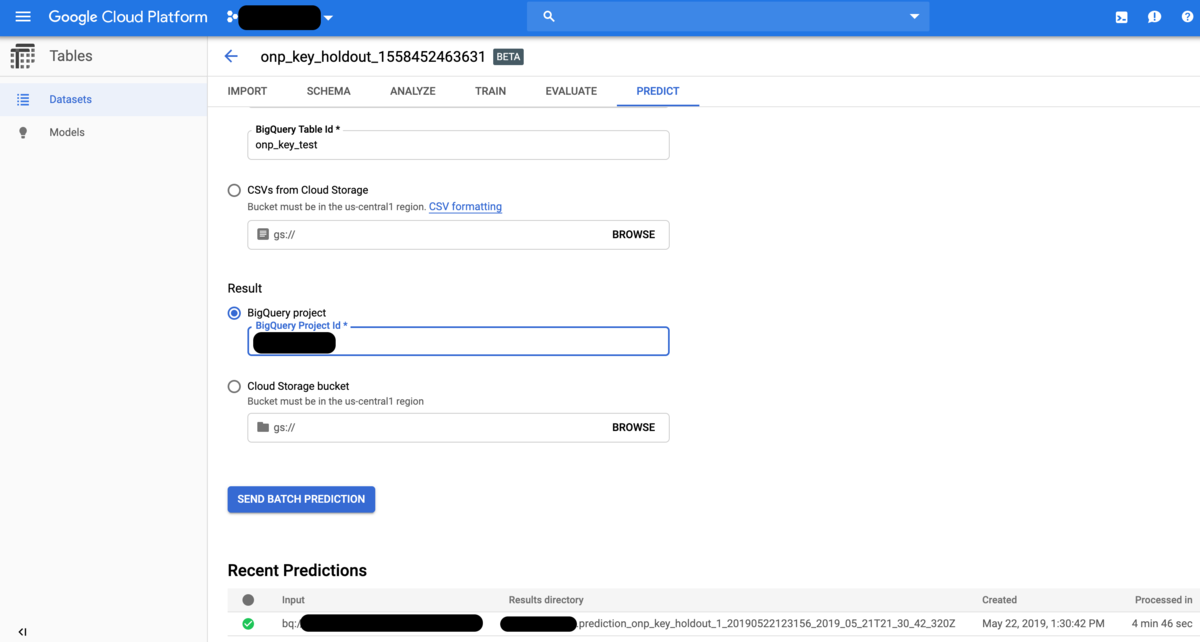
PREDICTタグに移ると、バッチで回すかオンラインで回すかを聞かれます。今回はバッチを選びましたが、皆さまご想像の通りオンラインを選ぶとAPIが自動的に作成されてデプロイすることが出来ます。つまり、実際にアプリなどで使用する場合はオンラインの方を選ぶことになります。後はデータセットを作った時と同じようにGCPプロジェクト名・BigQueryデータセット名・BigQueryテーブル名(ここではonp_key_test)を指定し、さらに予測結果のテーブルを格納するBigQueryプロジェクト名(入力と同一で良いがアウトプット先を分けたければ別にするのも勿論可能)を指定するだけです。これは5分もあれば完了しますが、BigQuery側に反映されるには10分ぐらいかかるので要注意。
prediction_で始まるテーブルが出来ていれば完成です。が、実はこれがとんでもない曲者。予測結果が何故かネストされたテーブルに格納されてしまい、そのままではSELECT文で呼び出せません。そこで上記のfufufukakakaさんの記事中のクエリを参考にして以下のようなクエリを組んで取り出してきます。これで主キーに沿ってソートされた予測値が得られます。
WITH tmp AS ( SELECT * FROM `{your_project_name}.prediction_onp_key_holdout_1_20190522123156_2019_05_21T21_30_42_320Z.predictions`) SELECT CAST(key as int64) AS key, tables.value AS shares FROM tmp, UNNEST(tmp. predicted_shares) ORDER BY key
あとはこれをCSVにしてDLしてきて、テストデータのshares変数とのRMSEを計算するだけです。勿論、そんなことをしなくてもそもそもonp_key_testテーブル内にテストデータのshares変数も入っているのでSQLクエリを書いてRMSEを計算するという手もありますが、僕は思いつかなかったので泥臭くDLしてみました。で、R上で計算してみたところこうなりました。
> rmse(pred$shares, test$shares) [1] 0.8634979
ということで、暫定的ながら自分で計算したL1正則化線形回帰・ランダムフォレスト・xgboostで出したどのベンチマークよりも、AutoML Tablesの方がギリギリながら上回ったということになりました。
ところが、これより一つ前に計算した同じデータセットに対する回帰モデルの交差検証結果はRMSE 0.828と非常に良かったのですが、その時のholdoutテストデータに対する予測のRMSEは何と0.9371312。。。つまりそのモデルはどうやら過学習を起こしていたようです(汗)*1。元々1000行以上のデータでないと受け付けず、かなりの大容量データ(それこそ10万行以上)で扱うことを前提としたプロダクトなので、35000行程度ではAutoML Tablesの仕組みが本来持つ汎化性能のポテンシャルを最大限発揮できず、そこまで素晴らしく大きな恩恵には必ずしも与れないということなのかもしれません。実際、弊社のDeveloper AdvocateのKazさんは3000万行のデータで試したという話でしたので、それくらいないとご利益はないような気もします。
とは言え、今回ベンチマークとして用意した4つのモデルとその推定結果はそれぞれを「現段階の自分が」用意するのに全部で1〜2時間ぐらい費やしており、勿論それらを用意できるようになるまでに費やした時間と労力とコストはそれ相応の規模になるかと思います(追記:以下の「追記」セクションに色々とチューニングを工夫した結果を複数載せていますが、人手である程度以上の精度を出そうとすればそれらのような努力とそれを実現するための専門知識やスキルも必要になるということです)。一方、AutoML Tablesを使えばTablesのトレーニング単体で1桁万円(budgetを8〜12時間に設定した場合)ぐらい、その他GCPの各サービスのコストも合わせれば、少なくとも僕がいなくてもこれくらいのものは出来上がるということでもあります。
特に10万行を超えるような大容量データ相手にある程度以上の精度が出る機械学習モデルを作って、尚且つAPIとしてデプロイしてアプリやサービスに使いたいということであれば、AutoML Tablesは良い選択肢になるのではないかと思います。特に、DWHとしてBigQueryにデータを貯めている環境であれば直接AutoML Tablesに流し込んで機械学習モデルを学習させることがコード不要で出来るため、非常に楽です。
またData Prepを併せて使うことで、前処理プロセスについても程度問題ながら自動化させることも出来ます。極端な話、ある程度パターン化出来るようであれば、Data Prep→BigQuery→AutoML Tables→API化→デプロイと機械学習モデルの本番環境投入プロセスの大半を自動化出来てしまうわけです。ようやくデータサイエンティストの僕も失業に近付けるかと思うと感慨深いですねぇ(棒)。
ただ、上記のように思わぬ過学習を引き起こすこともあるようなので、そういったパフォーマンスチェック、特に汎化性能のチェックのために最低1人ぐらいは運用に当たって専門家についていてもらっても良いかもしれません。ということで、自社プロダクトの宣伝でした(笑)。
ベンチマーク向けの追記
xgboostその1
xgboostについてはもうちょっと真面目にパラメータチューニングした方が良いかなと思い、{rBayesianOptimization}を使ってチューニングしてみました。
> library(xgboost) > library(Matrix) > idxgb <- sample(nrow(d_train), round(nrow(d_train) * 0.1, 0), replace = T) > dd_train <- d_train[-idxgb, ] > dd_test <- d_train[idxgb, ] > train.mx <- sparse.model.matrix(shares~., data = dd_train) > test.mx <- sparse.model.matrix(shares~., data = dd_test) > train.xgb <- xgb.DMatrix(train.mx, label = dd_train$shares) > test.xgb <- xgb.DMatrix(test.mx, label = dd_test$shares) > xgb_holdout <- function(ex, mx, nr){ + model <- xgb.train(params=list(objective = "reg:linear", + eval_metric = "rmse", + eta = ex/10, max_depth = mx), + data = train.xgb, nrounds = nr) + t.pred <- predict(model, newdata = test.xgb) + Pred <- rmse(dd_test$shares, t.pred) + list(Score = -Pred, Pred = -Pred) + } > opt_xgb <- BayesianOptimization(xgb_holdout, + bounds = list(ex = c(2L, 5L), mx = c(4L, 5L), + nr = c(30L, 100L)), + init_points = 20, n_iter = 1, acq = 'ei', + kappa = 2.576, eps = 0.0, verbose = TRUE) elapsed = 3.87 Round = 1 ex = 3.0000 mx = 4.0000 nr = 74.0000 Value = -0.8650 elapsed = 3.31 Round = 2 ex = 2.0000 mx = 5.0000 nr = 53.0000 Value = -0.8617 elapsed = 3.99 Round = 3 ex = 4.0000 mx = 4.0000 nr = 81.0000 Value = -0.8720 elapsed = 2.37 Round = 4 ex = 3.0000 mx = 5.0000 nr = 38.0000 Value = -0.8679 elapsed = 2.87 Round = 5 ex = 4.0000 mx = 4.0000 nr = 57.0000 Value = -0.8684 elapsed = 3.38 Round = 6 ex = 2.0000 mx = 4.0000 nr = 65.0000 Value = -0.8601 elapsed = 3.50 Round = 7 ex = 4.0000 mx = 4.0000 nr = 67.0000 Value = -0.8686 elapsed = 5.28 Round = 8 ex = 4.0000 mx = 5.0000 nr = 86.0000 Value = -0.8799 elapsed = 4.55 Round = 9 ex = 3.0000 mx = 4.0000 nr = 87.0000 Value = -0.8644 elapsed = 2.56 Round = 10 ex = 4.0000 mx = 5.0000 nr = 40.0000 Value = -0.8680 elapsed = 2.56 Round = 11 ex = 4.0000 mx = 5.0000 nr = 41.0000 Value = -0.8682 elapsed = 2.12 Round = 12 ex = 3.0000 mx = 5.0000 nr = 33.0000 Value = -0.8670 elapsed = 4.09 Round = 13 ex = 4.0000 mx = 5.0000 nr = 54.0000 Value = -0.8718 elapsed = 3.28 Round = 14 ex = 5.0000 mx = 5.0000 nr = 48.0000 Value = -0.8845 elapsed = 2.03 Round = 15 ex = 3.0000 mx = 4.0000 nr = 39.0000 Value = -0.8627 elapsed = 4.12 Round = 16 ex = 3.0000 mx = 5.0000 nr = 65.0000 Value = -0.8730 elapsed = 5.55 Round = 17 ex = 4.0000 mx = 5.0000 nr = 89.0000 Value = -0.8799 elapsed = 3.74 Round = 18 ex = 5.0000 mx = 5.0000 nr = 60.0000 Value = -0.8855 elapsed = 3.82 Round = 19 ex = 2.0000 mx = 4.0000 nr = 77.0000 Value = -0.8600 elapsed = 2.68 Round = 20 ex = 3.0000 mx = 4.0000 nr = 51.0000 Value = -0.8640 elapsed = 1.85 Round = 21 ex = 2.0000 mx = 4.0000 nr = 36.0000 Value = -0.8613 Best Parameters Found: Round = 19 ex = 2.0000 mx = 4.0000 nr = 77.0000 Value = -0.8600 > train.mx <- sparse.model.matrix(shares~., data = d_train) > test.mx <- sparse.model.matrix(shares~., data = d_test) > train.xgb <- xgb.DMatrix(train.mx, label = d_train$shares) > test.xgb <- xgb.DMatrix(test.mx, label = d_test$shares) > d_train.gbdt <- xgb.train(params = list(objective = 'reg:linear', + eval_metric = 'rmse'), + eta = opt_xgb$Best_Par[1] / 10, + max_depth = opt_xgb$Best_Par[2], + data = train.xgb, nrounds = opt_xgb$Best_Par[3]) > rmse(d_test$shares, predict(d_train.gbdt, newdata = test.xgb)) [1] 0.8679568
RMSE 0.8679568ということで、ランダムフォレストより良くなりましたがAutoML Tablesには一歩及ばないという結果になりました。
xgboostその2
nroundsはxgb.cvで決めるべき(というかearly stoppingが必要なパラメータなのだからベイズ最適化でチューニングするべきではない)というコメントを見かけたので、そのように変えてみました。
> xgb_holdout <- function(ex, mx){ + model <- xgb.train(params=list(objective = "reg:linear", + eval_metric = "rmse", + eta = ex/10, max_depth = mx), + data = train.xgb, nrounds = 40) + t.pred <- predict(model, newdata = test.xgb) + Pred <- rmse(dd_test$shares, t.pred) + list(Score = -Pred, Pred = -Pred) + } > opt_xgb <- BayesianOptimization(xgb_holdout, + bounds = list(ex = c(2L, 5L), mx = c(4L, 5L)), + init_points = 10, n_iter = 5, acq = 'ucb', + kappa = 2.576, eps = 0.0, verbose = TRUE) elapsed = 2.88 Round = 1 ex = 4.0000 mx = 5.0000 Value = -1.0267 elapsed = 2.20 Round = 2 ex = 5.0000 mx = 4.0000 Value = -1.0241 elapsed = 2.19 Round = 3 ex = 4.0000 mx = 4.0000 Value = -1.0142 elapsed = 2.75 Round = 4 ex = 3.0000 mx = 5.0000 Value = -1.0152 elapsed = 2.22 Round = 5 ex = 2.0000 mx = 4.0000 Value = -0.9996 elapsed = 2.80 Round = 6 ex = 4.0000 mx = 5.0000 Value = -1.0267 elapsed = 2.77 Round = 7 ex = 3.0000 mx = 5.0000 Value = -1.0152 elapsed = 2.77 Round = 8 ex = 5.0000 mx = 5.0000 Value = -1.0357 elapsed = 2.19 Round = 9 ex = 3.0000 mx = 4.0000 Value = -1.0082 elapsed = 2.75 Round = 10 ex = 4.0000 mx = 5.0000 Value = -1.0267 elapsed = 2.79 Round = 11 ex = 2.0000 mx = 5.0000 Value = -1.0044 elapsed = 2.23 Round = 12 ex = 2.0000 mx = 4.0000 Value = -0.9996 elapsed = 2.33 Round = 13 ex = 2.0000 mx = 4.0000 Value = -0.9996 elapsed = 2.23 Round = 14 ex = 2.0000 mx = 4.0000 Value = -0.9996 elapsed = 2.29 Round = 15 ex = 2.0000 mx = 4.0000 Value = -0.9996 Best Parameters Found: Round = 5 ex = 2.0000 mx = 4.0000 Value = -0.9996 > > train.mx <- sparse.model.matrix(shares~., data = d_train) > test.mx <- sparse.model.matrix(shares~., data = d_test) > train.xgb <- xgb.DMatrix(train.mx, label = d_train$shares) > test.xgb <- xgb.DMatrix(test.mx, label = d_test$shares) > > cv.round <- 100 > model.cv <- xgb.cv(params = list(objective = "reg:linear", + eval_metric = "rmse", + eta = opt_xgb$Best_Par[1] / 10, + max_depth = opt_xgb$Best_Par[2]), + data = train.xgb, nrounds = cv.round, nfold = 10) [1] train-rmse:5.652765+0.001827 test-rmse:5.652866+0.019823 # ... # [100] train-rmse:0.780023+0.001870 test-rmse:0.848173+0.017967 > nr <- which.min(model.cv$evaluation_log$test_rmse_mean) > > d_train.gbdt <- xgb.train(params = list(objective = 'reg:linear', + eval_metric = 'rmse', + eta = opt_xgb$Best_Par[1] / 10, + max_depth = opt_xgb$Best_Par[2]), + data = train.xgb, nrounds = nr) > rmse(d_test$shares, predict(d_train.gbdt, newdata = test.xgb)) [1] 0.8687695
再びランダムフォレストより悪くなりましたorz
Keras DNN (MLP)
import keras from keras.layers.core import Activation from keras.layers.core import Dense from keras.layers.core import Dropout from keras.models import Sequential from keras.optimizers import SGD from keras.utils import np_utils from bayes_opt import BayesianOptimization import numpy as np import pandas as pd from sklearn.utils import shuffle from sklearn.preprocessing import StandardScaler from sklearn.metrics import mean_squared_error df_train = pd.read_csv('https://github.com/ozt-ca/tjo.hatenablog.samples/raw/master/r_samples/public_lib/jp/exp_uci_datasets/online_news_popularity/ONP_train.csv') df_test = pd.read_csv('https://github.com/ozt-ca/tjo.hatenablog.samples/raw/master/r_samples/public_lib/jp/exp_uci_datasets/online_news_popularity/ONP_test.csv') x_train = df_train.iloc[:, :58] y_train = df_train["shares"] x_test = df_test.iloc[:, :58] y_test = df_test["shares"] merged_train = pd.concat([x_train, x_test]) scaler = StandardScaler() merged_train.iloc[:, 0:10] = scaler.fit_transform(merged_train.iloc[:, 0:10]) merged_train.iloc[:, 17:28] = scaler.fit_transform(merged_train.iloc[:, 17:28]) merged_train.iloc[:, 37:] = scaler.fit_transform(merged_train.iloc[:, 37:]) x_train = merged_train.iloc[:len(df_train), :] x_test = merged_train.iloc[len(df_train):, :] df_train = shuffle(df_train) idx = int(np.round(len(df_train) * 0.9, 0)) x_ptrain = df_train.iloc[:idx, :58] y_ptrain = df_train.iloc[:idx, 58] x_ptest = df_train.iloc[idx:, :58] y_ptest = df_train.iloc[idx:, 58] def get_model(unit1, unit2, unit3): model = Sequential() model.add(Dense(int(unit1), input_dim = 58)) model.add(Activation('tanh')) model.add(Dropout(0.5)) model.add(Dense(int(unit2))) model.add(Activation('tanh')) model.add(Dropout(0.5)) model.add(Dense(int(unit3))) model.add(Activation('tanh')) model.add(Dense(1)) model.add(Activation('linear')) return model def fit_with(unit1, unit2, unit3, lr, num_epoch): model = get_model(unit1, unit2, unit3) sgd = SGD(lr=lr, decay=1e-6, momentum=0.9, nesterov=True) model.compile(loss = 'mean_squared_error', optimizer = sgd) model.fit(x_ptrain, y_ptrain, epochs = int(num_epoch), batch_size = 200, verbose = 0) pred = model.predict(x_ptest) rmse = np.sqrt(mean_squared_error(pred, y_ptest)) return -rmse pbounds = {'unit1': (200, 300), 'unit2': (120, 160), 'unit3': (60, 80), 'lr': (1e-3, 1e-2), 'num_epoch': (50, 100)} optimizer = BayesianOptimization( f = fit_with, pbounds = pbounds, verbose=2, # verbose = 1 prints only when a maximum is observed, verbose = 0 is silent random_state=1, ) optimizer.maximize(init_points=5, n_iter=5,) for i, res in enumerate(optimizer.res): print("Iteration {}: \n\t{}".format(i, res)) print(optimizer.res['max']['max_params']) model = Sequential() model.add(Dense(int(optimizer.res['max']['max_params']['unit1']), input_dim = 58)) model.add(Activation('tanh')) model.add(Dropout(0.5)) model.add(Dense(int(optimizer.res['max']['max_params']['unit2']))) model.add(Activation('tanh')) model.add(Dropout(0.5)) model.add(Dense(int(optimizer.res['max']['max_params']['unit3']))) model.add(Activation('tanh')) model.add(Dense(1)) model.add(Activation('linear')) sgd = SGD(lr=optimizer.res['max']['max_params']['lr'], decay=1e-6, momentum=0.9, nesterov=True) model.compile(loss = 'mean_squared_error', optimizer = sgd) model.fit(x_train, y_train, epochs = int(optimizer.res['max']['max_params']['num_epoch']), batch_size = 200, verbose = 0) pred = model.predict(x_test) rmse = np.sqrt(mean_squared_error(pred, y_test)) print "RMSE:", rmse
bayes_optを使ってチューニングしてみたんですが、RMSE 0.9372と惨敗でしたorz
sgd = SGD(lr=optimizer.res['max']['max_params']['lr'], decay=1e-6, momentum=0.9, nesterov=True) model.compile(loss = 'mean_squared_error', optimizer = sgd) cb = keras.callbacks.EarlyStopping(monitor='loss', patience=10, mode='min') model.fit(x_train, y_train, nb_epoch = 100, batch_size = 200, verbose = 1, callbacks = [cb]) pred = model.predict(x_test) rmse = np.sqrt(mean_squared_error(pred, y_test)) print "RMSE:", rmse
ちなみにこの後も上記のような感じでcallbacks使ってearly stoppingかけたりしたんですが、それでもうまくいきませんでした。。。
Catboostその1
GBDT系の学習器はxgboost, LightGBMと世代が進化してきたわけですが、その第三世代に当たるCatboostというものがあると知ったので、こちらでも試してみます。チューニングはweb上で見かけたものを適当に参考にしています。
> install.packages('devtools') > devtools::install_url('https://github.com/catboost/catboost/releases/download/v0.14.2/catboost-R-Darwin-0.14.2.tgz', args = c("--no-multiarch")) > > library(catboost) > features <- d_train[, -59] > labels <- d_train[, 59] > train_pool <- catboost.load_pool(data = features, label = labels) > model <- catboost.train(train_pool, NULL, + params = list(loss_function = 'RMSE', + iterations = 5000, metric_period=10, + lr = 0.01, depth = 8, l2_leaf_reg = 80)) 0: learn: 7.3123297 total: 111ms remaining: 9m 15s 10: learn: 5.4710774 total: 1.17s remaining: 8m 48s # ... # 4990: learn: 0.7981751 total: 10m 2s remaining: 1.09s 4999: learn: 0.7980703 total: 10m 3s remaining: 0us # Dataset is provided, but PredictionValuesChange feature importance don't use it, since non-empty LeafWeights in model. > pred <- catboost.predict(model, test_pool) > rmse(d_test$shares, pred) [1] 0.8664872
ランダムフォレストは上回りましたが、僕の今この瞬間の環境*2ではAutoML Tablesにごく僅かに及ばずという結果になりました。でもCatboost面白そうなので、今後もっと使ってみようかと思います。
Catboostその2
「公式のチューニングガイドを読め」というお叱りをいただいたので、とりあえずクイックに出来ることとしてone hot vector(ダミー変数)で入っている変数をカテゴリ変数に直して、再度同じパラメータでやってみました。データフレーム名に2がついてます。
> names(d_train2) [1] "n_tokens_title" "n_tokens_content" "n_unique_tokens" [4] "n_non_stop_words" "n_non_stop_unique_tokens" "num_hrefs" [7] "num_self_hrefs" "num_imgs" "num_videos" [10] "average_token_length" "num_keywords" "kw_min_min" [13] "kw_max_min" "kw_avg_min" "kw_min_max" [16] "kw_max_max" "kw_avg_max" "kw_min_avg" [19] "kw_max_avg" "kw_avg_avg" "self_reference_min_shares" [22] "self_reference_max_shares" "self_reference_avg_sharess" "is_weekend" [25] "LDA_00" "LDA_01" "LDA_02" [28] "LDA_03" "LDA_04" "global_subjectivity" [31] "global_sentiment_polarity" "global_rate_positive_words" "global_rate_negative_words" [34] "rate_positive_words" "rate_negative_words" "avg_positive_polarity" [37] "min_positive_polarity" "max_positive_polarity" "avg_negative_polarity" [40] "min_negative_polarity" "max_negative_polarity" "title_subjectivity" [43] "title_sentiment_polarity" "abs_title_subjectivity" "abs_title_sentiment_polarity" [46] "shares" "data_channel" "weekday" > names(d_test2) [1] "n_tokens_title" "n_tokens_content" "n_unique_tokens" [4] "n_non_stop_words" "n_non_stop_unique_tokens" "num_hrefs" [7] "num_self_hrefs" "num_imgs" "num_videos" [10] "average_token_length" "num_keywords" "kw_min_min" [13] "kw_max_min" "kw_avg_min" "kw_min_max" [16] "kw_max_max" "kw_avg_max" "kw_min_avg" [19] "kw_max_avg" "kw_avg_avg" "self_reference_min_shares" [22] "self_reference_max_shares" "self_reference_avg_sharess" "is_weekend" [25] "LDA_00" "LDA_01" "LDA_02" [28] "LDA_03" "LDA_04" "global_subjectivity" [31] "global_sentiment_polarity" "global_rate_positive_words" "global_rate_negative_words" [34] "rate_positive_words" "rate_negative_words" "avg_positive_polarity" [37] "min_positive_polarity" "max_positive_polarity" "avg_negative_polarity" [40] "min_negative_polarity" "max_negative_polarity" "title_subjectivity" [43] "title_sentiment_polarity" "abs_title_subjectivity" "abs_title_sentiment_polarity" [46] "shares" "data_channel" "weekday" > features <- d_train2[, -46] > labels <- d_train2[, 46] > train_pool <- catboost.load_pool(data = features, label = labels) > model <- catboost.train(train_pool, NULL, + params = list(loss_function = 'RMSE', + iterations = 5000, metric_period=10, + lr = 0.01, depth = 8, l2_leaf_reg = 80)) 0: learn: 7.3132104 total: 227ms remaining: 18m 54s 10: learn: 5.4738623 total: 1.88s remaining: 14m 11s # ... # 4990: learn: 0.7963038 total: 17m 23s remaining: 1.88s 4999: learn: 0.7962692 total: 17m 25s remaining: 0us # Dataset is provided, but PredictionValuesChange feature importance don't use it, since non-empty LeafWeights in model. > test_pool <- catboost.load_pool(d_test2[, -46]) > pred <- catboost.predict(model, test_pool) > library(Metrics) > rmse(d_test2$shares, pred) [1] 0.8645785
あれ、これでもまだうまくいかない。。。まだ他にもtipsがあるようなのでもうちょい勉強してみます。
AutoML Tablesその後
7月に入ってから多少バージョンが上がったので、再び試してみたらRMSE 0.8611721に到達しました。が、データの行数を考えるとこれ以上は向上しない気もします。。。
*1:ありがちな話として乱数シードの違いに鋭敏に反応してしまったりとか
*2:チューニングは勿論多分乱数シードなども絡みそう。。。と思ったらどうやらそういう話ではなく、単にきちんとGBDTの特性を理解してval_lossをとってearly stoppingするとか、Catboostはone-hotが苦手なのでカテゴリカル変数に直すとか、そういう公式ドキュメントの推奨に従うのが正しいようです。詳細はこちら https://catboost.ai/docs/concepts/parameter-tuning.html