(By Gufosowa - Own work, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=82298768)
ここ最近、事あるごとに僕が色々な人たちに提案している概念として"ML design"というものがあります。これは元々"ML Ops"(DevOpsと同じように機械学習のシステム基盤などを包含する考え方)に対して「機械学習モデリングを運用する上で注意すべき点って多いよね」ということで、その注意点をまとめたものを一つの体系として扱えないかという趣旨で僕が勝手に言い出したものです。
言い方を変えると、統計分析に適したデータを集めるための実験計画法(experimental design)があるのと同じように、機械学習に適したデータの集め方やその交差検証などのやり方についてもまとめた計画法(design)があっても良いのでは、というのが僕が考えたオリジナルの課題意識です。実験計画法だとラテン方格とか色々習うわけですが、機械学習の世界ではそういう話は意外とまとまって教科書には載っていません。勿論それがコンペの成績に直結するKagglerや実データによる性能検証が論文の肝になるような研究者の間では常識なのでしょうが、近年になって急増した機械学習エンジニアを初めとする実務家の、特にジュニアレベルの人たちには意外と知られていないことが少なくないという印象があります。
これ自体は割と以前から考えていたことで大した話ではないと思っていたのですが、最近になってその重要性を実感する機会が増えてきました。それは、AutoML技術の普及です。
大手tech各社含めて非常に多くのML enterprise playersがAutoML即ち機械学習の自動化ソリューションを提供するようになって久しく、特にこの1-2年でそのユーザーもグッと増えた感がありますが。。。それまで全く機械学習の経験も全くないのに巷で付け焼き刃でAutoMLを触っている人たちを見ていると「???」となることが少なくないんですね。
例を挙げていくと「人工知能なんだから何でも出来るよね」と言って回帰でも分類でもないLTV (Life Time Value)推定モデルを何故か走らせようとしたり、不均衡データの補正を全く行わずに分類モデルを作って「ACC 98%だ、これすげー!」と喜んでいたり、はたまた全力でリークだらけのデータをかませて「ACC 100%だ、俺完璧じゃん!」とドヤ顔していたり。。。そんな光景、皆様の周りでも見られたりしませんでしょうか?*1
というような悲喜劇や狂騒曲を避けるべく、機械学習のモデリング手法や理論やアルゴリズムといったコアの「外側」にある「メタ」な枠組みについて、僕が個人的に考えたところをまとめてみようと思います。なお、毎度のことで恐縮ですがここで挙げているのは僕の個人的な理解に基づく個人的な持論に過ぎません。以前同様に誤りや理解不足の点がありましたらどしどしご指摘いただけると有難いですm(_ _)m
ML design各論
基本的にはこちらの書籍を下敷きにしました。

昨年平松さんからご恵贈いただいた「Kaggleで勝つ」本こと、日本の凄腕Kagglerの方々による珠玉の一冊です。この中でも特に第2・5章が今回のテーマにとってかなり重要な内容ではないかと思われます。以下重要ポイントを挙げていきますが、既に冒頭で述べたように「機械学習そのものというよりもAutoMLのような機械学習モデリングを自動的にやってくれるソリューションを利用する上で気をつけるべきこと」にフォーカスしていくため、多少つまみ食い感がある点はご容赦を。
目的変数の性質と最適化のターゲット
基本的には「分類」(classification)をしたいか「回帰」(regression)をしたいか、の二択です。厳密に両者を分けようとすると実は物凄く大変なのですが、ML designという観点からは以下のように分けると良いのかなと。
- 概念
- 分類:特徴量に基づいて「A, B, C, ...」に分けるモデルを推定する(Statistical classification - Wikipedia)
- 回帰:特徴量に基づいて「0.2, 0.4, 0.5, 0.7, ...」といった連続値にフィットする線を引けるモデルを推定する(Regression analysis - Wikipedia)
- 最適化のターゲット
ただし、世の中にはいわゆる「AI」を作った時に単純にこの2種のどちらかに確実に分けられるとは限らない課題が出てくることもあります。代表例で言えば"Life Time Value"(生涯顧客価値)の推定などで、一般には"Buy Till You Die" (BTYD)モデルを使うことがあるのですが、これは単純な回帰ではないためにただテーブルデータを持ってきただけではどうにもならないことが多いです。
特徴量の性質
AutoML的なソリューションではよしなにやってくれることが多いポイントなので、あえて気をつけるべきは「欠損値」かなと。最もお手軽な欠損値の処理方法としては「なかったことにする」即ち欠損値を含む行をスキップしてしまうことなのですが、これだと強いバイアスがかかる可能性があります。
ちょっと前だと多重代入法などで対処することが勧められていたものですが、最近では「Kaggleで勝つ」本にもあるようにGBDTなどの決定木系のアルゴリズムでは「欠損値を入れたままでもよしなにしてくれる」ことがあるので、基本的には欠損値のある行はスキップせずに残した方が良いようです。また多重代入法以外の方法で補完する、欠損値に何かを埋めた上で同時に欠損値の有無を表す変数を追加する、と言った対処法が「Kaggleで勝つ」本では言及されています。いずれにせよ、一昔前とは違い欠損値もしっかり使っていくことが大事だと言えそうです。
汎化性能 / 過学習
これは以前のブログ記事でも散々論じた内容かと思います。
「受験勉強で過去問だけ覚えてしまえば過去問は解けるようになるが本番の入試問題が解けるようになるとは限らない」という喩えの通りで、学習データへの当てはまりばかり良くてもテストデータへの当てはまりが良くなければ意味がありません。学習データにばかり当てはまりが良くなると、学習データの中のノイズにまでフィットしてしまい却って予測精度が下がる「過学習」が起きるということを知っている必要があります。未知のデータへの当てはまりの良さを「汎化学習」と呼ぶ、というのも既出の通りです。
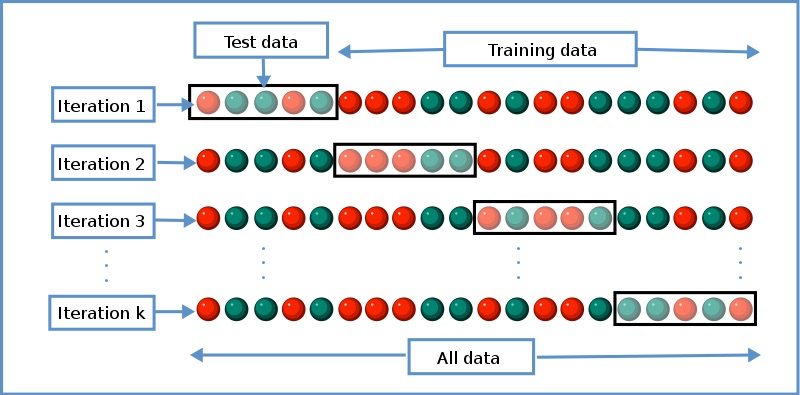
交差検証
上記の注意の如く過学習を避けて汎化性能を高く保つためには、学習データと検証データとテストデータとにデータセットを分割して、学習データで推定したモデルの汎化性能を検証データでチューニングしつつ、最後にテストデータに対するスコアを評価する、という「交差検証」の手順をふむ必要があります。
これは鉄板中の鉄板の話題に見えて、実はこれがAutoML時代でも大きな落とし穴になるポイント。何故なら「自動的に(例えば)8:2にsplitする」だとうまくいかないことが多々あるからです。「Kaggleで勝つ」本のカテゴリ分けを踏まえつつ、テーブルデータ・時系列データのそれぞれに対して以下のように交差検証の方法を示しておきます。
- テーブルデータ
- hold-out法:シンプルに学習・検証・テストデータにランダムに振り分けるもの、最も単純
- k-fold法:上記のhold-outをデータの振り分け方(fold)をランダムに変えながらk回繰り返し、その精度の平均値などで評価するもの
- stratified k-fold法:各foldごとに含まれる分類クラスの割合を一定に保ちながらk-foldを行うもの
- group k-fold法:IDに紐づいたデータなどランダムに分類すると同じIDの塊が入るようなケースで、IDごとにsplitしてk-foldを行うもの
- leave-one-out (LOO)法:k-foldを「1行ごと」にfoldして行うもの、最も計算時間が長くなる
- 時系列データ
- 時系列hold-out法:全期間のうち前の方XX%を学習データ、その後YY%を検証データ、最後の(100-XX-YY)%をテストデータとするもの
- sliding windowによるhold-out方:上記の時系列hold-outを"sliding window"的に時間をずらしながら行うもの、以前の記事を参照
時系列データは一般には系列相関(自己相関)やトレンドを伴うことが少なくないので、単純にランダムに分割してk-fold方などを行うとそれらの系列相関やトレンドに由来するリーク(後述)や共変量シフトの影響を受けて交差検証の結果が歪められることがあります。詳細は過去記事などをお読みください。
リーク (leakage)
AutoML時代でも侮れないのがリーク(leakage)。リークの恐怖については以前記事にしたことがあります。
端的に言えば「テストデータの中にあるべき変数が学習(訓練)データに洩れて(leak)しまっていること」によって不当に機械学習モデルの精度が高騰してしまう現象で、様々なシチュエーションがあり得ます。かつてKaggle内部のWikiページには以下のような定義が書かれていました。
- Leaking test data into the training data.
- Leaking the correct prediction or ground truth into the test data.
- Leaking of information from the future into the past.
- Retaining proxies for removed variables a model is restricted from knowing.
- Reversing of intentional obfuscation, randomization or anonymization.
- Inclusion of data not present in the model's operational environment.
- Distorting information from samples outside of scope of the model's intended use.
- Any of the above present in third party data joined to the training set.
市井のテーブルデータにありがちなのが「目的変数として設定したラベルに完全に連動して付与される別のラベルを説明変数に入れたまま機械学習を回してしまった」みたいなケースで、こういう時は何もしていないのに勝手にACC 100%とか99.8%みたいな数字が出てきてギョッとするのですぐ分かります。
Early stopping
これは外でもない僕自身が以前の記事でやらかしたダメなやつですorz
一般にNNや樹木モデルなど同じ学習データを何度も繰り返しスキャンして学習を深めていく系の手法では、どこかでその繰り返しを止めないと過学習を起こしてしまいます。そうなる前に、検証データへの予測精度の向上が頭打ちになったところで学習を止めるというテクニックがあり、これをearly stoppingと言います。これはAutoML系のプロダクトでも取り入れられているものが多いので、忘れずにやっておきたいところです。
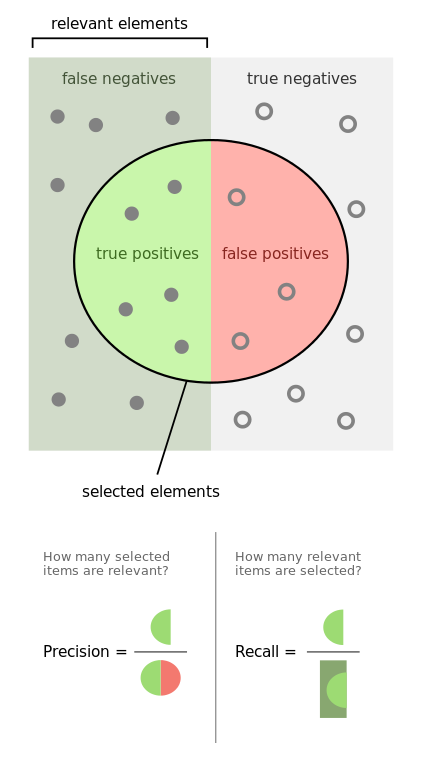
性能評価及び不均衡データへの対応
これは過去にも色々な記事で論じたことがあります。主要な記事で言えばこちらでしょうか。
概して、世の中のデータの分類データセットの多くが不均衡(imbalanced)データ、即ち0/1のラベルの割合が大きく偏っていたり、A, B, C, ...のラベルが均等ではなく割り振られていたりするものです。例えば0の数 : 1の数 = 995 : 5みたいな不均衡データをそのまま馬鹿正直に機械学習モデリングすると、全部0のラベルを出力したけどACC 99.5%でやったー!みたいな間抜けな話になりかねません(笑)。よって不均衡データに対してははっきり明示的に補正する必要があります。
補正の方法は上記の過去記事でも論じたことがありますが、baggingを伴う手法はやはり計算が重くなるせいかあまり好まれないようで、AutoML系のプロダクトではclass weightをかける方法が好まれている模様で、実際に別カラムで指定させる仕様のものもあったりします。
(By Walber - Own work, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=36926283)
しかしながら、上記の記事でも指摘したように一般に不均衡データに対する補正をかけるとfalse positive(偽陽性)が増えてしまうことが多いです。この場合、何をモデルの性能評価指標として用いるかは悩ましいところです。例えば1だと予測したものが実際に1である方が嬉しいのでPrecisionを重視するのか(偽陽性を減らしたい)、それとも実際に1であったものが1であると予測される方が嬉しいのでRecallを重視するのか(偽陰性を減らしたい)、もしくは両者の調和平均であるF1-scoreを重視するのか。不均衡データだけはAutoMLがどれほど進歩しても解決の難しい、厄介な代物として残り続けると思います。
ちなみに医学・疫学における「感度」「特異度」の議論も全く同じで、本質的には「何を最も重視したいか」に依存します。実際、この辺の資料を調べると機械学習分野と同じくらい医療分野のものも出てくるので、両者の問題意識はオーバーラップしているのだなとよく感じます。
その他補足や雑感など
ここで言いたかったのは、再掲になりますが「AutoML時代に入って誰でも気軽に機械学習モデリングが出来るようになったとしても、これだけは知っておかなければいけない」というメタなポイントのまとめです。ですので、AutoML技術を使わず程度問題ながら自らコードを書いて機械学習モデルとそのシステムを構築していきたかったら、他にも多くのことを学ぶ必要があると考えています。
結局のところ、AutoML時代に入って以降は機械学習エンジニアやデータサイエンティストのような「ある程度分かっている」人たちだけでなく、「ぶっちゃけ難しいことは何も分からない(できれば勉強したくない)」*2という人たちも、その気軽さからAutoMLを使うことで機械学習の世界に参入してくることが予想されます。
そうなった時に「いやいや不勉強な人々のことなんか知ったこっちゃない」と突き放すのではなく、また一方で「無理してでも数式だらけの本を読んで勉強しろ」と強いたりするのでもなく、「まずはこういう機械学習のメタな部分だけでも学んでみようよ」という方向性を示すことが必要なのではないかと、目下考えているところです。実際、上の方で取り上げたことはどれも数式を要さない*3概念的な話題ばかりで、科学的な思考が出来る人であれば誰でもある程度は理解できる事柄のはずです。
それをまとめたものを"ML design"と(適当に)総称して、AutoML時代に新たに参入してくる人たちに広められたら良いかな、と個人的には思っています。そういう試みの先に、真に機械学習そしてAIが社会に広まっていく「ML/AIの民主化」が成った世界が広がるのかもしれません。