少し前の話ですが、現在COVID-19の感染が拡大している地域で実施される「蔓延防止等重点措置(まん防)」に効果があったかどうかについて、計量経済学的な観点に基づいた政策評価レポートが公開されて話題になっていました。
追記
本日午前中に元のレポート自体が更新されていたようで*1、今回の記事はその更新を反映していない点悪しからずご了承ください。
で、結論はともかくその手法とアプローチについては色々と議論が起きているようです。例えば、上記のブログ記事では実際に東京都のデータで追試をしてみて、もう少し異なるやり方があるのではないかと指摘しています。
この辺は僕にとっても同様で、普段から同様のデータ分析を広告・マーケティング分野で手掛けている身としては「自分ならこうしたい」と思われるポイントが幾つかあり、折角データソースや背景となる行政措置の詳細などがレポート中で明記されているのだから、いっそ自分で追試してみようかと思ったのでした。
ということで、以下にその過程と結果をまとめて置いておきました。なお、今回の取り組みはあくまでもその「手法とアプローチ」に着目したものであり、「結果」にはあまり関心がありませんので、後者についての議論は一旦傍に置かせてください。
分析する前に考えたこと
元のレポートでは「まん防が実施された日付を境にpre/post期間に分けたDID(Difference in Differences: 差分の差分法)と見做して分析した」ということが書かれています。経験上、このような「介入はあるがその介入の方法がコントロールされていないタイプの観察データ」を実験データの代わりとして扱うと大体おかしなことになりやすいし、特にこのケースでは「隣接する地域同士で影響を及ぼし合わない」という仮定*2を満たしているとは言い難いので本当は避けたいのですが、今回はこれ以外のアプローチが割と難しいので目を瞑ることとし、「あえて」DIDでやってみることとします。
また、色々な要因で各都道府県のデータの補正が行われていますが、僕の追試では面倒だったので一律「最小値が0&最大値が1」となるような正規化をかけることにしました。勿論問題はないわけはないと思いますが、単純に時系列の「上下動」にのみ興味があるのであればこの方法でも多分何とかなるはずです。

さらに、毎日チェックして分析している東京都のデータから察するに、陽性者数以外の指標はかなり遅延して介入の影響が出ることが多く(一般に重症者数は2週間遅れ&死亡者数は4週間遅れとされる)、今現在観測されているデータだけでは確たることは言いにくそうだと思われます。加えて、上に示した東京都のコロナ4指標(正規化&季節調整済み)プロットからも見て取れるように、そもそも他の指標は基本的には全て陽性者数の遅延指標だとも言えます。ということで、元のレポートとは異なり純粋に&簡単のため陽性者数だけを分析対象に選んでいます。
加えて、平行トレンド仮定に注目することはDIDでは重要です。これについては、DTW (Dynamic Time Warping)による時系列クラスタリングを用いてコホート(観察集団)を切り、そのコホート内で介入群・対照群に分けるということを考えました。DTWによる時系列クラスタリングはRだと{TSclust}というパッケージで実装されており、上記のブログ記事にその解説があります。
最後に、元のレポートではトレンドなどを除去しています。ですが、広告・マーケティング分野のデータでDIDをやる際はほぼ確実にトレンド(というか単位根過程)が乗る上に、そのトレンドの積み増しとか加速とかが重要だったりするので、これを除去してしまうと良く分からない結果になりがちです。ということで、ベイズ構造時系列モデルの実装であるBSTSで7日周期成分とトレンド(ローカル線形トレンド)を処理し、そのモデルに基づいたCausalImpact分析で検証するというアプローチを取ることにしました。
なお、CausalImpactそのものについての解説はこちらの記事が群を抜いて詳しくまとまっているのでお薦めです。端的に言えば、DIDとSCM(シンセティック統制法)を「適度に」*3組み合わせて、反実仮想モデルを用いて因果効果を推定するフレームワークです。
実際に分析してみた結果
今回初めてRカーネルのJuPyter Notebookを書いてみた*4ので、GitHubに上げておきました。以下、各セルについてコメントしておきます。相変わらずのクソコードなのは平にご容赦くださいm(_ _)m
### Import required libraries ### # FYI: this notebook requires {CausalImpact}, {TSclust} & {tidyr} library(CausalImpact) library(TSclust)
### Import the original dataset and prerprocess ### # CSV file from Toyo Keizai's COVID-19 dashboard d <- read.csv('https://toyokeizai.net/sp/visual/tko/covid19/csv/prefectures.csv') # Choose columns including year, month, day, prefecture (region), and cumulative positive cases d1 <- d[, c(1, 2, 3, 5, 6)] # The data from 2021-12-31 is to be used d2 <- d1[33136:nrow(d1), ] # Long to Wide d3 <- tidyr::pivot_wider(d2, id_cols = NULL, names_from = prefectureNameE, values_from = testedPositive) d3 <- as.data.frame(d3) # Convert from cumulative number to daily number diff_d3 <- diff(as.matrix(d3[, -c(1, 2, 3)])) df <- cbind(d3[2:nrow(d3), c(1, 2, 3)], diff_d3)
{CausalImpact}と{TSclust}をインポートし、さらに東洋経済のコロナ分析ダッシュボードが提供しているCSVファイルを読み込みます。元データセットはLong形式なので、Wide形式に直します。また元データセットは陽性者数の累積値なので、差分を取って日次の新規陽性者数に直します。最終的に2022年1月1日以降の都道府県別の時系列データのみを残しています。
### Normalize function, [0, 1] ### nrm <- function(d){ mx <- max(d) mn <- min(d) out <- (d - mn) / (mx - mn) return(out) }
### Normalize the dataset ### tmp <- apply(df[, -c(1:3)], 2, nrm) df_nrm <- df df_nrm[, -c(1:3)] <- tmp
新規陽性者数データを[0, 1]の区間に正規化しています。もっと綺麗な方法があったはずなんですが、一旦これで。
### Choose regions where Manbou was declared on 2022-01-27 and ones without Manbou df_4th <- df_nrm[, c(15, 48, 11, 17, 42, 18, 29, 41, 25, 36, 16, 40, 34, 10, 37, 33, 21, 19, 27, 5, 46, 9, 50, 39, 31, 45, 43, 8)]

元のレポートに1/27にまん防を実施した地域としなかった地域のまとめが出ているので、これを参考にして当該地域だけを抜き出してきます。
### In order to satisfy the parallel trend assumption, choose regions with similar trend (during pre-period) by time-series clustering df_4th_pre <- df_4th[1:26, ] distance <- diss(df_4th_pre, 'DTWARP') h <- hclust(distance) plot(h, hang = -1)
### Just for simplicity, arbitrarily cut them into 5 clusters clusters <- cutree(h, 5) print(clusters) #R> Hokkaido Yamagata Fukushima Ibaraki Tochigi Ishikawa Nagano Shizuoka #R> 1 2 2 1 1 1 3 3 #R> Kyoto Osaka Hyogo Shimane Okayama Fukuoka Saga Oita #R> 3 3 1 4 1 1 1 1 #R> Kagoshima Iwate Miyagi Akita Toyama Fukui Yamanashi Shiga #R> 1 2 2 2 2 2 1 1 #R> Nara Tottori Tokushima Ehime #R> 1 1 2 5 table(clusters) #R> clusters #R> 1 2 3 4 5 #R> 14 8 4 1 1
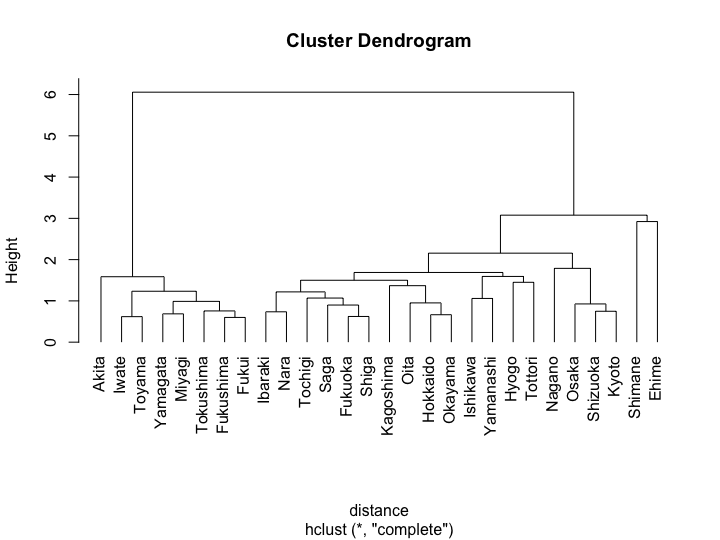
{TSclust}でpre期間に当たる1/1-1/26分のデータに対する時系列クラスタリングを実施します。クラスタ1が最も多いので、これをコホートにしたいと考えました。
### Check the clusters by plotting ### par(mfrow = c(1, 3)) # Only 1, 2, 3 clusters were chosen because 4 & 5 cluster include a single region for (i in 1:3){ cl_mean <- rowMeans(df_4th_pre[which(clusters == i), ]) cl_sd <- apply(df_4th_pre[which(clusters == i), ], 1, sd) matplot(cbind(cl_mean, cl_mean + cl_sd, cl_mean - cl_sd), type = 'l', lty = 1, ylab = '') title(main = paste("Cluster ", i)) } par(mfrow = c(1, 1))

念のため、各クラスタがどのような時系列を描くかをプロットしてみます。クラスタ4・5は1地域しかないので除外してあります。とりあえずクラスタ1で問題はなさそうです。
### Choose regions with similar trends, cluster 1 ### df_cl <- df_4th[, which(clusters == 1)] names(df_cl) #R> [1] "Hokkaido" "Ibaraki" "Tochigi" "Ishikawa" "Hyogo" "Okayama" #R> [7] "Fukuoka" "Saga" "Oita" "Kagoshima" "Yamanashi" "Shiga" #R> [13] "Nara" "Tottori"
実際にクラスタ1を抜き出します。Yamanashiまでが介入群、Shigaからが対照群です*5。
### Split the regions into test and control groups, and run CausalImpact ### # Split the regions test_cl <- df_cl[, 1:11] ctrl_cl <- df_cl[, 12:14] # Set pre & post period pre.period <- c(1L, 26L) post.period <- c(27L, nrow(df)) # Preprocess for BSTS modeling y <- rowMeans(test_cl) post.period.response <- y[post.period[1] : post.period[2]] y[post.period[1] : post.period[2]] <- NA # Run BSTS ss <- AddLocalLinearTrend(list(), y) ss <- AddSeasonal(ss, y, nseasons = 7) bsts.model <- bsts(y ~ as.matrix(ctrl_cl), ss, niter = 1000) # Run CausalImpact with the BSTS model ci <- CausalImpact(bsts.model = bsts.model, post.period.response = post.period.response) # Show the result print(ci) #R> Posterior inference {CausalImpact} #R> #R> Average Cumulative #R> Actual 0.6 28.2 #R> Prediction (s.d.) 0.79 (0.15) 37.10 (7.16) #R> 95% CI [0.55, 1.2] [26.05, 54.1] #R> #R> Absolute effect (s.d.) -0.19 (0.15) -8.94 (7.16) #R> 95% CI [-0.55, 0.045] [-25.90, 2.107] #R> #R> Relative effect (s.d.) -24% (19%) -24% (19%) #R> 95% CI [-70%, 5.7%] [-70%, 5.7%] #R> #R> Posterior tail-area probability p: 0.05408 #R> Posterior prob. of a causal effect: 95% #R> plot(ci)

後は改めて整形後のデータを介入群・対照群にsplitし、CausalImpactにかけるだけです。図中の黒い実線が「実際の介入群の陽性者数」、黒い破線が「反実仮想(介入群で仮にまん防が実施されなかった場合)の陽性者数」、青い網掛け部はベイズ確信区間です。図の1段目はフィッティング結果、2段目は2群の差分、3段目はその差分の累積値を示しています。
ここでは、確実に季節調整&ローカル線形トレンドをBSTSモデルに盛り込むために、先にBSTSでモデルを推定してから、そのモデルをCausalImpactに入れるという手順を取っています。やり方は上記のvignettesに書かれたものを踏襲しています。最終的に得られる因果効果の事後確率は、BSTSモデル推定時の乱数シードに依存するため多少変動します。見ている範囲では大体88-96%ぐらいといった感じです。
ということで、今回notebookで回した分析で得られた結果をもって「まん防には陽性者数を減らす因果効果があった」と結論づけて良いかどうかは悩ましいところです。ベイズでやっているので頻度論的な「p < 0.05をギリギリ満たしていないから云々」という言い方はできない*6のですが、その何とも面倒な曖昧さが「BSTSの乱数シードによってばらつく事後確率が88-96%」というところに表れているのかな、というのが個人的な感想です。「確かに介入群の方がじわじわ下がっているように見えるけど、その確度はどうなのかな」ぐらいでしょうか。
以上のアプローチは、実は現職で僕がリードしているサブチームでやっている広告マーケティング施策の効果検証実験のやり方とほぼ全く同じですが、僕らの場合は「必ずコホートを切った後に実際に介入(実験)を行う」ように厳格に運用しています。実施例の中には公開事例になっているものもありますので、興味があればご一読ください*7。
考察など
先述した現職のサブチームのポリシーの一つに、「観察データ(非実験データ)に対して因果推論するべきではない」というものがあります。理由は簡単で、明確な実験介入条件のコントロールが行われていないデータというのはどこまでいっても恣意的な解釈が可能になってしまったり、あるいは解釈の幅が果てしなく広くなってしまったりするため、再現性高く合理的な意思決定をする根拠とするには向かないからです。
以前集中的に因果推論の勉強をした時も同じことを思ったもので、その後自分の仕事で同様のシチュエーションに陥るたびに「観察データだけで因果推論なんてやるものではない」という思いを深めていき、その結果として実は上記のポリシーを定めています。そういう観点からすると、やはり今回のケースで因果推論をやるのは難しかったのではないかというのが偽らざる感想です。
(※これはあくまでも広告・マーケティング分析業務に携わる自部署での経験に基づいた僕個人の感想であり、例えば世界銀行などで行われるような大規模な政策評価のように「そもそも厳密に統制された実験を行うこと自体が難しく因果推論でしかアプローチできない」領域の話は想定していない点にご注意ください)
また他所では言及したんですが、個人的には自分でやったことがないながらも回帰分断デザイン(RDD)でやっても良かったのでは、という感想があります。もっともあまりRDDには詳しくないので深追いはしませんが、DIDのような時系列分析固有の仮定が幾つも存在するものよりはやりやすいんじゃないかという印象を勝手ながら持っています。
そしてもう一つ。以前Quoraでも書いたんですが、原理的にCOVID-19の感染拡大に関するデータ分析全般がそもそも非常に困難を極めるものです。それを鑑みるに、今後も似たようなコロナ対策の評価分析が行われては、その妥当性を巡って論議を呼ぶというケースが続出するのではないかと思っています。
これに関しては、もう現行の統計的学習手法によるアプローチで分析するのは殆ど不可能で、改めて感染症数理疫学の枠組みの中でこれに特化した分析体系を研究して打ち立てていくしかないのかな、と思う次第です。ただ、COVID-19パンデミック以前はそこへの社会全体の関心が失われていて研究コミュニティも縮小の一途を辿っていたという話を聞くので、今これから改めてその研究コミュニティを再拡大して研究テーマとして盛り上げていこうとなると、だいぶ気の長い話になりそうです。
*1:https://twitter.com/ShuheiKitamuraJ/status/1503913713803284480
*2:SUTVA条件と呼ぶようですね
*3:厳密なSCMを適用していない、の意
*4:実はColabのRカーネルは前々から会社で使っているので完全に初めてではない
*5:最初にデータを入れる際に介入群アルファベット順&対照群アルファベット順で入れたので、前者の最後がYamanashiということになる
*6:というかしたくない
*7:例えば https://www.thinkwithgoogle.com/intl/ja-jp/marketing-strategies/data-and-measurement/shopping-title-optimization/ など