
すっかり生成AI全盛時代という感のある昨今ですが、僕が主戦場とする広告・マーケティング分析の世界にも続々と生成AIを活用した自動化やvibe codingに依拠した「民主化」の流れがやってきており、もうあと数年もしたら「ヒトのアナリストは不要」と言われるのも時間の問題だろう、と思われる有様です。
なのですが、そういう時代だからこそ自分のような老害としてはどうしても声高に叫ばずにはいられない、普遍的な概念があります。それが「汎化性能」と「再現性」です。どちらもこのブログでは何年も前から言い古されてきた概念ではありますが、生成AIによる「民主化」が進む昨今のデータ分析界隈においては何故かあまり重視されていないという印象があります。
そこで、今回の記事ではほぼ単なるポエムになってしまうのを承知の上で、今だからこそ再認識されるべき「汎化性能」と「再現性」の重要性について改めて論じてみようと思います。なお、以下の議論では回帰分析や機械学習を初めとする統計的学習モデルを念頭に置いていますが、本質的にはデータ分析という営為全般に言える話だと考えています。
- 「汎化性能」に優れた分析は、未知の状況でも高い予測精度を出せる
- 「再現性」ある分析は誰がいつ回しても同じ結果になるので、科学的根拠として信頼される
- 「未来を知りたい」がためのデータ分析には「汎化性能」と「再現性」が重要
- コメントなど
「汎化性能」に優れた分析は、未知の状況でも高い予測精度を出せる
これについてはむしろ「過学習(過剰適合)」の話題としてこのブログでは何度も取り上げているので、そちらの方が分かりやすいでしょう。即ち、データ分析が真のシグナルだけでなくノイズにまでぴったりと追従してしまった結果として、未知データへの当てはまりが却って悪化してしまうという現象です。分かりやすい喩えで言えば「過去問ばかりただ丸暗記しただけの受験生」のようなもので、過去問は何を出題されても完璧に回答を書ける一方で、本番の入試で過去問と似てはいても多少異なる問題が出題されたら全く解けない……というシチュエーションを想像してもらえれば分かりやすいかと。これは統計的学習モデルでは広く知られる普遍的な問題ですが、見ようによっては「PDCAサイクル」のようなビジネス上の枠組みにも当てはまり得るとも言えます。
そのような過学習を避けて真のシグナルをどれくらい適切に予測できるかという度合いを表すのが「汎化性能」という概念で、一般には「交差検証」の精度によって測られます。つまり、学習データとは別に検証用データを分けておき、学習データに対する統計的学習モデルが検証用データに対しても的確に機能するかどうかを確かめ、都度ハイパーパラメータなどを調整していく、ということです。上記の受験生の喩えで言えば、「定期的に模試を受けてその成績を参考にして勉強の仕方を調整する」といったところでしょうか。そして、その定義からも明らかなように、汎化性能に優れた統計的学習モデルは(未来の)未知の状況であっても高い精度が出せるものと期待されます。古来から汎化性能が重視されてきた所以です。
「再現性」ある分析は誰がいつ回しても同じ結果になるので、科学的根拠として信頼される
汎化性能が「データ分析の『予測精度』の信頼性」を表すものだとすれば、「データ分析の『枠組み』の信頼性」を表す概念に当たるのが「再現性」だと言えるかと思います。これも以前の記事で論じたことがありますが、例えば「狙った分析結果が出るようにデータセットを選別する」*1「分析結果が都合の良いものになるようにp値などの評価基準をいじる」*2「データ分析して出てきた分析結果を見てから検証するつもりだった仮説を挿げ替える」*3といったQRPs (Questionable Research Practices)は様々な場面で行われがちです。しかし、そういった「操作」はそもそも分析結果の客観性を著しく損なう上に、例えば他の誰かがそれらの操作がされたことを知らずに同じ分析結果を再現しようとしても再現しないという事態に陥りがちで、分析そのものの信頼性が失われかねません。
そのような事態を出来る限り抑制するために、例えば「データセット取得&取捨選択プロセスを明示的に固定する」「分析の評価基準は記録した上で事前に明示的に固定する」「検証する仮説や分析手順は事前に明示的に定めておく」さらには「実験するたびに仮説を替えるならそのプロセスを記録して明示する」*4といった再現性を担保するための取り組みがなされるべきだと、近年では指摘されるようになっています。
「未来を知りたい」がためのデータ分析には「汎化性能」と「再現性」が重要
通り一遍の「汎化性能」と「再現性」についての説明を並べてしまいましたが、それらが重要となるのはこれまた当たり前のことながら「未来を知りたい」がためにデータ分析をする(統計的学習モデルを推定する)時なんですよね。それは、ズバリ「未来の予測値を得たい」場合では必須ですし、もう少し間接的に「分析結果に基づいてアクションを起こしたい」という場合でもhuman in the loopの予測だと見做せばやはり同様に必須だと思われます。
ただ、最近は生成AIにvibe codingもしくはもっと包括的にデータ分析プロセスを担わせることが多く、プロンプトの与え方やエージェントの構築の仕方によっては、例えば「生成AIが提案してこなかったから」とか「そもそもその概念自体を知らなかったから」という理由で、汎化性能も再現性も見落とされたまま、過学習された統計的学習モデルを用いた分析が進行していくこともままあるようです。その結果、ビジネスなり研究なりに悪影響が出てしまうということにでもなろうものなら、目も当てられないことでしょう。いかな今時は生成AIで何でも出来るご時世だといえども、汎化性能と再現性にはユーザーたるヒトの側が意識的に注意を払うべきだと考えています。
これは僕自身が目にしたケースですが、マーケティング分析のコードを生成AIに書かせてみた際に、「出来上がりました」「いやこれだと要件を満たさないから直せ」というやり取りを何度も何度も繰り返しているうちに、最終的に出来上がったスクリプトから交差検証のパートがそっくりそのまま欠落してしまう……なんてことも現行の生成AIでは起こり得るんですよね*5。そこで自ら気付いて「交差検証のコードを追加しろ」と指示し直せれば大丈夫なのですが、もしそれを知らない人がやっていたら見落としたまま分析が進むということはあり得る話だと思ってます。
ちなみに、少しニュアンスのずれた話になりますが、近年では統計的因果推論の重要性がクローズアップされるようになり、時には「バイアスの調整さえ出来ていれば汎化性能は度外視して良い」という主張もあるようです。実際に悉皆的にデータを取得することが多い疫学分野などではそう言われるのを聞いたことがありますし*6、それこそ多重共線性を伴う回帰分析のように「バイアスが大きいにもかかわらず汎化性能は良好」というケースもあり得るので、それ自体は筋の通った話です。
とは言え、因果推論を駆使した分析であってもそれが「未来を知りたいがための分析」であるならば、少なくとも再現性を担保することは意識されるべきだと思いますし、程度問題ながら汎化性能にも注意した方が良いと思う次第です。「あれこれとりあえず手当たり次第交絡因子を弄ってみたらそれっぽい結果になったのでめでたしめでたし」で終わらせず、その先も普遍的にある程度等価な結果が得られるような枠組みをきちんと考えるべきだ、ということですね。
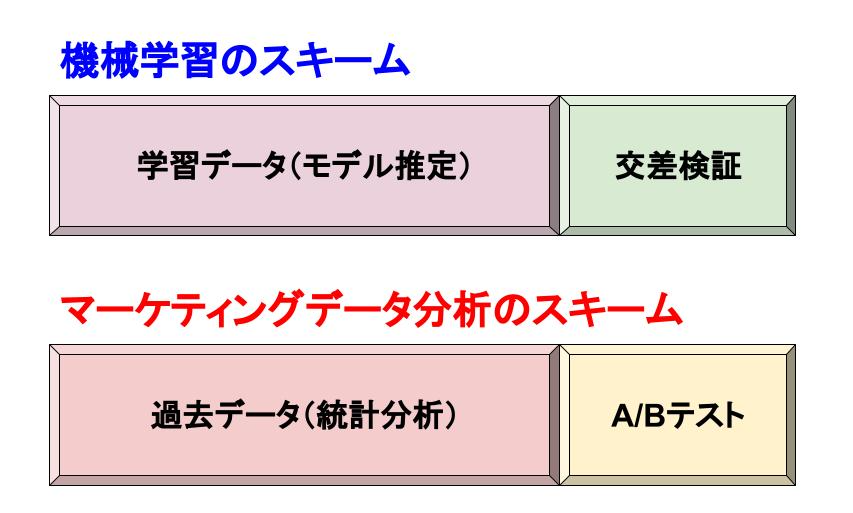
そして、最後に強調しておきたいのが「過去データに対する分析だけに閉じようとしないこと」。基本的に統計的学習モデルはretrospectiveな分析であり、どのように完璧に交差検証などを行って汎化性能を担保できたとしても、その「未来」への適用には原理的な限界があります。そこで、個人的には環境と事情が許す限り*7は「事後の検証実験」を行ってダメ押しするということを強く推奨しています。これにより汎化性能をチェックできるのみならず、再現性の多寡をもチェックできるわけで、可能であるならば必ず行われて然るべきだと考えています。
コメントなど
何でこんなポエムを書こうと思ったかというと、僕の周囲でも今までデータ分析をやってこなかった人たちが「生成AIにやらせれば自分でも出来るから」という理由で気軽に始めるケースが散見されるから、なのでした。実は同様の問題は過去何度か繰り返された第n次データサイエンティストブームでも散見されたものですが*8、生成AI時代の到来でその規模が比べ物にならないくらい大きくなったので、改めて警鐘を鳴らしておこうと思った次第です。
なお余談ですが、トップ画像はこのブログの記事多数をある程度選定して読み込ませたNotebookLMをコンテクストとして、Nano Bananaに生成させたものです。正解のないクリエイティブな課題にこそ、生成AIは強いんだなぁとつくづく思います(笑)。