
(Image by Pixabay)
"Top 10 Statistics Mistakes Made by Data Scientists"という刺激的なタイトルの記事が出ているのをKDnuggets経由で知りました。「データサイエンティストがやらかしがちな統計学的な誤りトップ10」ということで、いかにもなあるある事例が色々載っていて面白いです。
ということで、今回はこの記事を全訳にならない範囲で抄訳して、その内容を吟味してみようと思います(直訳しても意味が取りづらい箇所が多かったためかなりの部分を抄訳ながら意訳しています:こういう訳の方が良いなどのコメントあれば是非お寄せください)。言わずもがなですが、こういう海外記事紹介をやる時はネタ切れということです、悪しからず。。。
- 元記事の内容
- 1. Not fully understand objective function(目的関数が何かをきちんと理解していない)
- 2. Not have a hypothesis why something should work(何かがうまくいく理由を説明する仮説を持っていない)
- 3. Not looking at the data before interpreting results(結果を解釈する前にそもそもデータそのものを見ていない)
- 4. Not having a naive baseline model(適切なベースラインモデルを置かない)
- 5. Incorrect out-sample testing(正しくない非サンプルテスト=不適切なCV)
- 6. Incorrect out-sample testing: applying preprocessing to full dataset(不適切なCV:前処理をsplitする前に一括してやってしまう)
- 7. Incorrect out-sample testing: cross-sectional data & panel data(不適切なCV:クロスセクションデータとパネル・時系列データとで同じことをやってしまう)
- 8. Not considering which data is available at point of decision(いよいよモデルを導入する際にどのデータが使えるかを考慮していない)
- 9. Subtle Overtraining(微妙な過学習)
- 10. "need more data" fallacy(「もっとデータが必要」という誤った思い込み)
- 感想など
元記事の内容
とりあえず、まずは元記事の内容をザッと要点をまとめていきます。対訳というよりは、原文が言いたかったであろうことを僕の独断で補完していますので、原文が気になる方は上記リンク先からお読みになることをお薦めします。なお、文中の図は全てGitHubに上がっている元記事の画像リンクを直接貼って載せています。
1. Not fully understand objective function(目的関数が何かをきちんと理解していない)
ここでは、何かモデルを構築する際に「何を目標(=KPI)にするべきか?」というのを分かっていないと意味のない仕事をやることになる、と警鐘を鳴らしています。あるあるなのが、モデルの「精度」という意味では大して良くなくても、ビジネス上の指標の改善には大きく貢献するようなモデルをダメだと言って捨ててしまっているというケース。そういう拙い帰結を避けるためにも「目的」にこだわれ、ビジネス上の指標を改善したい場合はそれを適切な数学的・統計学的な目的関数に変換しろ、というお話です。
2. Not have a hypothesis why something should work(何かがうまくいく理由を説明する仮説を持っていない)
一言で書くと「データもまともに見ず、どういうデータなら目の前にあるデータによく当てはまりそうか、というイメージを特に何も持たないまま闇雲にモデリングしようとする」ということ。そうなると、適当に複数のモデルをデータに対して適当に当てはめてみて、適当に一番精度が良かったものだけを適当に選んで適当に使うという、適当ずくめになりかねないわけです。
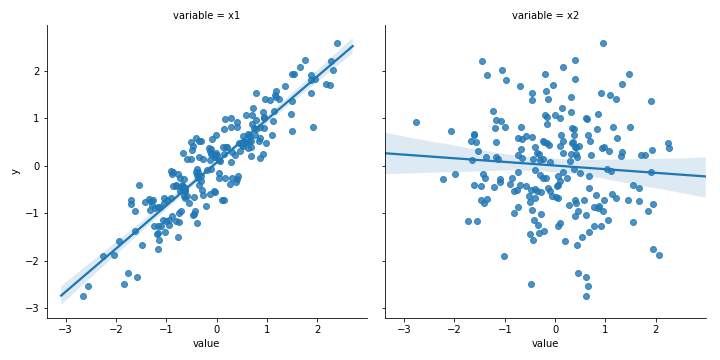
この図の左の例では散布図を描けば一瞬で線形モデルで済むことが分かるし、右の例では線形モデルではダメだということが一瞬で分かるわけですが、それすらしないのは愚かしい、と。
3. Not looking at the data before interpreting results(結果を解釈する前にそもそもデータそのものを見ていない)
ここで念頭に置かれているのは外れ値(outlier)や不均衡データへの対応。これも結局データそのものを見ていなければ分からないわけです。
同じ図の繰り返しですが、左の例では外れ値を入れただけで回帰係数が0.906から-0.375に飛んでしまいます。とにかくまずデータそのものをきちんと見ろ!ということですね。
4. Not having a naive baseline model(適切なベースラインモデルを置かない)
実験科学をやっていた人間ならポジコンとかネガコンとかピンと来るかと思うんですが、モデリングを行って予測を行いたいデータサイエンティストも同様に適切なベースラインを置くべきである、と言っています。ここでは時系列データモデリングを例に挙げて、線形回帰でCV MSEが云々、ランダムフォレストでCV MSEが云々としたくなるところで、そもそも1期前のデータで自己回帰したらどうなるか考えてみたか?というツッコミを入れています。
5. Incorrect out-sample testing(正しくない非サンプルテスト=不適切なCV)
R&Dとして作られたモデルは素晴らしかったが、いざ本番環境に突っ込んでみたら全く使い物にならなかった。。。みたいな話は最先端の〇〇Netが猛威を振るう現代ですら良くあるお話。学習データ(train/dev)内でCVするだけで済ませるのではなく、きちんと学習データ(train/dev)の外側のテストデータ(test or private)を使って性能検証しろ、CVでパフォーマンスが良くてももしかしたら単なるoverfittingかもしれないぞ、ということです。ここで上がっている例は、ランダムフォレストのCV MSEが0.04、線形回帰のCV MSEが0.183だったとして、これを新規テストデータに当てはめてみたらRFのMSEが0.261、線形回帰のMSEが0.187だったとしたら、どちらを使うか?と聞いています。
6. Incorrect out-sample testing: applying preprocessing to full dataset(不適切なCV:前処理をsplitする前に一括してやってしまう)
シンプルに言えば、きちんとtrain/devからtestへのleakageが起きないように注意しろというお話です。その一例として、train/dev vs. testとで分ける前に一括して前処理を行ってしまうというケースを挙げています。本来ならtrain/dev vs. testとで分けた「後に」前処理しなければいけないのに、「前に」謝って前処理してしまうことで何かしらのleakageが起きるかもしれないということです。
7. Incorrect out-sample testing: cross-sectional data & panel data(不適切なCV:クロスセクションデータとパネル・時系列データとで同じことをやってしまう)
これはちょっと前にあるところで大きな議論を呼んだ話で、時系列データに対する交差検証をクロルセクションデータと同様にrandom splitでやってしまうケースがままある、というお話です。当然ながら、時系列データは単位根過程・トレンド・季節調整など非線形成分を含むことが多く、ランダムに切り出しても前後のサンプル同士含めて自己相関(系列相関)の影響を強く受けやすいので、random splitでCVするのはご法度です。
このブログでも以前取り上げましたが、時系列データに対するCVは原則として「過去から未来方向に向かってのみ」行います。
8. Not considering which data is available at point of decision(いよいよモデルを導入する際にどのデータが使えるかを考慮していない)
ここで突然グッと実務的な話が出てきます。データ分析業界あるあるネタとして「機械学習モデルを作った時と同じような傾向のデータが肝心の機械学習システム導入時に得られない」というのがありますが、まさにその話です。対処法として「とにかく新規テストデータを得ては検証を繰り返す」ということが提唱されています。
9. Subtle Overtraining(微妙な過学習)
これは正直言って何を言いたいのかちょっと分かりづらかったです。データが増えれば過学習が進むというのはまぁその通りだと思うんですが、「データが増えるにつれて過学習が進んでしまった時にどうすれば良いか」は結構難しいテーマだと思うんですよね。。。多分その「程度」をどう測るか?が重要だということなのかなと。データが増えた結果CV MSEが2倍になってしまったらどうしたら良いか?いやそれはそのMSEを許容できるかどうかの方が重要だと思うんですが。
追記(2019年6月18日)
データサイエンティストがやらかしがちな過ちトップ10(海外記事紹介) - 六本木で働くデータサイエンティストのブログ9 は「一つのデータセットだけを一生懸命いじり回すな」って話では・・・?
2019/06/17 20:59
確かにそう読み取れるなと思いました。ご指摘有難うございますm(_ _)m
10. "need more data" fallacy(「もっとデータが必要」という誤った思い込み)
標本抽出にこだわる古典的な統計学に詳しい人から見れば実は当たり前な話ではありますが、「直感に反して」データ分析というのは多過ぎるよりは少数で良いのできちんと(実際には見えない)母集団を適切に代表するサンプルがあれば良いというものだったりします。もちろん、データが少なければそれだけ人の目で見て把握することも容易であり、「センス」も発揮しやすくなります。が、データサイエンティストというのは往々にして「もっとデータが必要」と言ってしまいがちである、と。
なればこそ、「多々ますます弁ず」という姿勢は排さなければならない。少数の適切に母集団を代表するサンプルが得られるようなサンプリングを行う限りは、得られたデータを分析した結果から導いたアクションがうまくいかなかった時に考えるべきことは「もっとデータを増やす」ではなく、「もっとアプローチを適切なものに変える」であるべきだ、と言っています。
感想など
一貫して過学習のことを"overfitting"ではなく"overtraining"と書いたり、train / dev / test (private)ではなくin-sample vs. out-sampleと書くなど、ちょっと用語の使い方が違う感じのするテキストだったので色々と読んでいて戸惑うことのある記事でした。。。
個人的な意見を書くと、この記事が主にビジネス実務における機械学習(統計)モデリングの管理運用の仕方について何か物申そうとしているのだとすれば、やはりビジネス実務において何が重要かということを第一義に置くべきだと思うのです。例えば「説明」に重きを置きたいのか、それとも「予測」に重きを置きたいのか、などなど。
あとは、一般的なモデリングに際しての注意事項を守ることが肝要かなと。特に時系列データのモデリングはそこら中に地雷が埋まっている地雷原みたいなものなので、割とシンプルな約束事しかないとはいえ、ある程度意識的に落とし穴にハマらないよう気を付けるべきかなと思いました。