前回の記事でも触れましたが、ここ最近いわゆる需要予測系のマーケティングモデル(特にMedia Mix Modeling: MMM)を手掛けることが増えています。
この手の統計モデルは経済学で言うところの「実証分析」に当たると思われ、一般には「予測」よりも「説明」に用いられることが多いです。より具体的に言えば、回帰モデルを推定した上で個々の変数のパラメータを比較して、例えば「デジタル動画広告をもっと強化した方が良い」というようなマーケティング上の示唆を得る、というような目的で用いられます。
ところが、これまた前回の記事で触れた通りでそれらのモデルに基づく「説明」には、どうしても「羅生門効果」の問題が生じ得ます。即ち、同じデータセットに対して似たような性能を示す回帰モデルが複数並び立った場合、どのモデルの「説明」を優先すべきか?という問題です。これは純粋に統計的学習分野の問題として捉えればある程度シンプルなアプローチに帰着させられるのではないかと思うのですが、実際のビジネスシーンにおけるニーズを考えると意外と複雑な問題になってしまうという印象があります。
ということで、今現在僕自身が「マーケティングモデルの羅生門効果」について抱えている課題意識をもとに、考えたことや調べてみたことをこの記事では簡単にまとめてみようと思います。よって、ここに挙がった課題について「これこれの解決策があるよ」という案がおありの方は、是非コメントなりで僕にお知らせいただけると大変に有難いです。
また久しぶりに論文を読む回でもあるので、明らかにここの読み方や理解が間違っているとか前提がおかしいとか、お気付きの点がありましたら同様にコメントなりでご指摘くださいm(_ _)m
現実のビジネスシーンでありがちなこと
需要予測系のマーケティングモデルというと、一般には割とハイレベル(それこそ役員会など)な意思決定の材料として用いられることが多いのですが、得てしてそういうレベルになると「統計学や機械学習の素養が殆どないステークホルダー」ばかりになりがちなもの。そうすると、「モデルそのものの妥当性」よりも「モデルの解釈のしやすさ」とか、場合によっては「モデルから解釈される結果が実際のビジネスアクションに繋げやすいかどうか」によって、モデル選択が優先されることがあります。
そうすると何が起こるかというと、「変数をある程度絞り込んだ汎化性能の高いモデル」よりも「あれもこれもと変数を沢山突っ込んで過学習がひどくなった汎化性能の低いモデル」の方が「個別の細かいビジネスアクションに落とし込みやすい」ということで選ばれてしまうことがあるんですね。
そうすると、この記事で挙げた7つのデータサイエンスの失敗例の2つ目のような事態に陥りかねません。そのような事態を避けるために、モデリングを任される側としては事前にある程度しっかりとしたcriteriaを設けて、「やばいモデル」が選ばれないようにするという予防線を張る必要があると、個人的にはいつも考えています。
一般的な交差検証ベースのアプローチ
では、「やばいモデル」が選ばれないようにするにはどうするべきでしょうか。これは統計的学習モデルを用いる以上当たり前の話なんですが、普通は交差検証をかけて最も汎化性能に優れたモデルを選択し、そのモデルの「説明」を採用するというアプローチを取ります。
ちょっと簡単な例を挙げてみましょう。例えば、ある3つの説明変数で表現可能な線形回帰モデルを考えます。目的変数がそもそもその3つの説明変数とそれぞれの重みづけパラメータ[1.0, -1.5, 1.0]から成るモデルの出力に正規分布に従う適当な乱数を加えただけのものなので、ある意味これが「真のモデル」です。

学習データへのRMSEは3.0前後、交差検証データへのRMSEは3.2前後です。このモデルの3つの変数に対して推定されたパラメータ(偏回帰係数)を見ると、こうなります。目的変数を生成した時に設定した真のパラメータと大体似たような値になっています*1。

これに対して、適当な(つまりデタラメな)乱数からなる新たな説明変数を6つ追加します。これらは全てただのホワイトノイズなので、素朴に考えればモデルには寄与しないように思われるのですが、実際には以下のようになります。

今度は学習データへのRMSEはほぼ0であるのに対して、交差検証データへのRMSEは13.5前後に跳ね上がります。このモデルの3+6つの変数に対して推定されたパラメータを見ると、こうなります。

ただのホワイトノイズでしかない後発の6つの説明変数に対して過大なパラメータが推定されているだけでなく、元々の真のモデルに含まれていた3つの説明変数に対するパラメータ推定値も真の値から大幅にかけ離れていることが分かります*2。
ということで、この場合1つ目と2つ目のモデルのどちらを選ぶべきか?と言われたら、誰でも普通は1つ目を選ぶはずです。そしてその根拠として、交差検証誤差*3がより小さいから、という理由を挙げることになるでしょう。
ここまではありふれたモデル選択の話題なのですが、実際のマーケティングモデル運用の場面では結構面倒な事態が起こります。良くあるのが「元々多数の説明変数があって、ドメイン知識やその他の基準*4に基づいて加算してマージし、n個の説明変数にまとめるという方針を取った」ところ、「変数同士のまとめ方は異なるが同じn個の説明変数から成るモデルが複数出来上がり、しかもその異なるモデル同士で交差検証誤差がほぼ同じ」というパターンです。
この場合、「使っている説明変数は異なるがモデルの特徴量次元は同じで尚且つ汎化性能もほぼ同等」ということになり、文字通りの「羅生門効果」を生じさせているわけです。これでは交差検証しただけではモデル選択のしようがありません。では、どうしたら良いのでしょうか?
機械学習そしてXAIの文脈から見た、解決策「になりそうな」アプローチ
こういう「羅生門効果」を解決する方法論はないものかなと色々ググりながら調べていたら、ある一つの研究に行き当たりました。Rudinの"Rashomon curves & volumes"です。
1つ目はPFN社さんのKDD2019参加報告記事で紹介されていたもので、しましま先生こと神嶌先生から「論文になったものがあるよ」と教えていただいたのが2つ目です。
なお、この内容はKDD2019のRudinによるKeynote talkであり、そのrecording全体とスライドのいずれもYouTubeに上がっています。論文本体は割とガッチガチの理論パートが満載で数学が大の苦手な我が身としてはを論文を読むよりはスライドを読む方が格段に理解しやすいです。
またTowards Data Scienceにも羅生門効果に触れた記事があり、端的な説明で分かりやすいです。ザッと結論だけ知りたいという方はこちらだけ読んだ方が早いかもしれません。
で、これらの論文や資料を読んだり、在ロンドンのtmaeharaさんから色々ご解説をいただいたりして、大枠を理解した印象を我流で極めて大雑把にまとめると「データセットごとに様々な『可能なモデル空間』が存在し得て、これの中の『大体同じくらいのベストの予測性能を発揮できるモデル空間』(Rashomon set)との比率(Rashomon ratio)が大きいデータセットほど、『ベストの性能かつよりシンプルなモデル』を選べる可能性が高い」という話のようです。

その分布のようなものを表すために、横軸に経験的リスク*5&縦軸に対数Rashomon ratio*6を取り、モデルの複雑さを高めながら描いていったのがRashomon curveとのことです。上の図は元論文のFigure 11から取ってきたもので、有名な機械学習データセットたちに対してそれぞれにRashomon curveを描いたものと説明されています。
そうするとある意味当然ですが、例えばただの単回帰から順々にモデルの複雑性を上げていくことを考えると、経験的リスクが十分に下がってくるまではしばらく横ばい(Γ字の横棒)に推移し、ある程度経験リスクが十分に下がるとそれ以上は下がらなくなると同時に、モデルの複雑性が上がるにつれてRashomon ratioが上がっていく(Γ字の縦棒)という動き方になることが予想されます。そして、横棒と縦棒の長さはデータセットの性質に依存するということのようです。
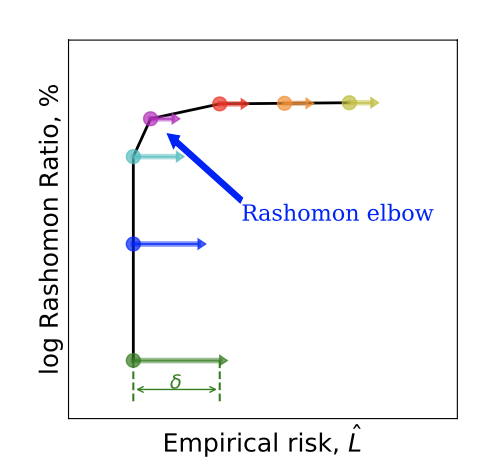
元論文では上図(Figure 9)にあるように、このRashomon curveが途中でΓの字のようにググッと曲がるところを"Rashomon elbow"と呼び、ここを「バランスが最も良いポイント=ベストモデル」だとしています。

ちなみに、元論文には載っていなくてKeynoteのスライドには載っているのが上の図で、Rudinはこんな感じの「Rashomon elbowにロジスティック回帰などの比較的シンプルなモデルが来る」「そのずっと下の方に煩雑なNNなどが来る」というケースを想定しているようだ、ということが分かります。
……というように僕は読み取ったのですが、一つ気になったのが「これならモデルそのものの複雑度に対して最適点を求めることは出来そうだが、特徴次元(列数)が等しい場合の最適な変数選択を決めることが出来るんだろうか」という点です。tmaeharaさんからは「結局最適なモデルを一意に決められないから難しいのでは」という趣旨のコメントをいただいていて、僕もど素人ながら論文やスライドを読んだ限りではそういう印象を持ちました。
それから、これは僕個人にとっての切実な課題なんですが「ある特定のデータセットに対して具体的にRashomon ratioを算出する実装の仕方」が元論文を読んでも良く分かりませんでした(5, 6節で説明されているのは分かりましたが……)。多分こうだろうという感じのやり方は載っている*7んですが、これを例えばベイズ構造時系列モデルでやる場合はどうするのか皆目見当もつかないです。どなたか賢い方が実装を公開してくださるのを気長に待ちたいと思います(完全他力本願)。