
この記事は、別にちょっとした理由があってR版Kerasで自前のDNNモデルをfine-tuningしたいと思ったので、調べて得られた知識をただまとめただけの備忘録です。既にやり方をご存知の方や、興味がないという方はお読みにならなくても大丈夫です。ただし「このやり方間違ってるぞ」「その理解は誤っている」的なご指摘は大歓迎どころか大募集中ですので、コメントなどでご一報ください。
Fine-tuningとは
前々から雰囲気では理解していたんですが*1、雰囲気しか知らないが故に適切なまとめ方が分からないのでこちらのブログ記事から引用させていただくと、
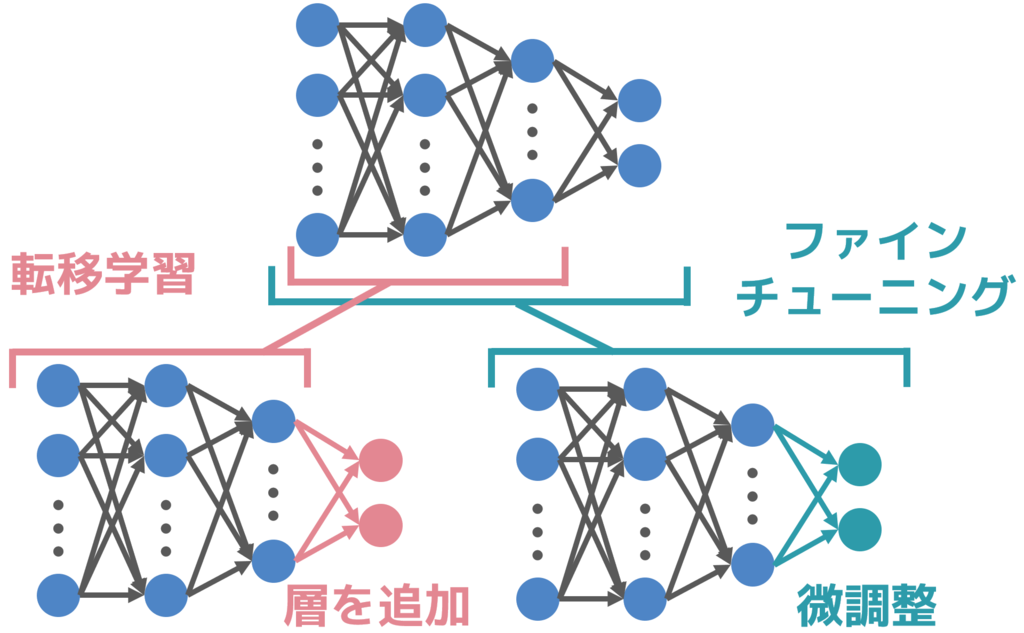
ファインチューニングとは、学習済みモデルの一部もしくはすべての層の重みを微調整する手法です。転移学習では、学習済みモデルの重みを固定して用いますが、ファインチューニングでは学習済みモデルの重みを初期値とし、再度学習によって微調整します。(太字原文ママ)
ということだそうです。実は、自分の中では両者が結構ごっちゃになっていた感があったので、これでようやくすっきりまとまった気がします。TF-Hubでembedding vectorを利用して分類器を学習させるのは転移学習なんですね*2。なお、今回の記事の冒頭に挙げた図はこちらのブログ記事の図を参考に描いたものです。大変に分かりやすかったです、有難うございます。
")
{kind=link}
なお、最新版の推薦図書リストにも挙げている『深層学習』第2版でも確認したところ、僕が雰囲気で理解していた部分が全部綺麗に解説されていて分かりやすかったです*3。特にp.258の記述から引用してまとめると、
目的とするタスクを
、それとは異なるが一定の類似性を持つタスクを
とする。
は量が十分でない一方、
は豊富にあるとする。この時、
- ニューラルネットワーク
を
の学習に活用するのが、いわゆる転移学習
- ニューラルネットワーク
ということになるようです。やはりプロの解説書を手元に置いておくことは重要ですね。
R版Kerasのドキュメントに書いてあること
これは多分オリジナルのPython版とR版とで大きな違いはないだろうと思っていましたが*4、念のために調べてみました。
Freeze and unfreeze weights
Source: R/freeze.RFreeze weights in a model or layer so that they are no longer trainable.
freeze_weights(object, from = NULL, to = NULL, which = NULL) unfreeze_weights(object, from = NULL, to = NULL, which = NULL)Arguments
object
Keras model or layer objectfrom
Layer instance, layer name, or layer index within modelto
Layer instance, layer name, or layer index within modelwhich
layer names, integer positions, layers, logical vector (of length(object$layers)), or a function returning a logical vector.
ということで読んで字の如く、keras::unfreeze_weights()すれば基本的にはfine-tuning出来るようです。つまり、学習済みモデルの重み付けをunfreezeした後で新しいデータでfitし直せばfine-tuning出来る(新たなデータに合わせて重み付けが再学習されて微調整される)ということですね。
Rコードと実験結果
折角なので、前回の記事の内容を踏襲してやってみようと思います。既に見た通り、XORパターン分類課題においてDNNは大サンプルサイズだと非常に綺麗で真の解に近い決定境界を描くのですが、小サンプルサイズだと汎化性能不足でノイズに引っ張られる傾向があります。そこで、大サンプルサイズで学習させたDNNを小サンプルサイズでfine-tuningしたら、綺麗な決定境界を描けるかどうか試してみます。
いつも通りGitHubにRコード自体は上げてあります。以下のような感じでまるっと回せば結果がプロットされるはずです。
# Large dataset d <- read.csv('https://github.com/ozt-ca/tjo.hatenablog.samples/raw/master/r_samples/public_lib/jp/xor_complex_large.txt', header = T, sep = '\t') x_train <- as.matrix(d[, -3]) y_train <- as.matrix(d[, 3]) - 1 library(keras) model <- keras_model_sequential() model %>% layer_dense(units = 5, input_shape = 2) %>% layer_activation(activation = 'relu') %>% layer_dense(units = 7) %>% layer_activation(activation = 'relu') %>% layer_dense(units = 1, activation = 'sigmoid') model %>% compile( loss = 'binary_crossentropy', optimizer = optimizer_sgd(lr = 0.05), metrics = c('accuracy') ) model %>% fit(x_train, y_train, epochs = 5, batch_size = 100) px <- seq(-4, 4, 0.03) py <- seq(-4, 4, 0.03) x_test <- expand.grid(px, py) x_test <- as.matrix(x_test) pred_class <- model %>% predict(x_test, batch_size = 100) pred_class <- round(pred_class, 0) plot(d[, -3], col = c(rep(1, 50000), rep(2, 50000)), pch = 19, cex = 0.2, xlim = c(-4, 4), ylim = c(-4, 4), main = "DNN: Large dataset") par(new = T) contour(px, py, array(pred_class, dim = c(length(px), length(py))), xlim = c(-4, 4), ylim = c(-4, 4), levels = 0.5, drawlabels = F, col = 'purple', lwd = 5) unfreeze_weights(model, from = 2) # Small dataset: fine-tuned d <- read.csv('https://github.com/ozt-ca/tjo.hatenablog.samples/raw/master/r_samples/public_lib/jp/xor_complex_small.txt', header = T, sep = ' ') x_train <- as.matrix(d[, -3]) y_train <- as.matrix(d[, 3]) - 1 model %>% fit(x_train, y_train, epochs = 5, batch_size = 5) px <- seq(-4, 4, 0.03) py <- seq(-4, 4, 0.03) x_test <- expand.grid(px, py) x_test <- as.matrix(x_test) pred_class <- model %>% predict(x_test, batch_size = 100) pred_class <- round(pred_class, 0) plot(d[, -3], col = c(rep(1, 50), rep(2, 50)), pch = 19, cex = 2, xlim = c(-4, 4), ylim = c(-4, 4), main = "DNN: Small dataset with fine-tuning") par(new = T) contour(px, py, array(pred_class, dim = c(length(px), length(py))), xlim = c(-4, 4), ylim = c(-4, 4), levels = 0.5, drawlabels = F, col = 'purple', lwd = 5) rm(model) # Small dataset: raw model d <- read.csv('https://github.com/ozt-ca/tjo.hatenablog.samples/raw/master/r_samples/public_lib/jp/xor_complex_small.txt', header = T, sep = ' ') x_train <- as.matrix(d[, -3]) y_train <- as.matrix(d[, 3]) - 1 library(keras) model <- keras_model_sequential() model %>% layer_dense(units = 5, input_shape = 2) %>% layer_activation(activation = 'relu') %>% layer_dense(units = 7) %>% layer_activation(activation = 'relu') %>% layer_dense(units = 1, activation = 'sigmoid') model %>% compile( loss = 'binary_crossentropy', optimizer = optimizer_sgd(lr = 0.05), metrics = c('accuracy') ) model %>% fit(x_train, y_train, epochs = 5, batch_size = 5) px <- seq(-4, 4, 0.03) py <- seq(-4, 4, 0.03) x_test <- expand.grid(px, py) x_test <- as.matrix(x_test) pred_class <- model %>% predict(x_test, batch_size = 5) pred_class <- round(pred_class, 0) plot(d[, -3], col = c(rep(1, 50), rep(2, 50)), pch = 19, cex = 2, xlim = c(-4, 4), ylim = c(-4, 4), main = "DNN: Small dataset without fine-tuning") par(new = T) contour(px, py, array(pred_class, dim = c(length(px), length(py))), xlim = c(-4, 4), ylim = c(-4, 4), levels = 0.5, drawlabels = F, col = 'purple', lwd = 5)
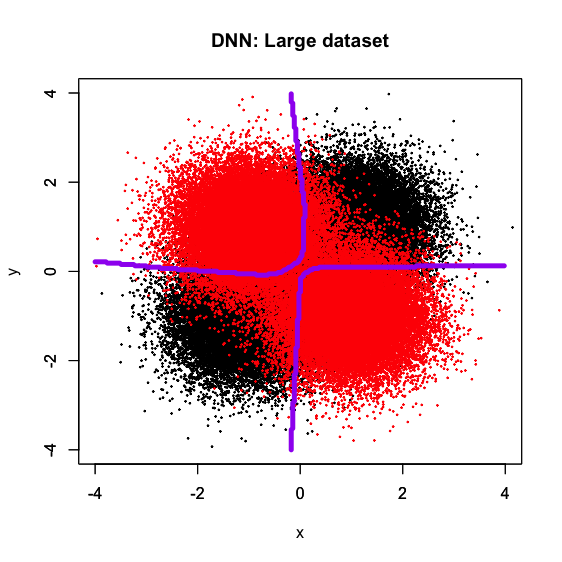
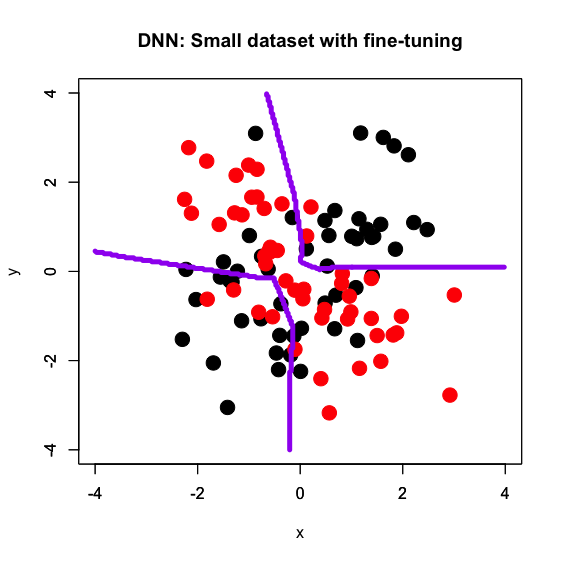
一目瞭然ですね。1枚目は前回の記事同様に大サンプルサイズのデータセットで学習させたDNNで決定境界を描いたもので、真の決定境界に近い十字型の線になっています。ここで得られたモデルの2層目以降の重み付けを小サンプルサイズのデータセットで再学習させ、決定境界を描いたのが2枚目で、確かに1枚目の影響を受けてかなり綺麗な十字型の決定境界が得られています。
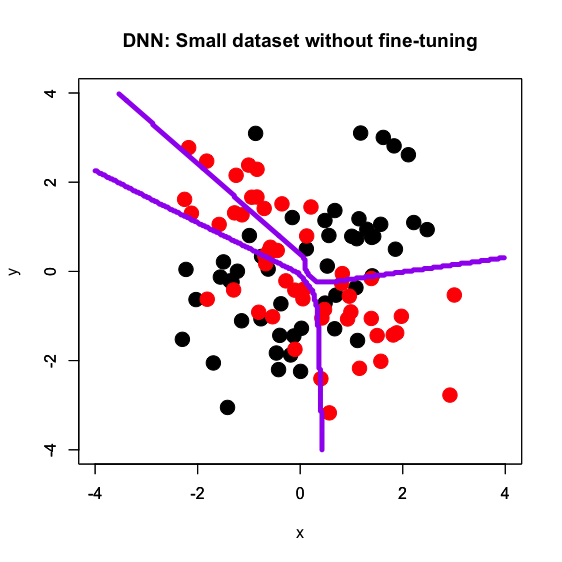
これに対して、前回の記事でもやったようにゼロから小サンプルサイズのデータセットで学習させたDNNで決定境界を描いたのが3枚目で、ランダムシードにもよりますが*5惨憺たる有様となっています。
ということで、R版Kerasでfine-tuningする方法が分かったので実践してみたらちゃんと動きましたよ、というただの備忘録でした。もしかしたらこの備忘録を踏まえた記事が今後出るかもしれませんので、気長にお待ちくだされば幸いです。
*1:「俺たちは雰囲気でfine-tuningをやっている」(画像略)
*2:実は以前TF-Hub関連の記事を書いていた頃はこの辺の差異を意識していなかった
*3:具体的にはpp.258-260を参照のこと
*4:当然ながらKerasは元々Pythonで動くものなのでPython側には多数のリソースがある
*5:なのでたまに上手くいく